“HTML – це просто”, “Розробляти фронтенд простіше, ніж бекенд”, “Після реалізації бекенда оновлення UI не повинно складати жодних труднощів”, – за час роботи у сфері веб-розробки навколо мене раз у раз звучали ці та інші аналогічні твердження.
Чому люди думають, що HTML – це просто?
А що взагалі означає «просто»? Простота якогось предмета зазвичай визначається щодо того, хто його розглядає. Коли я добре знаю якусь технологію чи мову програмування, для мене цей предмет виявляється простішим, ніж для новачка.
Деякі люди схильні будувати здогади щодо складності фронтенд-розробки, і на моєму досвіді зазвичай ними виявляються ті, хто не працює у цій сфері регулярно, особливо з HTML.
Ось кілька причин, які, на мою думку, це пояснюють:
Синтаксис HTML неважко вивчити. Поєднуємо кутові дужки, імена тегів та пари ключ-значення (атрибути) та готове!
Синтаксис HTML читабельний як для людей, так і для машини, що є однією з основних ідей XML-подібних мов.
Після написання кількох рядків коду у файлі .htmlможна одразу ж без компіляції переглянути результат, відкривши його у браузері.
У HTML низький поріг входу. У деяких WYSIWYG-редакторах є опція перемикання подання на «код», де можна переробити HTML-версію тексту, навіть не особливо розбираючись у процесі (вам доступно прев’ю, що тут може піти не так?)
Браузери – це чудовий інструмент, який прощає вам безліч помилок (Дж. Девід Айзенберг описував це у своїй старій статті, наводячи роздуми, які є актуальними до цього дня). При відкритті HTML-сторінки з синтаксичними помилками браузер все одно щось та змалює. Забули закрити тег? Не проблема. Додали невідомий тег чи атрибут? Браузер його просто проігнорує. У порівнянні з мовою, в якій через втрачену точку з комою падає вся програма, такий стан справ справді сприймається «простим».
Гаразд, із цим закінчимо. Наступним ми розглянемо питання про те, чому люди схильні порівнювати веб-технології або протиставляти розробку фронтенду бекенд-розробці.
Чому люди вважають, що фронтенд-розробка – це легко?
Найважчою частиною є програмування веб-сайту або програми, після чого створювати фронтенд вже нескладно. Правильно? Деколи мені здається, що саме так думають багато розробників.
Користувачі та стейкхолдери проекту часто не стикаються з бізнес-логікою бекенда і працюють тільки з UI. Обмірковувати розміщення різних кнопок, елементів інформації або спільну роботу UI простіше, тому що вона більш відчутна порівняно зі складними запитами до баз даних або вкладеними циклами forта інструкціями if. Бекенд – це чорний ящик, який робить свою магію і просто видає дані у фронтенд. Фронтенд-розробнику в результаті «просто» потрібно відобразити ці дані, додати кольори та побудувати макет (за допомогою CSS), довівши цим роботу до кінця.
На щастя, у цьому нам доступно безліч бібліотек клієнтських компонентів. Вам достатньо поєднати кілька (готових) уявлень, внести в них дані, і навіть не доведеться думати про кольори та макети – хіба це не круто? За такої всебічної допомоги майже будь-хто може створювати прекрасні фронтенд-рішення, не маючи особливого знання HTML/CSS!
</sarcasm>
Фронтенд руками «не-фронтенд» розробників
Я на особистому досвіді спостерігала, як люди, які вважають програмування фронтенду легким завданням (які звуть себе не фронтенд-, а фулстек-розробниками), допускали в коді найсерйозніші помилки (навіть при використанні фреймворків та бібліотек).
[…] якщо ви покладете всі ці та інші завдання на будь-кого […], він напевно виявиться значно слабшим у певних сферах, ніж інші. […] На моєму досвіді чоловіки частіше виявляють себе у знанні JavaScript або Python, але не CSS. CSS, який надає всьому «красу», вважається жіночою долею.
