Абстрактні типи даних для початківців


“У комп’ютерній науці всі проблеми можуть бути вирішені за допомогою додаткового рівня непрямості,” – Девід Вілер
Типи даних – це природно
Людина є істотою з дуже розвиненим образним мисленням. Саме наша здатність до створення абстракцій та узагальнення прожитого досвіду стала ключем до розвитку цивілізації. Ми користуємося цими здібностями від народження, навіть не замислюючись. Наприклад, ми з дитинства працюємо з різними типами даних, діючи швидше інтуїтивно, не даючи їм формального опису. Ми знаємо, що числа можна складати і множити, а зі слів складати речення. Навряд чи нам спаде на думку спробувати перемножувати слова. Таким чином, ми розуміємо, коли бачимо написані символи (літери, наприклад), що ми можемо і чого не можемо робити з цими символами, а також знаємо набір допустимих значень символів — наш алфавіт. У прикладі літери — і є тип даних. Ми знаємо безліч значень літер — вони є алфавітом. Крім того, знаємо, що літери ми можемо складати слова – це операції. Це природне уявлення людини лягло основою формального визначення типу даних.
Тип даних – безліч значень та [допустимих] операцій над цими значеннями.
Хоча ми в житті не використовуємо це визначення і навіть не замислюємося про це, кожен день ми стикаємося з різними типами даних: літери, цифри, предмети побуту, продукти харчування. Але навіть при вирішенні побутових питань може виникнути ситуація, коли наявних у розпорядженні простих типів даних може бути недостатньо.
Уявіть собі такий діалог матері та маленького сина років трьох, який ще не дуже освоїв абстрактне мислення:
— Синку, принеси, будь ласка, зі столу ручку, мені треба записати щось!
– Мамо, тут немає ручки!
– Тоді олівець.
– І олівця немає.
– А що є?
— Фломастери є й маркер.
– Ну, тоді неси фломастер!
Доросла людина швидше за все відразу принесла б фломастер і сказала: «ручки не було, думаю, фломастер пригодиться». Чому? — Тому що з якогось рівня розвитку абстрактного мислення та вміння взаємодіяти з іншими людьми людина вже розуміє, що в цьому проханні головне не конкретний тип об’єкта — ручка — а її властивість писати по папері. Таку ж властивість мають й інші об’єкти: олівці, фломастери, маркери, навіть шматочок вугілля. Таким чином, він машинально поєднує кілька типів інструментів в один тип: те, чим можна писати. Це вміння часто спрощує нам повсякденне життя та спілкування з оточуючими, при цьому дещо віддаляючи нас від конкретних фізичних об’єктів. Щоб дістатися роботи, ми використовуємо «громадський транспорт» — маршрути та конкретні вагони чи машини можуть бути різними, але головне, що вони мають потрібні нам властивості: ми можемо увійти, вийти, сплатити за проїзд, ми заздалегідь впевнені в тому, що це можна зробити з кожним з об’єктів цього типу. Коли ми в незнайомому місті хочемо сходити в кафе, ми запитуємо у друзів або в інтернеті: «де в місті Н можна смачно поїсти?», тобто ми не визначаємо конкретний заклад, навіть його тип, а ставимо в основу найважливішу властивість групи закладів: ми можемо прийти туди та замовити їжу.
Іншими словами, у деяких ситуаціях нам важливий не об’єкт конкретного типу, а певні його властивості: тобто, що ми можемо з ним робити. Часто шуканими властивостями володіють кілька типів даних, і всі вони нам так чи інакше підійдуть, як описані вище приклади. Це призводить до визначення абстрактного типу даних. Спочатку наведемо формальне визначення, а потім розкриємо його у більш простих термінах.
Абстрактний тип даних (АТД) – це математична модель для типів даних, де тип даних визначається поведінкою (семантикою) з точки зору користувача даних, а саме в термінах можливих значень, можливих операцій над даними цього типу та поведінки цих операцій.
Що таке математична модель? Хто такий користувач даних? Що мають на увазі під поведінкою операцій? Навіщо взагалі так ускладнювати? Давайте розумітися.
Заглиблюємося в деталі та розбираємо приклади
Щоб не перевантажувати себе новою інформацією, давайте будемо під математичною моделлю об’єкта або явища розуміти просто його формальний опис. Повертаючись, наприклад, з мамою, якій знадобилася ручка, ми можемо переробити її прохання в такий спосіб: «Сину, принеси мені, будь ласка, якийсь інструмент, який може залишати контрастні сліди на папері і при цьому поміщається до мене в руку». Звучить на побутовому рівні досить абсурдно, але саме це і буде формальним описом того, що знадобилося мамі.
