Effect для TypeScript-розробників: що це і як використовувати?

Сучасний TypeScript-розробник має в своєму арсеналі безліч інструментів для побудови надійних і масштабованих додатків. Одним із новітніх та перспективних підходів до управління ефектами та асинхронними операціями є Effect — потужна функціональна бібліотека, яка допомагає керувати побічними ефектами, обробкою помилок та конкурентним виконанням коду.
У цій статті ми розглянемо, що таке Effect, які його ключові можливості та як його можна застосовувати в реальних TypeScript-проєктах.
Що таке Effect?
Effect — це функціональна бібліотека для TypeScript, яка дозволяє писати надійний та безпечний код без використання класичних try/catch та складних структур керування потоками.
Ця бібліотека надає:
- Безпечне виконання ефектів (запити до API, доступ до бази даних, взаємодію з файловою системою).
- Композицію ефектів, що дозволяє легко комбінувати та керувати ними.
- Обробку помилок без
try/catch.
- Функціональний підхід для декларативного програмування.
Чому варто використовувати Effect у TypeScript?
✅ 1. Безпечне виконання асинхронного коду
Замість async/await і try/catch, Effect надає більш декларативний спосіб керування асинхронними операціями.
✅ 2. Потужний механізм обробки помилок
Effect дозволяє працювати з помилками без try/catch, використовуючи функціональний підхід.
✅ 3. Легка композиція
Ви можете об’єднувати ефекти в ланцюжки, що робить код читабельнішим і легшим для тестування.
✅ 4. Покращене тестування
Оскільки Effect дозволяє контролювати ефекти без реального виконання коду, його легше тестувати.
Встановлення Effect
Почнемо з установки бібліотеки:
npm install @effect/io
Effect не вимагає жодних спеціальних конфігурацій, тож після встановлення ви можете одразу його використовувати.
Основи роботи з Effect
1. Створення простого ефекту
Effect дозволяє легко описувати ефекти, які виконуються асинхронно.
import { Effect } from "@effect/io/Effect";
const greet = Effect.succeed("Привіт, TypeScript!");
greet.runPromise().then(console.log);
У цьому прикладі:
Effect.succeed(value) — створює ефект, який просто повертає значення..runPromise() — запускає ефект як проміс.
2. Робота з асинхронними запитами
Effect чудово підходить для роботи з API-запитами.
import { Effect } from "@effect/io/Effect";
const fetchData = Effect.tryPromise(() =>
fetch("https://jsonplaceholder.typicode.com/todos/1").then((res) => res.json())
);
fetchData.runPromise().then(console.log);
Effect.tryPromise використовується для обробки промісів без try/catch.
3. Обробка помилок
Вбудована обробка помилок в Effect дозволяє уникати try/catch.
const fetchWithError = Effect.tryPromise(() =>
fetch("https://invalid-url.com").then((res) => {
if (!res.ok) throw new Error("Помилка завантаження");
return res.json();
})
).catchAll((error) => Effect.succeed(`Помилка: ${error.message}`));
fetchWithError.runPromise().then(console.log);
Як це працює:
tryPromise() — виконує проміс..catchAll() — обробляє помилку та повертає альтернативне значення.
4. Комбінування ефектів
Effect дозволяє легко комбінувати кілька ефектів.
const effect1 = Effect.succeed("Дані з першого ефекту");
const effect2 = Effect.succeed("Дані з другого ефекту");
const combined = effect1.zip(effect2);
combined.runPromise().then(console.log);
Метод .zip() використовується для об’єднання двох ефектів.
5. Ланцюжкові операції (flatMap)
Ви можете створювати послідовні операції, подібні до async/await.
const fetchAndProcess = fetchData.flatMap((data) =>
Effect.succeed(`Отримані дані: ${JSON.stringify(data)}`)
);
fetchAndProcess.runPromise().then(console.log);
Тут .flatMap() використовується для обробки результату першого ефекту перед передачею його в наступний.
6. Робота з потоками (Streams)
Якщо ваш додаток обробляє великі обсяги даних, Effect має потужний модуль потоків.
import { Stream } from "@effect/io/Stream";
const numberStream = Stream.fromIterable([1, 2, 3, 4, 5])
.map((n) => n * 2)
.runCollect();
numberStream.then(console.log);
Effect vs. Звичайний TypeScript-код
| Функція |
async/await |
Effect |
| Обробка помилок |
try/catch |
.catchAll() |
| Керування асинхронними операціями |
Promise.all() |
.zip() або .flatMap() |
| Композиція ефектів |
Ланцюжки промісів |
Декларативне об’єднання |
| Тестування |
Складніше |
Легко мокати ефекти |
Effect надає декларативний та безпечний підхід до управління побічними ефектами, що значно покращує якість коду.
Коли використовувати Effect?
Effect корисний у таких випадках:
- Обробка асинхронних запитів (API, база даних).
- Керування складними ефектами (файлова система, потоки даних).
- Забезпечення надійності (написання безпечного TypeScript-коду).
- Покращене тестування (імітація ефектів у тестах).
Висновок
Effect — це потужний інструмент для TypeScript-розробників, який дозволяє спростити роботу з асинхронним кодом, покращити обробку помилок і зробити програму більш стабільною та тестованою. Хоча на перший погляд він може здатися складним, його переваги роблять його відмінним вибором для великих TypeScript-проєктів.
Якщо ви хочете створювати більш безпечний, надійний і масштабований код у TypeScript, обов’язково спробуйте Effect у своєму наступному проєкті!
Впровадження біометричної автентифікації в React Native для мобільних додатків

Біометрична автентифікація стала важливою частиною сучасних мобільних додатків, забезпечуючи зручний та безпечний спосіб авторизації. Завдяки React Native розробники можуть легко додавати цю функціональність як на iOS, так і на Android, використовуючи одну кодову базу. У цій статті ми розглянемо, як впровадити біометричну автентифікацію в React Native, які інструменти для цього потрібні та які нюанси слід врахувати.
Що таке біометрична автентифікація?
Біометрична автентифікація використовує унікальні фізичні характеристики користувача (відбитки пальців, розпізнавання обличчя) для підтвердження його особи. Це дозволяє зробити процес авторизації швидшим, зручнішим і безпечнішим, ніж використання паролів.
Переваги біометричної автентифікації:
- Безпека: Біометричні дані неможливо забути чи вгадати.
- Швидкість: Авторизація займає всього кілька секунд.
- Зручність: Користувачам не потрібно запам’ятовувати складні паролі.
Що потрібно для впровадження біометричної автентифікації в React Native?
Для роботи з біометрією в React Native можна використовувати бібліотеки, які забезпечують доступ до нативного функціоналу пристрою. Найпопулярніші з них:
- react-native-biometrics: Бібліотека для роботи з біометрією (відбитки пальців, Face ID).
- expo-local-authentication: Якщо ви використовуєте Expo, ця бібліотека надає простий спосіб інтеграції біометрії.
- react-native-touch-id: Проста у використанні бібліотека для Touch ID та Face ID.