Деякі з позначених мною серйозних помилок були синтаксичними, інші стосувалися семантики, продуктивності, доступності тощо. В уявленнях прототипів під час тестування вони часто залишаються непоміченими, оскільки браузер до них не строгий, продуктивність на машині розробника зазвичай виявляється високою, а тести доступності не виконуються. передачі у продакшен.
Чому неправильний HTML-код є проблемою?
Перші проблеми можуть почати виявлятися після розгортання коду в продакшені. З ними зіткнуться користувачі, що не брали участі в розробці, коли почнуть взаємодіяти з продуктом. Деякі з цих проблем можуть стати наслідком помилок у HTML-коді.
Незручності для користувача
Розберемо проблеми, викликані некоректним HTML-кодом, з якими може зіткнутися користувач:
Незручні форми (я маю окрему статтю з прикладами на тему проблем при використанні форм).
Низька продуктивність (на YouTube є цікавий сюжет під назвою ” Get your ‘head’ straight “, в якому Гаррі Робертс розповідає про можливі проблеми в “шапці” HTML-документа).
Неправильне використання заголовків ( h1– h6) або відсутні текстові альтернативи для нетекстового вмісту, що завдає незручності тим, хто використовує скринрідер.
Неправильне використання або невикористання інтерактивних елементів («Div – це не кнопка!») або не інтуїтивний порядок табуляції між ними, що ускладнює навігацію та взаємодію за допомогою клавіатури.
Некоректний HTML-код веде до некоректної роботи JavaScript, а отже, і неробочої функціональності.
Незручності для розробника
Проблеми використання вашого продукту при некоректному HTML/фронтенд-коді можуть виникати не тільки у користувачів. Ваші побратими-розробники теж можуть часом хапатися за голову, бо…
…коли HTML-код погано структурований, стає складніше писати йому CSS. Іншими словами, після підключення до процесу розробки CSS код HTML часто потрібно коригувати. Коли у вас є досвід роботи з обома цими мовами, то, швидше за все, ваш HTML-і CSS-код вийде вдалим та зручним в обслуговуванні.
Якщо HTML-код UI-компонентів вашого проекту виявиться недостатньо гнучким, то при додаванні нової функціональності ви можете виявитися позбавлені можливості перевикористовувати їх або масштабувати проект в принципі, не вдаючись до рефакторингу.
…коли розробники не працюють з платформою, а намагаються заново винайти колесо, не зважаючи на можливість браузерів (наприклад, реалізуючи перехід між сторінками не за допомогою посилання, а через JavaScript), підвищується ймовірність виникнення багів, виправити які без порушення роботи решти програми виявляється складніше.
Чому це важливо?
Як говорилося вище, браузери мудрі та прощають нам багато помилок. Сайти можуть зберігати працездатність для багатьох користувачів, навіть якщо часом виявляються недоступними, повільно вантажаться, або подекуди дають збій. Обслуговування таких сайтів теж цілком здійсненне, якщо ви знайдете добросердечних розробників, які не проти повозитися з пахучою базою коду.
Ми, як розробники, повинні прагнути до того, щоб сайти та програми працювали для більшості, ні, для всіх користувачів інтернету, і створювати продукти, що відповідають потребам усіх наших (потенційних) клієнтів. Написання масштабованого та обслуговуваного коду не тільки веде до доступності, швидкості та зручності використання сайтів, але також полегшує життя розробників.
Справа не тільки в написанні HTML
Проблема тут у тому, що за відсутності базових знань HTML (CSS або JS) більшість відомих фреймворків не допоможуть вам досягти успіху швидше навпаки. В даному випадку це можна порівняти з розколюванням горіха за допомогою кувалди. Які б ви не використовували інструменти або новітні технології, зрештою в браузер відправляється саме HTML-, CSS- та JS-код, тому для створення хороших додатків необхідне знання принципу роботи цих мов.
Саме собою написання HTML справді не є складним.
Але! Побудова користувальницьких інтерфейсів шляхом елегантного компонування мовних можливостей за допомогою CSS, створення приємного дизайну і досвіду, що запам’ятовується, вимагає навичок, які не варто недооцінювати, як і HTML. Адже це одна з тих мов – можливо, найважливіша – які формують веб-середовище.