Рухаємось далі. Уявімо програміста, перед яким стоїть завдання створення системи електронної черги в травмпункті.
При надходженні до травмпункту людині видається талон з номером (порядковим номером відвідувача травмпункту) та визначається пріоритетність черги: його травма оцінюється за шкалою від 1 до 10, де 10 – травма, яка потребує негайної медичної допомоги. Необхідно реалізувати механізм додавання людини до черги та визначення наступного пацієнта на прийом.
Для вирішення такого завдання потрібно створити програму, яка використовуватиме в коді деякі дані: номери талонів та їх пріоритети. У коді програми будуть проводитись операції над даними. Як ви побачите далі, ці операції не завжди прості, а можуть містити в собі безліч дій, а також мати деякі наслідки для всієї програми і всіх даних, що зберігаються: важкий пацієнт посуне всю чергу назад, тому що йому потрібна термінова медична допомога. Все в сукупності: набори операцій, дії, з яких вони складаються, а також їх наслідки називаються поведінкою операції.
Під користувачем даних ми в цій статті розумітимемо програміста, який використовує ці типи даних у своєму коді.
Залишається найважливіше питання: навіщо все це потрібне? Щоб відповісти на нього, розглянемо завдання докладніше.
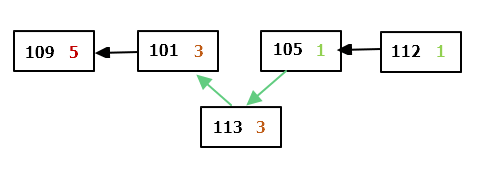
Уявимо, що у черзі вже є талони з номерами 109, 101, 105, 112 з пріоритетами 5, 3, 1, 1 відповідно. Наступному пацієнту видається талон 113 з пріоритетом 3. Тоді цей талон «обходить» номери 105 і 112, тому що їхній пріоритет нижче, і встає позаду талона 101, з яким їх пріоритети рівні (мал. 1). Коли лікар готовий прийняти наступного пацієнта, то буде викликано пацієнта з номером 109 (мал. 2).



Давайте напишемо код, який реалізує цю логіку. Будемо використовувати мову javascript . Спочатку опишемо звичайну чергу, без урахування пріоритету. Створимо клас PriorityQueue. Об’єкти цього класу міститимуть спочатку порожній масив data(створюється в конструкторі). Функція add_elemдодаватиме переданий їй параметр – номер талона – в кінець масиву data, а функція get_nextописуватиме виклик лікарем пацієнта на прийом: повертати значення першого елемента в масиві – номер пацієнта, який встав у чергу раніше за всіх інших, видаляючи з масиву цей елемент, так як , вирушаючи прийом, пацієнт залишає чергу. Також визначимо функцію print_que, яка виводитиме в консоль усі елементи черги по порядку.
class PriorityQueue{
constructor(){ this.data = []; }
add_elem(e){ this.data.push(e); }
get_next() { return this.data.shift() }
print_queue() {
for(var i in this.data)
console.log(this.data[i]);
}
};Наведемо приклад використання цього класу у коді програми:
Q = new PriorityQueue();
Q.add_elem(105);
Q.add_elem(101);
Q.add_elem(109);
console.log("next:",Q.get_next()) // next: 105
console.log("remains:")
Q.print_queue(); // 101 109Давайте модифікуємо клас, що вийшов, щоб черга враховувала пріоритет елемента. Для цього будемо в масиві dataзберігати не просто переданий елемент, а об’єкт із двома полями: значення ( value) та пріоритет ( priority). У коді такий об’єкт задаватиметься виразом виду var obj = {‘priority’: 1, ‘value’: 112};Перепишемо функцію додавання елемента в чергу:
add_elem(e,p) {
for (var i = this.data.length - 1; i >= 0; i--) {
if(this.data[i].priority >= p){
this.data.splice(i+1,0,{'value':e, 'priority':p});
return;
}
}
this.data.splice(0,0,{'value':e, 'priority':p});
}Змоделюємо ситуацію, проілюстровану малюнками 1 і 2.
Q = new PriorityQueue();
Q.add_elem(109,5);
Q.add_elem(101,3);
Q.add_elem(105,1);
Q.add_elem(112,1);
Q.add_elem(113,3);
console.log("next:",Q.get_next()) // next: { value: 109, priority: 5 }
console.log("remains:")
Q.print_queue(); // value: 101, priority: 3 }
//{ value: 113, priority: 3 }
//{ value: 105, priority: 1 }
//{ value: 112, priority: 1 }Можлива модифікація: якщо пацієнт перебуває в черзі протягом тривалого часу, наприклад, за цей час лікар уже прийняв як мінімум одного пацієнта з черги, то пріоритет його талона підвищується на 1, проте не може перевищити 8, щоб залишити можливість термінового прийому важких хворих.