Впровадження біометрії з react-native-biometrics
1. Встановлення бібліотеки
Щоб додати підтримку біометрії, спочатку встановимо бібліотеку:
npm install react-native-biometrics
Після цього виконайте лінкування (для тих, хто не використовує автолінкування в React Native):
npx react-native link react-native-biometrics
2. Налаштування на iOS
У iOS потрібно додати дозволи в файл Info.plist:
<key>NSFaceIDUsageDescription</key>
<string>Ця функція потрібна для біометричної автентифікації</string>
3. Налаштування на Android
Для Android біометрія працює з мінімальною версією SDK 23 (Android 6.0). Переконайтеся, що ваш файл build.gradle має правильну версію:
minSdkVersion = 23
4. Реалізація біометричної автентифікації
Після налаштування середовища можна додати біометричну автентифікацію до додатка.
Ось приклад базової реалізації:
import React from 'react';
import { View, Button, Text, Alert } from 'react-native';
import ReactNativeBiometrics from 'react-native-biometrics';
const rnBiometrics = new ReactNativeBiometrics();
const App = () => {
const handleBiometricAuth = async () => {
const { available, biometryType } = await rnBiometrics.isSensorAvailable();
if (!available) {
Alert.alert('Біометрія недоступна');
return;
}
if (biometryType === ReactNativeBiometrics.FaceID) {
Alert.alert('Face ID доступний');
} else if (biometryType === ReactNativeBiometrics.TouchID) {
Alert.alert('Touch ID доступний');
} else if (biometryType === ReactNativeBiometrics.Biometrics) {
Alert.alert('Загальна біометрія доступна');
}
const { success } = await rnBiometrics.simplePrompt({
promptMessage: 'Підтвердіть вашу особу',
});
if (success) {
Alert.alert('Авторизація пройшла успішно!');
} else {
Alert.alert('Авторизація не вдалася');
}
};
return (
<View style={{ flex: 1, justifyContent: 'center', alignItems: 'center' }}>
<Button title="Увійти за допомогою біометрії" onPress={handleBiometricAuth} />
</View>
);
};
export default App;
Як це працює?
isSensorAvailable() — перевіряє, чи підтримує пристрій біометричну автентифікацію.simplePrompt() — викликає діалогове вікно для підтвердження біометрії.biometryType — визначає тип доступної біометрії (Face ID, Touch ID або інша).
Впровадження біометрії з Expo (expo-local-authentication)
Expo пропонує готову бібліотеку expo-local-authentication, яка спрощує процес інтеграції біометрії.
1. Встановлення бібліотеки
expo install expo-local-authentication
2. Реалізація біометричної автентифікації
Приклад роботи з бібліотекою:
import React from 'react';
import { View, Button, Text, Alert } from 'react-native';
import * as LocalAuthentication from 'expo-local-authentication';
const App = () => {
const handleBiometricAuth = async () => {
const isCompatible = await LocalAuthentication.hasHardwareAsync();
if (!isCompatible) {
Alert.alert('Пристрій не підтримує біометрію');
return;
}
const isEnrolled = await LocalAuthentication.isEnrolledAsync();
if (!isEnrolled) {
Alert.alert('Біометричні дані не налаштовані');
return;
}
const result = await LocalAuthentication.authenticateAsync({
promptMessage: 'Увійдіть за допомогою біометрії',
});
if (result.success) {
Alert.alert('Авторизація успішна!');
} else {
Alert.alert('Авторизація не вдалася');
}
};
return (
<View style={{ flex: 1, justifyContent: 'center', alignItems: 'center' }}>
<Button title="Увійти за допомогою біометрії" onPress={handleBiometricAuth} />
</View>
);
};
export default App;
Кращі практики для біометричної автентифікації
- Перевірка доступності: Завжди перевіряйте, чи пристрій підтримує біометрію.
- Альтернативна автентифікація: Додайте резервний спосіб входу (наприклад, PIN-код).
- Чітке повідомлення: Використовуйте зрозумілі підказки у діалогових вікнах.
- Безпечне зберігання даних: Використовуйте такі технології, як SecureStore для збереження токенів чи конфіденційної інформації.
Висновок
Впровадження біометричної автентифікації у React Native дозволяє підвищити рівень безпеки та зручності мобільних додатків. Завдяки бібліотекам, таким як react-native-biometrics чи expo-local-authentication, цей процес стає максимально простим і доступним. Якщо ви прагнете створити додаток, який відповідає сучасним вимогам безпеки, біометрія — це важливий інструмент у вашому арсеналі.
Успішна інтеграція біометрії зробить ваш додаток привабливішим для користувачів та покращить їхній досвід.
Нові можливості ECMAScript: атрибути імпорту та модифікатори шаблону регулярного вираження

ECMAScript (ES) — це стандарт, на основі якого розробляється JavaScript. Щороку стандарт оновлюється, додаючи нові функції, що роблять код сучаснішим, ефективнішим і простішим. Одна з останніх новинок ECMAScript — це атрибути імпорту та модифікатори шаблону регулярного вираження. У цій статті ми розглянемо, що це за функції, як вони працюють та як їх можна використовувати у ваших проєктах.
Атрибути імпорту (Import Attributes)
Що таке атрибути імпорту?
Атрибути імпорту — це новий функціонал ECMAScript, який дозволяє передавати додаткові параметри під час імпорту модулів. Вони відкривають можливість задавати специфічні властивості для імпорту, що особливо корисно для роботи з JSON або іншими статичними файлами.
Навіщо вони потрібні?
У стандартному імпорті JavaScript завжди була жорстка структура. Наприклад, якщо ми імпортуємо JSON-файл, браузер або середовище виконання (наприклад, Node.js) автоматично інтерпретує цей файл як текст або об’єкт без можливості налаштувати спосіб його обробки. Атрибути імпорту дають більше контролю над процесом імпорту.
Як це працює?
Раніше ви могли імпортувати JSON так:
import data from './data.json';
console.log(data);
З введенням атрибутів імпорту можна додавати спеціальні параметри для налаштування:
import data from './data.json' assert { type: 'json' };
console.log(data);
Розбір прикладу:
assert { type: 'json' } — це атрибут імпорту, який вказує, що файл data.json слід інтерпретувати як JSON.- Якщо тип вказано неправильно або він не підтримується, імпорт видасть помилку.
Переваги атрибутів імпорту
- Більше контролю над імпортами: Ви можете чітко вказувати, як обробляти той чи інший файл.
- Безпека: Завдяки атрибутам, модуль або середовище виконання можуть перевіряти, чи імпортується файл у відповідному форматі.
- Гнучкість: Атрибути імпорту можуть використовуватися для розширення функціоналу, наприклад, для специфічних форматів даних у майбутньому.
Де це може бути корисним?
- Імпорт статичних ресурсів: Наприклад, імпорт зображень чи файлів CSS:
- Додаткова безпека: Якщо JSON-файл має бути строго визначений, атрибути імпорту гарантують правильність його інтерпретації.
- Модульність:
Розширені атрибути допомагають створювати більш кастомізовані імпортні сценарії для специфічних застосувань.
Модифікатори шаблону регулярного вираження
Що це таке?
Модифікатори регулярного вираження (Regular Expression Modifiers) — це доповнення до стандартного функціоналу регулярних виразів у JavaScript. Нові модифікатори дозволяють налаштовувати та адаптувати регулярні вирази для специфічних сценаріїв.
Нові модифікатори в ES12+
1. Модифікатор d (indices)
Цей модифікатор дозволяє отримати інформацію про позиції збігів у рядку.
Приклад:
const regex = /React/gd;
const match = regex.exec('I love React and React Native');
console.log(match.indices);
- Що робить
indices:
indices повертає масив із початковою та кінцевою позицією кожного збігу.- Це зручно, якщо вам потрібно працювати з підрядками або змінювати текст у рядку.