Аналогічну позицію щодо цінності (досвіду) веб-розробки розділили:
Крістіан Хейлманн, який відстоював самодостатність фронтенд-розробки як повноцінної роботи.
Джеремі Кейт, який турбувався, що ми можемо «досягти стану галузі, коли стандартним підходом до веб-розробки стане використання складних надінженерних рішень».
Давайте перестанемо порівнювати веб-технології та їхню цінність. Не обговорюватимемо, що простіше/складніше або більш/менш важливо. Давайте працювати в командах, прислухатися і вчитися у більш досвідчених людей, незалежно від того, чи є вони експертами в HTML, CSS, TypeScript, PHP, Python або [назвіть свою мову]… Давайте разом зробимо інтернет чудовим простором і цінуватимемо людей, які переважно працюють на фронті фронтенду!
Працюємо з HTTP API: розбір частих проблем та методи їх вирішення
Час іде, технології розвиваються, а проблеми, пов’язані з використанням API, викликають у багатьох розробників ті самі складності, що й десятки років тому. Тим часом, зростання числа сервісів, які взаємодіють один з одним за допомогою даного способу, з кожним днем тільки збільшується, і невміння надійно, якісно і безпечно працювати з API може призвести до небезпечних збоїв або поломки системи, що розробляється.
Працюючи над проектами з використанням API передбачити всі проблеми заздалегідь просто неможливо. І це стосується не тільки веб-розробки: подібні складності (як і способи їх вирішення) схожі в системах різного типу. А оскільки з розвитком технологій взаємодія між різними сервісами через API з кожним днем все більш затребувана, то і вміння правильно вибудувати роботу з АПІ стає для кожного розробника ключовим. Для підтвердження цього факту не потрібно ходити далеко за прикладами: так, з великими мовними моделями, на зразок OpenAI GPT-3.5 або GPT-4, щодня взаємодіють тисячі сервісів, і ця взаємодія відбувається саме за API. Про величезний інтерес інтеграції з боку розробників можна судити, наприклад, за кількістю зірок на гітхабі OpenAI Сookbook (понад 53000).
Ще трохи статистики: більшість сучасних API є HTTP API (такими як REST і GraphQL), і за результатами дослідження Postman “2023 State of the API Report“, REST (і його підвиди) залишається найпопулярнішою архітектурою – її використовують 86% респондентів. З цієї причини в статті я більше зосереджуся на проблемах, пов’язаних швидше з REST, хоча багато згаданих мною рішень можуть бути актуальними і для інших підходів.
“418 I’m a teapot” – що ж може піти не так?
Отже, ви тільки розпочали розробку свого веб, десктоп, мобільного або ще якогось додатку, який повинен отримувати інформацію із зовнішнього джерела за допомогою API. На перший погляд, завдання може здатися нескладним: швидше за все, ви вже маєте хорошу або не дуже документацію по взаємодії зі стороннім сервісом і прикладами його інтеграції. Усього тільки і потрібно, що просто написати код, який буде надсилати запити з вашої програми, чи не так? На жаль немає…. Адже насправді все набагато складніше, ніж у теорії. Вас може очікувати безліч труднощів, починаючи від проблем із продуктивністю зовнішньої системи та закінчуючи питаннями безпеки. Кожна з них по-своєму підриває стабільність вашої розробки: іноді ризики маленькі, і їх можна знехтувати для швидкості створення проекту. Але часто проблеми наростають як снігова куля. Саме тому не варто недооцінювати їхню складність, щоб завжди бути готовим до різних перешкод на шляху до успішної інтеграції із зовнішнім API.
Проблеми вирішуються легше, якщо заздалегідь підготувати стратегію з їхньої опрацюванню: дотримуючись наведених нижче правил, можна мінімізувати вплив сторонніх сервісів на стабільність проекту, який ви створюєте.