Для цього змінимо функцію вибору наступного елемента get_next.
get_next() {
var e = this.data.shift();
for(var i in this.data){
if(this.data[i].priority<8)
this.data[i].priority++;
}
return e;
}Можемо помітити, що в даному випадку при вилученні елемента з черги змінюються всі елементи. Це і буде та сама «поведінка операції», про яку йшлося раніше.
Код програми, що вийшов, можна умовно розділити на дві частини: опис класу PriorityQueue і використання цього класу. Зауважимо, що використання класу виглядає досить лаконічно, порівняно з його описом. Працюючи з класом та її функціями програміст, який виступає у разі як користувач класу, може мати уявлення, як саме реалізована логіка роботи всередині функцій класу. Для його роботи достатньо того, що ця логіка відповідає заявленому опису пріоритетної черги. У такому разі кажуть, що клас реалізує певний інтерфейс – набір методів роботи з класом, де зафіксовано вхідні та вихідні параметри. У цьому прикладі це методи add_elem, get_next і print_queue. Можна змінити внутрішню логіку роботи цих методів, якщо цього вимагатиме завдання, як це було у разі підвищення пріоритету при довгому очікуванні. Однак для користувача класу ці зміни не будуть помітними і не вимагатимуть зміни коду основної програми.
Бонус. Що таке структура даних?
У програмуванні також є поняття структури даних, яке певною мірою близьке за змістом типу даних.
У чому різниця? Структура даних – це конкретна програмна реалізація типу даних. Якщо двох людей попросити реалізувати пріоритетну чергу, швидше за все навіть при використанні однієї мови програмування їх реалізації відрізнятимуться, хоча обидві відповідатимуть заявленому інтерфейсу. Тобто вони створять дві різні структури даних.
Структура даних (англ. data structure) — програмна одиниця, що дозволяє зберігати та обробляти безліч однотипних та/або логічно пов’язаних даних у обчислювальній техніці. Для додавання, пошуку, зміни та видалення даних структура даних надає деякий набір функцій, що становлять її інтерфейс.
Висновок
Підіб’ємо підсумки виконаної роботи. Клас PriorityQueueмає такі властивості:
- Він може зберігати у собі будь-які елементи з пріоритетом, який задається числом.
- Визначено інтерфейс взаємодії з класом: методи
add_elem,get_nextіprint_queue. - Описані методи реалізують заявлену логіку роботи пріоритетної черги.
- Методи мають певну поведінку (див., наприклад, бонус).
Таким чином, ми створили свій абстрактний тип даних та реалізували його мовою javascript . Що ми від цього виграли:
- Код основної програми лаконічний і зрозумілий, тому що не містить технічних подробиць внутрішньої роботи черги.
- Зручно вносити зміни до логіки роботи черги, не торкаючись основного коду.
- Клас
PriorityQueueможе бути перевикористаний в інших програмах, де потрібна схожа логіка. - У разі командної роботи можна поділити між людьми роботу над класом та розробку з використанням цього класу. Сполучною ланкою буде інтерфейс класу.
Незважаючи на те, що розробка абстрактного типу даних сама по собі може бути досить трудомісткою, використання АТД здорово допомагає заощадити сили і час при роботі зі складними завданнями. Принцип «розділяй і владарюй» працює тут якнайкраще: створення додаткового рівня абстракції допомагає розробнику розбити складне завдання на дрібніші і простіші, а його колегам спрощує розуміння коду програми, що надзвичайно важливо в командній розробці.
Звичайно, АТД – це не панацея, яка допоможе зробити будь-який код прекрасним, читаним і зрозумілим, уникнувши всіх помилок. Дуже часто навіть досвідчені програмісти у своєму прагненні зробити все правильно та красиво заходять надто далеко в нетрі абстракцій, що навпаки все ускладнює. Коли варто створювати нову абстракцію, а коли це зайве, зрозуміти можна лише з досвідом. Універсального рецепта немає, можна лише порадити намагатися періодично переглядати свій старий код, щоб зробити висновки, що з написаного робить його зрозумілішим, а що через деякий час незрозуміло вже навіть вам самим.
Пам’ятайте, що у висловлювання Девіда Віллера і є і друга, менш відома частина:
У комп’ютерній науці всі проблеми можна вирішити з допомогою додаткового рівня непрямості. Але зазвичай це створює іншу проблему