2. Модифікатор v (Unicode sets)
Цей модифікатор забезпечує підтримку нових уніфікованих наборів символів Unicode.
Приклад:
const regex = /\p{Script=Latin}/v;
console.log(regex.test('A'));
console.log(regex.test('Α'));
- Для чого використовується
v:
- Спрощує роботу з набором символів.
- Особливо корисно для програм, які працюють із багатомовним контентом.
Навіщо потрібні модифікатори?
- Гнучкість у роботі з текстом: Нові модифікатори дозволяють робити складні перевірки швидше та простіше.
- Оптимізація: Додаткові можливості регулярних виразів дозволяють уникати громіздких конструкцій.
- Підтримка сучасних стандартів: У світі, де Unicode є стандартом, модифікатори, такі як
v, спрощують роботу з різними мовами.
Порівняння старих і нових можливостей
| Функція |
Старий підхід |
Новий підхід |
| Імпорт JSON |
import data from './data.json'; |
import data from './data.json' assert { type: 'json' }; |
| Отримання позиції збігу |
Використання додаткового коду для обчислення індексів |
Використання d для автоматичного отримання індексів |
| Підтримка Unicode |
Складні конструкції для перевірки наборів символів |
Використання v для роботи з Unicode |
Чому ці нововведення важливі для розробників?
- Спрощення коду:
Нові можливості дозволяють уникнути написання складних обхідних рішень.
- Безпека:
Атрибути імпорту підвищують контроль над ресурсами, зменшуючи ймовірність помилок.
- Міжнародна підтримка:
Модифікатори регулярних виразів, як-от v, спрощують роботу з багатомовними проєктами.
Висновок
Нові функції ECMAScript, такі як атрибути імпорту та модифікатори шаблонів регулярних виразів, є важливими кроками до спрощення та покращення роботи з JavaScript. Вони дозволяють зменшити кількість коду, підвищують його читабельність і додають нові можливості для роботи з файлами та текстом.
Ці нововведення — це не лише технічні інструменти, а й новий рівень контролю для розробників, що дозволяє створювати більш стабільні, масштабовані та безпечні програми. Якщо ви ще не спробували ці функції, час їх додати до свого арсеналу інструментів!
Як створити свій мем-коїн і що для цього потрібно

Мем-коїни, такі як Dogecoin чи Shiba Inu, стали популярними не лише завдяки своїй інвестиційній привабливості, але й завдяки своїм комічним і соціальним аспектам. Створення власного мем-коїна може бути цікавим проєктом, який об’єднає спільноту чи навіть стане джерелом прибутку. У цій статті ми розглянемо, що потрібно для створення мем-коїна, які етапи включає цей процес і які технології необхідні для успішного запуску.
Що таке мем-коїн?
Мем-коїн — це криптовалюта, яка створена не лише з фінансовою метою, але й із акцентом на гумор, меми або інтернет-культуру. Зазвичай вони мають низьку вартість і великий обсяг в обігу, що робить їх доступними для широкої аудиторії.
Чому мем-коїни популярні?
- Простота входу: Їх легко купувати і продавати.
- Соціальний аспект: Спільноти мем-коїнів активно підтримують свої проєкти, використовуючи соцмережі для реклами.
- Диверсифікація: Мем-коїни часто використовуються для “жартівливих” інвестицій.
Що потрібно для створення мем-коїна?
Для створення власного мем-коїна необхідно врахувати три ключові аспекти:
- Технологічна база: Створення та розгортання смарт-контрактів.
- Ідея та позиціонування: Ваш коїн має виділятися завдяки унікальному концепту.
- Маркетинг і спільнота: Успіх мем-коїна залежить від залучення користувачів.
Кроки для створення мем-коїна
1. Визначте мету коїна
Перед тим як створити мем-коїн, вам потрібно зрозуміти, яку проблему чи ідею він має представляти.
- Приклад:
- Dogecoin створено як жарт на основі популярного мема.
- Shiba Inu орієнтується на екосистему з високою залученістю спільноти.
Запитайте себе:
- Чому ваш мем-коїн буде цікавий аудиторії?
- Яку унікальність він пропонуватиме?
2. Оберіть блокчейн-платформу
Створення мем-коїна потребує блокчейну, на якому він працюватиме. Найпоширеніші варіанти:
- Ethereum:
Підтримує створення токенів стандарту ERC-20. Легкий у використанні, але може мати високі комісії.
- Binance Smart Chain (BSC):
Альтернатива Ethereum із низькими комісіями та підтримкою токенів BEP-20.
- Solana:
Швидка та масштабована платформа з низькими комісіями.
- Polygon:
Рішення другого рівня для Ethereum із низькими комісіями.
3. Напишіть смарт-контракт
Смарт-контракт — це основа вашого мем-коїна. Він визначає кількість токенів, методи передачі, механізми спалювання тощо.
- Інструменти:
- Solidity: Для написання смарт-контрактів на Ethereum та BSC.
- Remix: Онлайн-редактор для створення та тестування смарт-контрактів.
Приклад простого смарт-контракту ERC-20:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
import "@openzeppelin/contracts/token/ERC20/ERC20.sol";
contract MemeCoin is ERC20 {
constructor() ERC20("MemeCoin", "MEME") {
_mint(msg.sender, 1000000 * 10 ** decimals());
}
}
- Пояснення:
ERC20: Стандарт для токенів.constructor: Функція, яка створює початкову кількість токенів.
4. Розгортання токена
Після написання смарт-контракту потрібно розгорнути його на обраній блокчейн-платформі.
- Отримайте криптовалюту для комісій:
Наприклад, ETH для Ethereum або BNB для Binance Smart Chain.
- Розгортання через Remix:
Використовуйте онлайн-інструмент для розгортання контракту.
- Підтвердження в блокчейні:
Після розгортання ви отримаєте адресу контракту, яку можна використовувати для взаємодії з токеном.
5. Створіть вебсайт і маркетингову стратегію
Мем-коїн без спільноти не має цінності. Тому важливо створити платформу для залучення користувачів.
- Що має бути на сайті?
- Інформація про коїн (мета, обсяг, блокчейн).
- Посилання на контракт.
- Інструкції щодо купівлі.
- Соцмережі та форуми:
Використовуйте Twitter, Reddit, Telegram для залучення спільноти.
- Запуск кампаній:
Організуйте розіграші, аірдропи чи конкурси для збільшення популярності.
6. Список на біржах
Ваш коїн має бути доступним для торгівлі. Ви можете додати його на децентралізовані біржі (DEX) або централізовані платформи.
- Децентралізовані біржі:
- Uniswap (Ethereum)
- PancakeSwap (BSC)
- Централізовані біржі:
- Малі біржі, які підтримують нові токени.
Переваги створення мем-коїна
- Швидкий запуск:
Створення токена займає лише кілька годин із правильними інструментами.
- Високий потенціал популярності:
Успішні мем-коїни можуть залучати велику спільноту.
- Інновації:
Мем-коїни дозволяють тестувати нові ідеї у сфері криптовалют.
Недоліки та ризики
- Висока конкуренція:
Серед тисяч мем-коїнів важко виділитися.
- Регуляторні обмеження:
Деякі юрисдикції можуть мати строгі вимоги щодо криптовалют.