“500 Internal Server Error” – вирішуємо проблеми доступності API
Почнемо розбір із однією з найчастіших помилок, яку іноді припускають навіть найдосвідченіші розробники систем, що взаємодіють з API сторонніх сервісів. Це некоректна обробка випадків, коли запитуваний ресурс поламаний або зовсім недоступний.
Навіть у великих сервісів, таких як GitHub, можуть відбуватися збої, які впливають на роботу залежних від них програм. А, наприклад, статистика щодо інцидентів і uptime для Discord показує, що доступність їх API далеко не завжди становить 100%: раз на кілька місяців відбуваються будь-які проблеми. Це означає, що сервіси, що використовують API Discord у своїх додатках, схильні до ризиків, і можуть також ламатися, якщо заздалегідь не передбачити і не реалізувати систему обробки помилок.
Але якщо навіть такі відомі сервіси іноді ламаються, що тоді говорити про менш популярні?
Розберемося з тим, як можна вирішувати проблеми, пов’язані з доступністю ресурсів. Звичайно, підходи можуть дещо відрізнятися в залежності від того, для якої мети ви здійснюєте API-запити.
Працюємо з помилками оновлення даних API
Для обробки помилок при оновленні даних на сторонньому сервісі список варіантів рішення буде таким:
Асинхронна взаємодія. Черги запитів. У багатьох випадках, гарною практикою буде використання черг для відправки запитів на зовнішні ресурси. Такий підхід дозволить уникнути затримок при взаємодії користувачів з вашим сервісом при недоступності зовнішнього API: вашій системі просто не доведеться чекати, щоб віддати відповідь користувачу, перш ніж надсилання даних у сторонній сервіс успішно завершиться. Крім того, подібний метод дозволить вам отримати більший контроль над тим, як ви працюєте зі стороннім ресурсом. Наприклад, використовуючи його, ви зможете контролювати кількість запитів, що надсилаються в момент часу.
Не забувайте повторювати спроби надсилання даних у разі невдачі. У разі помилок під час надсилання запиту реалізуйте логіку для автоматичних повторних спроб через деякі часові інтервали. Інтервали краще не робити фіксованими, і нижче я розповім чому. А інформацію про всі здійснені запити слід зберігати для контролю роботи вашої системи та аналізу стабільності стороннього сервісу. Даний функціонал буде легше реалізувати після того, як ви дослухаєтеся до першого пункту і створите черги завдань. Але, звичайно, можна обійтися і без них – все залежить від того, як зроблено ваш додаток. Важливо: не повторюйте запити при помилках з кодами 4xx без додаткових дій з виправлення некоректного запиту . Справа в тому, що коди помилок, які починаються на 4, зазвичай говорять про те, що сам запит було надіслано некоректно (це клієнтські помилки).
Будьте уважні до управління чергою завдань. Раніше я розповів, чому черга завдань надсилання API запитів може допомогти вам. Але використовуючи її, важливо пам’ятати, що занадто велика кількість завдань, що одночасно виконуються, може просто перевантажити і вашу систему, і використовуваний вами сторонній сервіс. Саме тому необхідно збалансувати частоту та кількість повторних спроб надсилання даних. Для цього можна використати невелику рандомізацію часу повтору невдалого запиту. Або навіть краще – методику експоненційного відкладення кожного наступного виклику API ( exponential backoff ). Так ви зменшите ймовірність одномоментної відправки великої кількості повторних запитів і не покладете на лопатки вашу чергу і сервіс, з яким взаємодієте.
Уникайте повторного надсилання однакових даних. Якщо сторонній сервіс недоступний якийсь час, це може призвести до того, що в черзі на повторне відправлення з’являться запити, що дублюють або зайві API. Наприклад, користувач відредагував свій профіль зі стану A до стану B, потім зі стану B у стан C, і після цього знову повернув все до стану A, а при кожному редагуванні профілю ви повинні були оновити дані на сторонньому сервісі через API. У цьому прикладі ваша система може намагатися виконати зайві запити, адже в результаті дані повертаються в початковий стан, і значить відправлення всього цього ланцюжка, ймовірно, слід зупинити. Якби ми зупинилися в стані C, відправка всього ланцюжка запитів теж не мала б сенсу. У цьому випадку можна об’єднати всі дані змін в очікуванні відправлення і отримати diff щодо початкового стану (звичайно ж, враховуючи при цьому послідовність правок). Працюючи тільки з diff-ом, кінцевий запит ви отримаєте лише один, а на додаток зможете уникнути проблем, пов’язаних з гонкою станів .
Інформація користувача. Після кількох невдалих спроб надсилання API запиту, не забудьте повідомити користувача про проблему. Він швидше за все і не в курсі, що ваша система залежить від стороннього сервісу, а значить, може просто не дочекатися, коли необхідний йому функціонал почне працювати. Ця порада особливо актуальна, якщо без надсилання даних в інший сервіс ваша система не може якісно продовжувати роботу. Пам’ятайте, що при роботі з зовнішніми API може статися будь-яке. Наприклад, сервіс, який ви використовуєте в роботі, може просто закрити доступ до API або раптово зробити його платним (що саме недавно сталося з Twitter/X). Саме тому важливо передбачити подібні сценарії і постаратися знизити негативні емоції ваших користувачів, давши зрозуміти їм, що над проблемою, що склалася, вже йде робота і скоро вона буде завершена.
Обробляємо помилки при запиті даних API
Для кейсів, де ви запитуєте дані через API, способи та підходи рішення трохи інші, але є й загальні пункти:
І знову черги. Уявімо ситуацію: у реалізованому вами продукті реєструється новий користувач, але для завершення цього процесу вам потрібно підвантажити дані зі стороннього сервісу. Якщо цей сервіс та його API зламається, то тайм-аут операції на вашому сайті буде занадто довгим, реєстрація не пройде, і ви, можливо, втратите клієнта. Тому ми діємо тут, як і у випадку з відправкою даних до стороннього сервісу через АПІ – підвантажуємо дані через чергу щоразу, коли це можливо, знижуючи таким чином час відгуку вашої системи.
Повторні спроби запиту та управління чергою завдань . Тут все те саме, як і в пункті оновлення даних. Якщо ви реалізували підвантаження необхідних даних із сторонньої системи через чергу, доопрацювати систему для управління цією чергою не складе значних труднощів.
Запит даних безпосередньо від користувача, якщо сторонній сервіс недоступний. Такий спосіб рішення можливий у багатьох випадках: ви можете чесно сказати, що дані не завантажилися, і попросити користувача самостійно ввести їх. Звичайно, цей варіант не закриє всі кейси, адже бувають випадки, коли потрібно підвантажити історію замовлень або статистику, яку користувач, само собою, ввести не в змозі. Але якщо це, наприклад, просто список інтересів користувача, запитати про це буде легше, ніж продовжувати намагатися витягти ці дані з сторонньої системи, що не працює.
Кешування. Не слід щоразу намагатися отримати одне й те саме зі стороннього сервісу: використовуйте кеш, який заразом допоможе в тих випадках, коли запитуваний ресурс буде недоступний. Ну а якщо дані ризикують бути зміненими, кеш можна використовувати як запасний аеродром – просто попередьте вашого користувача, що вони могли застаріти.
Додаткове джерело отримання даних. Ніякий API не може називатися безпечним та стабільним джерелом даних, а отже, по можливості, слід передбачити і запасний варіант. Наприклад, ви займаєтеся розробкою сервісу, який аналізує історію покупок та продажу акцій на біржі. У цьому випадку вам буде доступно відразу кілька різних провайдерів API, що надають історичні дані по акціях. Отже, одного з них можна використовувати як fallback-варіант. Так, такий спосіб буде доступний вам далеко не у всіх сценаріях, але якщо вам пощастило, і додаткове джерело є – обов’язково беріть його на озброєння.
Додаткові поради
Крім перерахованого, для всіх випадків роботи з API важливо проводити налаштування connection timeout та request timeout запитів . Це допоможе уникнути надмірного навантаження на вашу систему, запобігаючи ситуації, коли запити виконуються надто довго.