- Можливі шахрайства:
Мем-коїни часто стають об’єктом Pump & Dump схем.
Поради для створення успішного мем-коїна
- Будьте оригінальними:
Унікальна ідея або тема приверне більше уваги.
- Фокусуйтеся на спільноті:
Залучайте користувачів через соцмережі та інтерактивність.
- Прозорість:
Публікуйте код контракту, щоб викликати довіру.
Висновок
Створення мем-коїна може бути цікавим і перспективним проєктом, якщо підійти до цього з правильною стратегією. Важливо не лише створити токен, але й побудувати навколо нього спільноту, що його підтримає. Успіх мем-коїна залежить від поєднання гумору, маркетингу та технічної надійності.
Тож, якщо у вас є ідея для нового мем-коїна, не бійтеся почати! Хто знає, можливо, саме ваш проєкт стане наступним Dogecoin або Shiba Inu.
Навіщо потрібний шаблон Render Props у React?

Якщо ви працюєте з React, ви, напевно, чули про різні шаблони проєктування (design patterns), які допомагають будувати гнучкі та масштабовані компоненти. Один із таких шаблонів — Render Props. Він дозволяє зробити ваші компоненти більш універсальними та легко кастомізованими, вирішуючи багато завдань, пов’язаних із повторним використанням логіки. У цій статті ми розглянемо, що таке Render Props, навіщо він потрібний і як його правильно використовувати.
Що таке Render Props?
Render Props — це шаблон, за яким компонент використовує функцію, передану через пропси, для динамічного рендерингу контенту. По суті, це спосіб ділитися логікою між компонентами, передаючи функцію, яка повертає JSX.
Формальне визначення:
Render Props — це пропс, значенням якого є функція. Ця функція дозволяє компоненту динамічно управляти тим, що буде відображатися.
Приклад Render Props:
const DataFetcher = ({ render }) => {
const data = ['React', 'Vue', 'Angular'];
return (
<div>
{render(data)}
</div>
);
};
function App() {
return (
<DataFetcher
render={(data) => (
<ul>
{data.map((item, index) => (
<li key={index}>{item}</li>
))}
</ul>
)}
/>
);
}
У цьому прикладі компонент DataFetcher відповідає за отримання даних, але вигляд контенту визначається у render-функції, яку передає App.
Навіщо потрібний Render Props?
Render Props вирішує одну з ключових проблем у React — повторне використання логіки між компонентами, яка не залежить від їхнього відображення. Ось кілька основних причин використовувати Render Props:
1. Уникнення дублювання коду
Коли логіка використовується у багатьох компонентах, можна створити окремий компонент із Render Props для повторного використання.
Приклад: Замість копіювання коду для роботи з вікном перегляду (viewport), ви можете створити універсальний компонент:
const Viewport = ({ render }) => {
const [width, setWidth] = React.useState(window.innerWidth);
React.useEffect(() => {
const handleResize = () => setWidth(window.innerWidth);
window.addEventListener('resize', handleResize);
return () => window.removeEventListener('resize', handleResize);
}, []);
return render(width);
};
function App() {
return (
<Viewport render={(width) => <p>Ширина вікна: {width}px</p>} />
);
}
2. Гнучкість у відображенні
З Render Props ви можете використовувати один і той самий компонент із різними способами рендерингу.
Приклад:
const Counter = ({ render }) => {
const [count, setCount] = React.useState(0);
return (
<div>
<button onClick={() => setCount(count + 1)}>Збільшити</button>
{render(count)}
</div>
);
};
function App() {
return (
<Counter render={(count) => <h1>Лічильник: {count}</h1>} />
);
}
У цьому прикладі компонент Counter відповідає за лічильник, але вигляд контенту залежить від функції render.
Коли використовувати Render Props?
Render Props корисний, коли:
- Ви хочете розділити логіку та відображення.
- Вам потрібно використовувати одну й ту саму логіку в різних компонентах.
- Вам потрібна висока гнучкість для кастомізації компонентів.
Переваги Render Props
1. Універсальність
Render Props дозволяє створювати компоненти, які не залежать від конкретного дизайну.
2. Уникає дублювання коду
Ви можете повторно використовувати одну й ту саму бізнес-логіку в різних компонентах.
3. Висока кастомізація
З Render Props ви можете динамічно змінювати вигляд компонентів, не змінюючи їхню логіку.
Недоліки Render Props
- Перенавантаження коду (Boilerplate)
У великих проєктах шаблон Render Props може ускладнити читабельність через велику кількість вкладених функцій.
- Проблеми з продуктивністю
Кожна нова функція, передана як пропс, створює новий об’єкт у пам’яті, що може впливати на продуктивність.
- Альтернативи
Сучасні підходи, такі як hooks або Higher-Order Components (HOC), іноді краще підходять для розв’язання подібних задач.
Hooks як альтернатива Render Props
React-хуки, як-от useState, useEffect, useContext, дозволяють реалізовувати багато сценаріїв Render Props у більш елегантний спосіб.
Приклад з використанням Hook:
const useViewport = () => {
const [width, setWidth] = React.useState(window.innerWidth);
React.useEffect(() => {
const handleResize = () => setWidth(window.innerWidth);
window.addEventListener('resize', handleResize);
return () => window.removeEventListener('resize', handleResize);
}, []);
return width;
};
function App() {
const width = useViewport();
return <p>Ширина вікна: {width}px</p>;
}
Хуки часто вважаються більш зрозумілими та простими у використанні.
Коли Render Props все ще корисний
Render Props залишається корисним у випадках, коли:
- Ви працюєте з проєктом, де ще не можна використовувати хуки (наприклад, старі версії React).
- Вам потрібна гнучкість у побудові компонента, яка важко реалізується через HOC або хуки.
- Логіка компонента залежить від динамічного відображення, яке неможливо реалізувати через інші підходи.
Висновок
Шаблон Render Props — це потужний інструмент у арсеналі React-розробника, який дозволяє створювати гнучкі та універсальні компоненти. Хоча сучасні хуки часто використовуються як альтернатива, Render Props залишається актуальним для складних сценаріїв, які вимагають поділу логіки та відображення.
Якщо використовувати Render Props розумно, це допоможе зробити ваш код зрозумілішим, гнучкішим і зручнішим для підтримки. У той же час важливо враховувати його недоліки та розглядати альтернативи, такі як хуки чи HOC, залежно від ваших потреб.
Flutter vs React Native: Порівняння двох популярних інструментів для кросплатформної розробки

Сьогодні мобільні додатки є важливою частиною нашого життя, і розробники шукають інструменти, які дозволяють створювати якісні продукти швидше і з меншими витратами. Flutter та React Native є двома найпопулярнішими платформами для кросплатформної розробки, кожна з яких має свої переваги та недоліки. У цій статті ми детально порівняємо ці дві технології, щоб допомогти вам обрати оптимальний інструмент для вашого проєкту.
Що таке Flutter?
Flutter — це UI-фреймворк, створений Google, який дозволяє розробникам створювати нативні мобільні, веб- та десктоп-додатки з однієї кодової бази. Він використовує мову програмування Dart і надає багатий набір готових компонентів для створення красивих і швидких інтерфейсів.
Особливості Flutter:
- Власний рендеринг: Flutter рендерить UI за допомогою власного графічного движка, що забезпечує однаковий вигляд на всіх платформах.
- Hot Reload: Миттєве оновлення коду без перезапуску додатка.