Визначаємо connection timeout та request timeout за допомогою curl
Вибір значення таймууту – завдання непросте, і залежить від великої кількості факторів. Connection timeout зазвичай виставляється менше ніж request timeout, тому що процес встановлення з’єднання зазвичай займає менше часу, ніж обробка цього запиту сервером. Хоча, звичайно, все залежить від того, де розташовані сервери провайдера API. Щоб підібрати відповідні значення, розумним рішенням буде спочатку зібрати статистику роботи даного API в shadow mode. Такі дані легко отримати через curl за допомогою опції –write-out:
curl -o /dev/null -s -w "Time to connect: %{time_connect}\nTime to start transfer: %{time_starttransfer}\n" https://google.com
Після збору необхідних метрик, використовуючи статистичні дані, ви зможете визначити поріг допустимих таймаутів для роботи з API.
Ще однією корисною дією буде додавання систем моніторингу та оповіщень . Якщо сторонній сервіс перестав відповідати, ви повинні дізнаватись про це миттєво. А якщо API починає видавати занадто велику кількість помилок, необхідно передбачити систему, яка автоматично знизить потік запитів, що надсилаються в момент часу.
«429 Too Many Requests» – працюємо з лімітуванням кількості запитів
Тепер, коли ми вирішили проблеми, пов’язані з недоступністю АПІ, слід подумати, як боротися з лімітами на кількість запитів. Це питання теж дуже актуальне і може спливти в невідповідний момент. Більше того, провайдер API може ці ліміти зовсім несподівано змінити, тому життєво важливо передбачити подібну ситуацію заздалегідь, щоб вирішити всі труднощі максимально швидко.
Частина прописаних вище порад підійде і тут. Наприклад, кешування відповідей може врятувати вас від необхідності надто частого відправлення API-запитів, оскільки ймовірність перевищення лімітів тоді буде помітно нижчою.
Додаткова інформація про кеш в HTTP
Зазначу, що в HTTP API є безліч зручних механізмів роботи з часом життя кешу by design.
Наприклад, для отримання часу життя кешу можна використовувати заголовок Expires .
Cache-Control може використовуватись для встановлення інструкцій кешування.
ETag є ідентифікатором версії ресурсу. Якщо ресурс буде змінено, ETag також зміниться.
А Last-Modified показує, коли запитуваний ресурс був змінений востаннє. Але за наявності ETag, краще орієнтуватися саме на нього, оскільки він вважається надійнішим: Last-Modified має обмеження у вигляді одиниці часу (зазвичай за секунди), що може не відображати дрібні зміни. Крім цього, ETag буде точнішим у випадку, якщо ресурс був змінений, але його вміст залишився незмінним.
При цьому всі перераховані вище заголовки можна отримати за запитом типу HEAD . Він, зазвичай, не обмежується показником рейт ліміту чи обмежується значно більшим лімітом, ніж інші типи запитів.
Як і у випадку обробки ситуацій при недоступності API, крім реалізації кешування, ефективно використовувати чергу запитів і механізм для повторного відправлення запиту (можливо з реалізацією diff-логіки). Цей підхід можна назвати «золотим стандартом» для сценаріїв, коли не завжди можна отримати відповідь від стороннього сервісу миттєво. Керування чергами запитів допомагає забезпечити безперервну роботу програми, навіть якщо сторонній API тимчасово збоїть. Але є й додаткові рекомендації для запобігання проблемам з rate-limiting:
Працюйте у кожному окремому запиті з великою кількістю корисних (але не зайвих) даних. Наприклад, у багатьох реалізаціях REST API існує спосіб отримати одразу цілий набір елементів за певними фільтрами. Але не забувайте, по можливості, вимагати лише необхідні поля, щоб не ганяти зайві дані по мережі. POST / PATCH запити для створення або оновлення записів у деяких API також підтримують операції відразу з набором сутностей. Звичайно, REST є лише набором рекомендацій, у житті доступні можливості залежать від реалізації API, і подібний функціонал може бути відсутнім. Проте, практика показала, що можна зв’язатися з розробниками і попросити впровадити потрібні функції . Спробуйте. Гірше точно не буде!