- Широкі можливості кастомізації: Ви можете створювати унікальні дизайни, які будуть виглядати однаково на Android і iOS.
Що таке React Native?
React Native — це фреймворк для створення мобільних додатків, розроблений Facebook. Він базується на JavaScript і дозволяє використовувати React для створення інтерфейсів, які конвертуються у нативні компоненти.
Особливості React Native:
- Переваги JavaScript: Популярна мова програмування, яку знають багато розробників.
- Компонентна структура: Використання компонентів дозволяє повторно використовувати код.
- Екосистема: Величезна кількість бібліотек і модулів.
Flutter vs React Native: Порівняння
1. Мова програмування
- Flutter: Використовує Dart — мову програмування, розроблену Google. Dart досить простий для вивчення, особливо для розробників з досвідом роботи з Java або JavaScript.
- React Native: Базується на JavaScript, одній із найпопулярніших мов програмування у світі.
Висновок:
Якщо ваша команда вже знайома з JavaScript, то React Native може бути кращим вибором. Для нових проєктів, де є можливість вивчити Dart, Flutter є чудовою альтернативою.
2. Продуктивність
- Flutter: Завдяки власному графічному движку та використанню нативних бібліотек, Flutter забезпечує високу продуктивність і плавність роботи додатків.
- React Native: Хоча React Native використовує JavaScript, який працює через міст (bridge) для взаємодії з нативними модулями, його продуктивність може бути нижчою порівняно з Flutter.
Висновок:
Flutter зазвичай має перевагу у продуктивності, особливо для графічно інтенсивних додатків.
3. Можливості UI/UX
- Flutter: Завдяки власному рендерингу надає безліч кастомізованих компонентів. Дизайн виглядає однаково на всіх платформах.
- React Native: Використовує нативні компоненти платформи, що забезпечує справжній нативний вигляд і відчуття.
Висновок:
Якщо вам потрібна висока кастомізація UI, Flutter буде кращим вибором. Для додатків, які повинні виглядати максимально “рідними”, підходить React Native.
4. Екосистема та бібліотеки
- Flutter: Хоча Flutter має зростаючу спільноту і багато плагінів, його екосистема ще молода і може не мати всіх потрібних бібліотек.
- React Native: Величезна екосистема JavaScript і багаторічна підтримка роблять доступними тисячі бібліотек для будь-яких завдань.
Висновок:
React Native має більш розвинену екосистему, що може стати вирішальним фактором для великих проєктів.
5. Навчання та поріг входу
- Flutter: Вимагає вивчення Dart, що може бути новою мовою для багатьох розробників.
- React Native: JavaScript уже відомий багатьом, тому поріг входу значно нижчий.
Висновок:
Для новачків у мобільній розробці React Native може бути легшим стартом.
6. Hot Reload
- Flutter: Реалізований ідеально — дозволяє миттєво переглядати зміни у коді.
- React Native: Також підтримує hot reload, але він менш стабільний у порівнянні з Flutter.
7. Підтримка компаній і спільноти
- Flutter: Активно підтримується Google, що забезпечує стабільність і регулярні оновлення.
- React Native: Підтримується Facebook і має більшу спільноту завдяки своїй багаторічній історії.
Висновок:
Обидва інструменти активно підтримуються, але Flutter швидко набирає популярності завдяки інноваціям.
Для яких проєктів підходить кожен фреймворк?
- Flutter:
- Графічно інтенсивні додатки.
- Високий рівень кастомізації.
- Проєкти, орієнтовані на довгостроковий розвиток.
- React Native:
- Додатки, які потребують максимально нативного вигляду.
- Короткий час на розробку.
- Команди, знайомі з JavaScript.
Висновок
Flutter і React Native є чудовими інструментами для кросплатформної розробки, кожен із яких має свої переваги. Вибір залежить від ваших цілей, вимог до проєкту та рівня знань команди.
Якщо вам потрібна максимальна продуктивність і кастомізація — обирайте Flutter. Якщо ви шукаєте швидкий старт і розвинену екосистему — React Native стане оптимальним вибором.
Незалежно від вашого вибору, обидва інструменти дозволяють створювати високоякісні додатки, що відповідають потребам сучасного ринку.
Штучний інтелект для веб-розробки: майбутнє, яке вже настало

Штучний інтелект (ШІ) швидко змінює сучасний світ, і веб-розробка — не виняток. Завдяки інтеграції ШІ, веб-додатки стають розумнішими, швидшими та більш персоналізованими. Технології, що ще кілька років тому здавалися недосяжними, тепер доступні навіть невеликим командам розробників. У цій статті ми розглянемо, як ШІ змінює веб-розробку, які інструменти вже доступні, і що чекати у майбутньому.
Роль ШІ у веб-розробці
ШІ стає важливим інструментом для автоматизації, покращення продуктивності та створення інноваційних веб-рішень. Його вплив відчутний на всіх етапах розробки, від проєктування дизайну до оптимізації готового продукту.
Основні напрями використання ШІ у веб-розробці:
- Дизайн і прототипування:
Інструменти на базі ШІ спрощують створення UI/UX-дизайнів, аналізуючи найкращі практики і створюючи макети автоматично.
- Автоматизація кодування:
Завдяки ШІ, можна автоматично генерувати код, виправляти помилки та оптимізувати існуючі рішення.
- Оптимізація продуктивності:
ШІ аналізує швидкість роботи сайтів і пропонує способи її покращення.
- Персоналізація:
Інтелектуальні алгоритми дозволяють адаптувати контент під потреби користувачів у реальному часі.
- Безпека:
ШІ допомагає виявляти та запобігати кіберзагрозам, аналізуючи потенційні уразливості.
ШІ у веб-дизайні
ШІ змінює підхід до створення дизайнів. Інструменти автоматизації вже зараз можуть створювати сучасні, функціональні макети.
Інструменти для автоматизації дизайну:
- Figma з плагінами на базі ШІ:
Інструменти, як-от Autoflow, дозволяють автоматично створювати інтерактивні макети.
- Uizard:
Генератор дизайнів, що створює макети на основі текстових описів.
- Canva Design Suggestions:
ШІ підказує ідеї для оформлення і автоматично адаптує макети під різні розміри.
ШІ для генерації та оптимізації коду
Алгоритми ШІ можуть зменшити час, який розробники витрачають на написання та виправлення коду.
Інструменти для автоматизації кодування:
- GitHub Copilot:
Помічник для написання коду, який генерує фрагменти на основі введення користувача.
- TabNine:
Інструмент автодоповнення коду на основі штучного інтелекту.
- DeepCode (Snyk):
Аналізує код, знаходить помилки та пропонує виправлення.
Автоматизація рутинних задач
ШІ може автоматизувати завдання, наприклад, створення базових компонентів у React або генерацію API-запитів.
Приклад із GitHub Copilot:
function fetchUserData(userId) {
return fetch(`https://api.example.com/users/${userId}`)
.then(response => response.json())
.catch(error => console.error('Error:', error));
}
Персоналізація веб-додатків за допомогою ШІ
ШІ дозволяє створювати індивідуальний досвід для кожного користувача.
Застосування персоналізації:
- Рекомендаційні системи:
ШІ аналізує поведінку користувачів і пропонує їм релевантний контент.
Приклад: Рекомендація продуктів на основі попередніх покупок.
- Динамічний контент:
Алгоритми ШІ можуть змінювати текст, зображення та структуру сайту залежно від уподобань користувача.
Інструменти:
- Dynamic Yield: Платформа для персоналізації сайтів.
- Segment: Інструмент для збору даних і створення персоналізованого досвіду.
ШІ для забезпечення безпеки
Кібербезпека — це одна з найважливіших сфер застосування ШІ.
Як ШІ допомагає у безпеці:
- Виявлення загроз у реальному часі:
Алгоритми ШІ аналізують підозрілу активність і запобігають зломам.
- Виправлення уразливостей у коді:
Інструменти, як-от Snyk, знаходять потенційні загрози у бібліотеках і коді.
- Захист від DDoS-атак:
ШІ визначає ненормальну активність і блокує шкідливий трафік.
Приклад інструмента:
- Cloudflare Bot Management: Використовує ШІ для ідентифікації ботів і запобігання атакам.
Оптимізація продуктивності з ШІ
Швидкість завантаження та продуктивність сайту мають вирішальне значення для успішного веб-додатка.
Як ШІ допомагає:
- Аналіз продуктивності:
Інструменти, такі як Lighthouse від Google, використовують ШІ для оцінки швидкості сайту.
- Автоматичне оптимізування ресурсів:
ШІ може автоматично стиснути зображення, оптимізувати CSS та JavaScript.
Приклад:
- ImageKit: Інструмент для автоматичного стиснення та доставки зображень.
Майбутнє ШІ у веб-розробці
З розвитком технологій, роль ШІ у веб-розробці буде лише зростати. Серед потенційних напрямків:
- Повністю автоматизовані платформи: Інструменти, які зможуть створювати сайти за текстовим описом.
- Глибша інтеграція з голосовими помічниками: Розробка веб-додатків, які підтримують голосові команди.
- ШІ-дизайнери: Автоматичне створення UI/UX на основі поведінки користувачів.
Висновок
Штучний інтелект стає невід’ємною частиною веб-розробки, допомагаючи розробникам автоматизувати рутинні задачі, створювати інноваційні рішення та підвищувати безпеку. Хоча ШІ ще не може повністю замінити людину, його інтеграція значно покращує ефективність і якість веб-додатків.
Тому, якщо ви ще не використовуєте ШІ у своїй роботі, саме час ознайомитися з доступними інструментами і почати застосовувати їх для вирішення щоденних задач.
Як покращити безпеку JavaScript-коду: найкращі практики та поради

JavaScript є одним із найпоширеніших мов програмування для розробки веб-додатків. Завдяки своїй гнучкості та популярності, він став основою сучасного фронтенду та бекенду (Node.js). Однак JavaScript-код, якщо він не захищений належним чином, може стати об’єктом атак, таких як XSS (Cross-Site Scripting), CSRF (Cross-Site Request Forgery) або ін’єкції. У цій статті ми розглянемо найкращі практики для покращення безпеки JavaScript-коду.
Чому безпека JavaScript важлива?
- Доступність коду: JavaScript-код виконується у браузері користувача і, на відміну від серверного коду, легко доступний для аналізу.
- Висока популярність: Завдяки поширенню JavaScript він є основною ціллю для зловмисників.
- Частина клієнт-серверної архітектури: Помилки в JavaScript-коді можуть відкривати уразливості як на клієнтській, так і на серверній стороні.
Основні ризики для JavaScript-додатків
- Cross-Site Scripting (XSS):
Зловмисник може впровадити шкідливий код у ваш додаток, щоб викрасти дані користувачів або виконувати несанкціоновані дії.
- Cross-Site Request Forgery (CSRF):
Атака, що змушує користувача виконувати небажані дії на довіреному веб-сайті.
- Обфускація та експорт даних:
Якщо код не обфусковано, його легко аналізувати, що може призвести до витоку конфіденційних даних.
- Небезпечні залежності:
Використання бібліотек із відомими уразливостями.
Найкращі практики для покращення безпеки JavaScript-коду
1. Захист від XSS-атак
XSS-атаки є одними з найпоширеніших загроз для веб-додатків. Ось як їх уникнути:
- Використовуйте бібліотеки для безпечного рендерингу:
Уникайте ручного вставлення HTML у DOM. Використовуйте бібліотеки, такі як DOMPurify, для очищення даних, введених користувачами.
Приклад очищення вводу:
import DOMPurify from 'dompurify';
const userInput = '<img src=x onerror=alert("XSS") />';
const safeInput = DOMPurify.sanitize(userInput);
document.getElementById('output').innerHTML = safeInput;
- Екранізуйте вихідні дані:
Якщо ви виводите дані у HTML, переконайтеся, що вони екранізовані.
Приклад екранізації:
function escapeHTML(str) {
return str.replace(/&/g, "&")
.replace(/</g, "<")
.replace(/>/g, ">")
.replace(/"/g, """)
.replace(/'/g, "'");
}
2. Захист від CSRF-атак
- Використовуйте CSRF-токени:
Сервер може генерувати унікальний токен для кожного запиту, щоб підтвердити, що запит походить від авторизованого користувача.
Приклад використання CSRF-токена:
fetch('/api/data', {
method: 'POST',
headers: {
'CSRF-Token': getCSRFToken()
},
body: JSON.stringify(data)
});
- Використовуйте заголовки:
Обмежте виконання запитів із сторонніх доменів, використовуючи SameSite для cookie.
3. Уникайте eval() та подібних функцій
Функція eval() виконує рядок як JavaScript-код і відкриває додаток для ін’єкцій.
Небезпечний код:
eval("alert('Це небезпечно')");
Рішення: Уникайте eval() та використовуйте безпечні альтернативи.
4. Перевіряйте дані, що вводяться користувачем
- Виконуйте перевірку як на клієнтській, так і на серверній стороні.
- Перевіряйте формат даних, довжину та інші обмеження.
Приклад валідації:
function validateInput(input) {
const regex = /^[a-zA-Z0-9_]{1,20}$/;
return regex.test(input);
}
5. Використовуйте HTTPS
Усі дані, які передаються між клієнтом і сервером, повинні бути зашифровані за допомогою HTTPS. Це захищає від атак типу Man-in-the-Middle (MITM).
6. Оновлюйте залежності
Використання застарілих бібліотек може відкрити уразливості.
- Використовуйте інструменти для перевірки залежностей, як-от:
Команда для перевірки залежностей:
npm audit fix
7. Обфускуйте код
Обфускація JavaScript-коду ускладнює зловмисникам його аналіз. Використовуйте інструменти, такі як UglifyJS або Terser.
Приклад обфускації:
npx terser script.js -o script.min.js
8. Встановлюйте обмеження доступу до ресурсів
Використовуйте політику Content Security Policy (CSP), щоб обмежити виконання несанкціонованого JavaScript-коду.
Приклад CSP-заголовка:
Content-Security-Policy: script-src 'self' https://trusted.cdn.com
9. Захищайте API-запити
- Використовуйте JWT (JSON Web Tokens) для аутентифікації.
- Обмежуйте запити за IP-адресою.
10. Регулярно тестуйте безпеку
- Використовуйте автоматизовані тести для пошуку уразливостей.
- Перевіряйте додаток за допомогою пентестів (penetration testing).
Висновок
Безпека JavaScript-коду — це ключовий аспект створення сучасних веб-додатків. Дотримуючись цих найкращих практик, ви можете захистити свої додатки від атак і забезпечити безпечний досвід для ваших користувачів.