Намагайтеся розподілити запити за часом. Коли ми обговорювали проблеми доступності API, я вже пропонував додавати випадковий час для повторного надсилання запиту. Але іноді для обходу лімітів потрібно реалізувати більш складний механізм. Для його реалізації краще наперед вивчити документацію та з’ясувати усі існуючі обмеження.
Використовуйте ключі API від користувачів, якщо це можливо. У деяких сценаріях, за наявності явної згоди користувачів, можна використовувати їх API-ключі для надсилання запитів на інші сервіси. Це може бути корисним для обходу обмежень кількості запитів, встановлених цими сервісами. Одним з найпоширеніших методів є використання технології OAuth . OAuth дозволяє користувачам надавати обмежений доступ до своїх даних через токени, за винятком необхідності передачі логіну та пароля. Важливо, що при використанні такого підходу необхідно суворо дотримуватися принципів безпеки. Для цього слід забезпечити належне інформування користувачів про способи використання їх даних, а також гарантувати безпечне зберігання та обробку API-ключів та OAuth токенів. Крім того, необхідно переконатися, що таке використання API-ключів відповідає політиці конфіденційності сторонніх сервісів та законодавству про захист даних.
Застосовуйте Callback-API там, де це можливо. Багато сервісів надають і такий тип API на додаток до REST, оскільки він є ідеальним варіантом для того, щоб запобігти безглуздому надсиланню зайвих запитів. За допомогою цього методу ви просто підписуєтеся на певні події, не опитуючи сторонній сервіс регулярно. Знову ж таки, реалізація даного функціоналу може сильно змінюватись в залежності від того, хто цей API надає. Проте є й стандарти. Наприклад, у специфікації OpenAPI 3 визначено, як правильно працювати з колббеками . Але використовуючи даний метод ви завжди повинні пам’ятати, що надаючи URL-адресу вашого ресурсу для callback-дзвінка, слід приховувати IP-адресу реального сервера. Крім того, домен, що використовується, не повинен бути очевидним для зловмисників.
До речі, використовуючи перелічені вище поради, ви не тільки зменшуєте ймовірність помилок, але й економите бюджет, якщо доступ до API – платний. Отже, це саме той випадок, коли можна вбити одразу двох зайців та заощадити патрони.
«451 Unavailable For Legal Reasons» – відповідь від API не завжди така, якою ви її очікуєте
Сторонній АНІ може повернути буквально все, що завгодно. Виправлення: а може і не повернути те, що ви хотіли від нього отримати. Адже не всі мають хороші методи для версіонування, а іноді їх і немає зовсім. Тож часом навіть один і той же запит може сьогодні повертати одне, а завтра – зовсім інше. Мораль: не забувати про такий варіант розвитку подій і ніколи не покладатися повністю на сторонніх розробників.
До речі, проблема не завжди пов’язана із зміною версій. Бувають випадки, коли після блокування ресурсу інтернет-провайдери замість якогось JSON-а починають повертати HTML з інформацією про блокування. Або, наприклад, сервіси захисту від DDoS можуть замінювати контент, також повертаючи HTML з капчею для перевірки користувача. Так, другий кейс можуть передбачити творці API, але на практиці таке відбувається далеко не завжди. Ось що допоможе в цій ситуації:
Валідація даних, що повертаються. Це дуже важливий крок. Відразу, виконуючи валідацію відповіді, ви зменшуєте ймовірність помилки при подальшій роботі з отриманими даними в коді. До даних, що повертаються, які варто перевіряти, відноситься не тільки response body, але й взагалі будь-яка інформація, яку ви використовуєте в додатку, наприклад, які-небудь заголовки, так як вони теж можуть бути схильні до несподіваних змін.