Пам’ятайте: безпека — це постійний процес. Регулярно аналізуйте свій код, оновлюйте залежності та впроваджуйте новітні технології для захисту від загроз.
Що таке метод Вайкоффа та як його застосовувати у трейдингу?
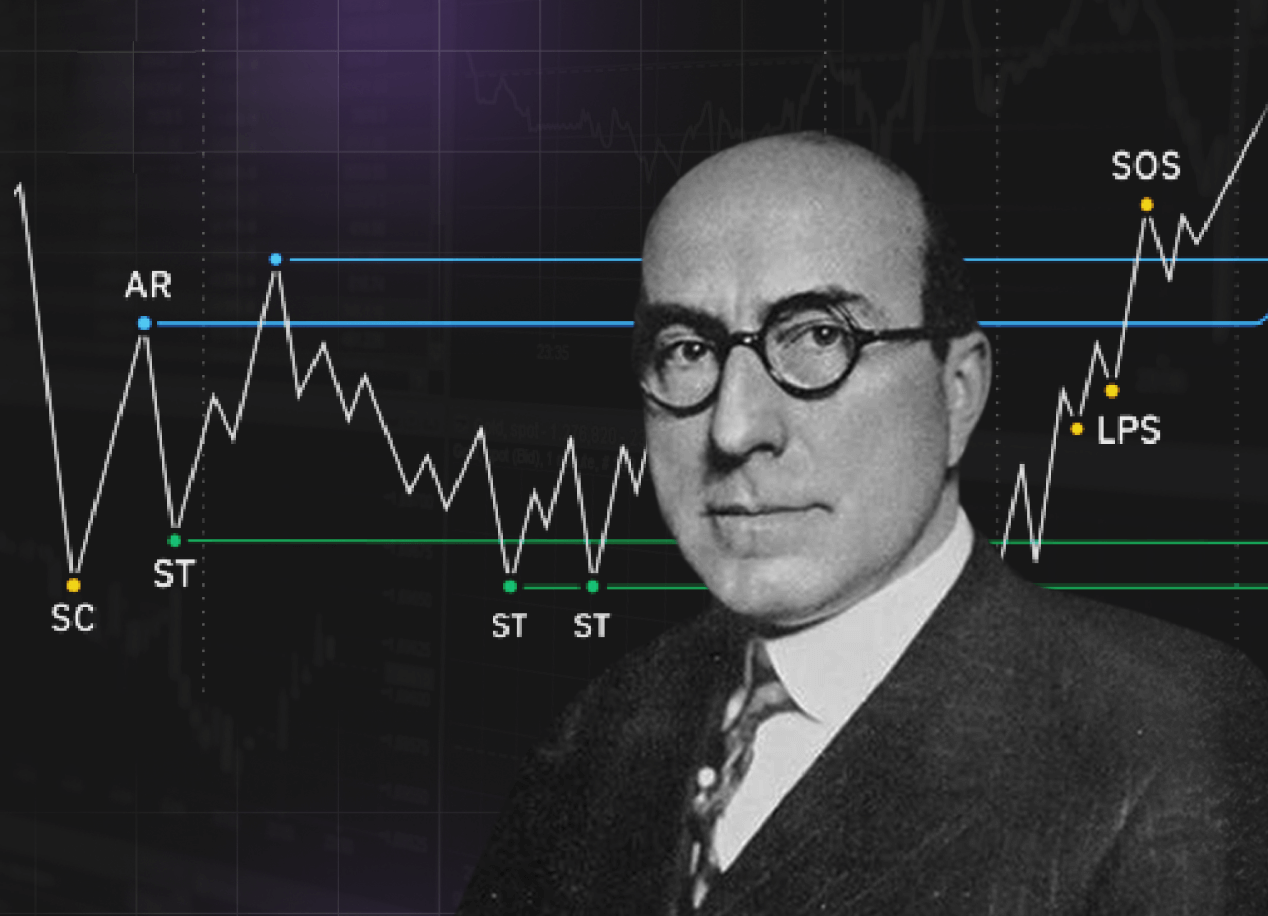
Метод Вайкоффа — це популярний технічний підхід до аналізу ринків, який був розроблений Річардом Д. Вайкоффом (1873–1934). Він відомий як піонер у сфері біржової торгівлі та засновник власного методу, який поєднує в собі ринкову психологію, аналіз попиту і пропозиції та логіку цінових циклів. Метод Вайкоффа знайшов своє застосування як на традиційних фінансових ринках, так і у світі криптовалют.
У цій статті ми розглянемо, що таке метод Вайкоффа, основні принципи його роботи та як його можна використовувати у трейдингу криптовалют.
Історія методу Вайкоффа
Річард Вайкофф почав свою кар’єру на Уолл-стріт у віці 15 років. Спостерігаючи за поведінкою ринку, він розробив унікальний підхід до аналізу ринкових циклів, заснований на логіці попиту і пропозиції. Його метод дозволяє трейдерам зрозуміти, як “великі гравці” (інституційні інвестори) рухають ринок, і використовувати цю інформацію для прийняття рішень.
Вайкофф вважав, що ринок функціонує за чіткими циклами, які складаються з фаз накопичення та розподілу. Його метод базується на аналізі цінового графіка, обсягу торгів і ринкової структури.
Основи методу Вайкоффа
Метод Вайкоффа ґрунтується на трьох основних законах, п’яти етапах ринкових циклів і концепції “Композитного оператора” (Composite Operator).
1. Три закони Вайкоффа
Закон попиту та пропозиції
- Суть: Коли попит перевищує пропозицію, ціни зростають. Коли пропозиція перевищує попит, ціни падають.
- Застосування: Аналіз обсягу торгів разом із ціною допомагає визначити співвідношення попиту та пропозиції.
Закон зусиль і результату
- Суть: Зміни ціни (результат) повинні відповідати обсягу торгів (зусилля). Якщо ціна мало змінюється при великому обсязі, це може свідчити про слабкість ринку.
- Застосування: Шукайте невідповідності між обсягом і ціною, щоб передбачити ринкові зміни.
Закон причини та наслідку
- Суть: Для кожного ринкового руху (наслідку) існує причина (накопичення або розподіл). Тривалість “причини” визначає масштаб “наслідку”.
- Застосування: Використовуйте горизонтальні діапазони (бокові тренди) для визначення майбутніх рухів.
2. П’ять етапів ринкових циклів
Фаза накопичення
- Суть: Великі гравці (інститути) накопичують активи за низькими цінами.
- Характеристика: Ціна рухається в боковому діапазоні з низькою волатильністю.
- Ціль: Шукати сигнали для входу на ринок, такі як пробій рівня опору.
Фаза підйому
- Суть: Після накопичення попит перевищує пропозицію, і ціна починає зростати.
- Характеристика: Висхідний тренд, підтриманий високими обсягами.
Фаза розподілу
- Суть: Великі гравці продають активи за високими цінами.
- Характеристика: Ціна рухається в боковому діапазоні, обсяги залишаються високими.
Фаза зниження
- Суть: Після розподілу пропозиція перевищує попит, і ціна починає падати.
- Характеристика: Низхідний тренд, зменшення обсягів.
Фаза капітуляції
- Суть: Ринок досягає дна, і знову починається фаза накопичення.
3. Концепція “Композитного оператора”
Вайкофф запропонував уявити ринок як єдиного гравця — Композитного оператора (Composite Operator). Він представляє великих інституційних інвесторів, які маніпулюють ринком для досягнення своїх цілей.
- Дії Композитного оператора:
- Накопичення активів за низькими цінами.
- Підйом цін для створення попиту серед роздрібних інвесторів.
- Розподіл активів за високими цінами.
Застосування методу Вайкоффа у криптотрейдингу
Криптовалютний ринок, завдяки своїй високій волатильності, ідеально підходить для застосування методу Вайкоффа.
1. Визначення фаз ринку
Використовуйте аналіз графіків, щоб ідентифікувати фази накопичення, підйому, розподілу та зниження.
- Приклад:
Якщо біткоїн перебуває в боковому діапазоні з низькими обсягами, це може свідчити про фазу накопичення.
2. Аналіз попиту та пропозиції
Використовуйте індикатори обсягу торгів для оцінки балансу попиту та пропозиції. Наприклад:
- Високий обсяг на пробої рівня опору — сигнал для купівлі.
- Високий обсяг на зниженні ціни — сигнал для продажу.
3. Налаштування стоп-лосів
Фази накопичення та розподілу можуть допомогти визначити ключові рівні підтримки та опору. Використовуйте ці рівні для встановлення стоп-лосів.
Переваги методу Вайкоффа
- Глибокий аналіз ринку:
Метод допомагає зрозуміти мотивацію великих гравців.
- Адаптивність:
Метод працює на різних ринках і з різними активами.
- Захист від маніпуляцій:
Розуміння поведінки Композитного оператора допомагає уникнути пасток.
Недоліки методу Вайкоффа
- Складність:
Потребує досвіду та навичок роботи з графіками.
- Висока волатильність крипторинку:
Непередбачувані події можуть спотворювати закономірності методу.
Висновок
Метод Вайкоффа — це потужний інструмент для аналізу ринку, який дозволяє трейдерам зрозуміти механізми руху цін і ухвалювати обґрунтовані рішення. У світі криптовалют, де волатильність є нормою, цей метод може стати надійним помічником для аналізу ринкових трендів.
Проте, як і будь-який інструмент, метод Вайкоффа вимагає практики та розуміння основ. Поєднуйте його з іншими інструментами технічного аналізу, і ви отримаєте чіткіше уявлення про поведінку ринку.
Історія підключення Великобританії до Arpanet

Arpanet (Advanced Research Projects Agency Network), створена наприкінці 1960-х років, стала першим мережевим проєктом, який заклав основи сучасного інтернету. Вона почала свою історію як експериментальна мережа, що з’єднувала дослідницькі установи США, але її вплив швидко поширився за межі країни, включно з Європою. Однією з перших країн, яка отримала доступ до цієї мережі, стала Великобританія. У цій статті ми розглянемо, як і чому це відбулося, і яке значення мала ця подія для розвитку глобальної мережі.
Що таке Arpanet і як вона працювала?
Arpanet була ініціативою DARPA (Агентство передових оборонних дослідницьких проєктів США) і створювалася як науково-дослідницька мережа для обміну інформацією між університетами та військовими установами. Це була перша у світі мережа, що застосувала технологію пакетної передачі даних.
Основні характеристики Arpanet:
- Пакетна передача даних: Інформація розбивалася на невеликі пакети, які передавалися незалежними маршрутами і збиралися на кінцевому вузлі.
- Децентралізована архітектура: Мережа не залежала від одного центрального вузла, що підвищувало її надійність.
- Протокол NCP (Network Control Protocol): Це був попередник сучасного TCP/IP, який забезпечував з’єднання між вузлами.
Перші кроки Великобританії до підключення
У 1970-х роках у Великобританії активно розвивалася наука і технології, і країна прагнула інтегруватися у міжнародні дослідницькі спільноти. Arpanet, яка до того моменту вже об’єднувала кілька провідних американських університетів і лабораторій, стала об’єктом інтересу для британських науковців.
Чому Великобританія захотіла підключитися до Arpanet?
- Обмін інформацією: Arpanet відкривала можливість швидкого обміну науковими даними з колегами у США.
- Доступ до обчислювальних ресурсів: Американські центри мали потужні обчислювальні машини, які могли використовувати британські дослідники.
- Підтримка інновацій: Підключення до Arpanet дозволяло брати участь у нових дослідницьких проєктах і сприяти розвитку комп’ютерних технологій.
Процес підключення
1. Початок співпраці
У 1973 році Arpanet почала розширювати свою мережу за межі США. Великобританія стала однією з перших міжнародних учасниць. Університетський коледж Лондона (University College London, UCL) грав ключову роль у цьому процесі.
2. Університетський коледж Лондона (UCL)
UCL був вибраний як вузловий пункт для підключення Великобританії до Arpanet. Лабораторія комп’ютерних наук цього університету мала сильні зв’язки з американськими дослідниками та відповідний технічний потенціал.
- Професор Пітер Кірнс (Peter Kirstein): Він очолив проєкт підключення UCL до Arpanet. Кірнс співпрацював з американськими дослідниками, щоб забезпечити технічну інтеграцію.
- Технологічне рішення: Для підключення використовувався спеціальний пристрій — IMP (Interface Message Processor), який слугував шлюзом між Arpanet і локальною мережею UCL.
3. Перше з’єднання
У 1973 році UCL офіційно підключився до Arpanet, ставши першою точкою доступу в Європі. З’єднання здійснювалося через трансатлантичний телефонний кабель.
4. Другий європейський вузол
Крім Великобританії, у 1973 році до Arpanet також підключився NORSAR (Норвезький центр сейсмічних досліджень). Це створило перший міжнародний трикутник обміну даними між США, Великобританією та Норвегією.
Значення для науки та технологій
1. Швидкий доступ до інформації
Підключення до Arpanet дозволило британським науковцям отримувати доступ до новітніх досліджень у реальному часі.
2. Співпраця між країнами
Arpanet стала платформою для глобальної співпраці, що прискорило розвиток багатьох наукових галузей.
3. Розвиток локальних мереж
Участь у Arpanet стимулювала розвиток локальних комп’ютерних мереж у Великобританії.
Труднощі та виклики
Підключення до Arpanet не було простим:
- Технічні обмеження: Висока вартість обладнання та складність налаштувань.
- Політичні бар’єри: Arpanet фінансувалася Міністерством оборони США, що викликало побоювання щодо безпеки даних.
- Інфраструктура: На початку 1970-х трансатлантичні зв’язки були дорогими й обмеженими за швидкістю.
Роль Великобританії в розвитку глобальної мережі
Участь Великобританії у Arpanet заклала основи для подальшого розвитку Інтернету:
- Поширення технологій: Досвід роботи з Arpanet допоміг Великобританії створювати власні мережі.
- Інтеграція в глобальну спільноту: Британські науковці брали активну участь у розробці протоколів, які пізніше стали основою Інтернету (TCP/IP).
- Основа для Європейських мереж: Велика Британія зіграла ключову роль у створенні таких мереж, як JANET (Joint Academic Network), яка стала провідною академічною мережею у Європі.
Висновок
Підключення Великобританії до Arpanet у 1973 році стало важливим кроком у розвитку глобальних мереж. Воно не лише сприяло прогресу науки і технологій, але й заклало основи для створення сучасного Інтернету. Історія цього підключення демонструє, як міжнародна співпраця та обмін знаннями можуть змінити світ.