Використання API-прокси для приведення даних до очікуваного формату. Мінімізувати ризик помилок у додатку при взаємодії з API (особливо у випадках його незначних змін) іноді допомагає проксі. Спеціально налаштований проксі-сервер може допомогти привести отримані дані до необхідного формату, що особливо корисно, коли API часто оновлюється і модифікується. Проксі-сервер може згладжувати невідповідності між версіями API та структурою очікуваних даних у програмі. Існує низка рішень, які можуть підійти для цієї мети і навіть надати величезну кількість додаткових можливостей. Наприклад, вам може підійти Apigee – потужний платний сервіс Google. Але пам’ятайте, що будь-який API-proxy також схильний до помилок і проблем, тому завжди слід бути напоготові.
І тут теж потрібна система моніторингу та логування всіх проблем, пов’язаних із неправильними відповідями від використовуваного API. А налаштувавши оповіщення, ви зможете реагувати на будь-які помилки максимально швидко.
Зниження залежності від даних , що отримуються зі стороннього сервісу . Вкотре нагадаю цю прописну істину, щоб вона міцно засіла у пам’яті: взаємодія із сторонніми продуктами завжди несе у собі чималі ризики, тому, що вона менше, то краще.
Відстеження оновлень та новин провайдера API . Може статися так, що використовуваний вами API буде змінено, або якісь його функції будуть позначені як застарілі для видалення в майбутньому. Моніторинг новин та змін допоможе підготуватися до деяких потенційних складнощів, адже багато змін можуть анонсуватися заздалегідь.
Своєчасне оновлення версій API . Якщо API має різні версії, не тягніть занадто довго з оновленнями, адже рано чи пізно старі версії припиняють підтримувати, а після великої кількості часу оновлення може стати занадто дорогим і болючим.
Не ігноруйте перенаправлення. Може статися і така ситуація, коли ви успішно впровадили API, але через якийсь час його розробники вирішили додати редирект. Наприклад, інший домен. Або ж, у API-ендпоінтів раніше не було https, а коли його додали, вирішили відразу перевести всіх на безпечне з’єднання. Для того, щоб ваша інтеграція не зламалася від цієї редагування, краще завжди слідувати редиректам. У разі використання libcurl вам допоможе опція CURLOPT_FOLLOWLOCATION .
«426 Upgrade Required» – не забуваємо про безпеку
Ось про що, а про безпеку користувачі API думають не так часто. А дарма, адже зловмисникам це добре відомо. Досвідчені зломщики можуть скористатися вашою неуважністю і хакнути розроблювану вами систему, і для цього у них приготовлена маса способів.
Розробник, що реалізує взаємодію зі стороннім API, завжди повинен пам’ятати такі правила:
У жодному разі не зберігайте API-ключі або секрети в коді вашої програми. Навіть якщо ви думаєте, що до вашого коду точно ніхто не отримає доступ, або що розроблювана вами система взагалі мало кому цікава, на жаль, у хакерів свою думку на цей рахунок. І особливо їм подобаються робочі ключі для доступу до АПІ сторонніх сервісів, які, до речі, можуть бути платними.
Приховуйте реальний IP вашого сервера під час надсилання запиту. Знаючи IP, погані люди можуть зробити дуже багато поганих речей з вашим проектом та сервером. Наприклад, елементарно його заDDOSити. Для безпеки обов’язково використовуйте набір проксі-серверів, через які повинні йти запити з вашого сервера. Таким чином, у крайньому випадку погано буде не вашому реальному серверу, а лише бідному проксі, який, якщо що, можна легко замінити на новий.
Не довіряйте даних, що повертаються від стороннього API. Справа в тому, що окрім абсолютно безпечної інформації через відповіді від АПІ зловмисники можуть спробувати зробити SQL-ін’єкцію або XSS атаку. І не дарма, адже велика кількість розробників навіть не замислюється над тим, що так взагалі може бути. Всі дані, що повертаються від сторонніх сервісів обов’язково необхідно фільтрувати, перш ніж виводити на своєму ресурсі або зберігати куди-небудь. Вище я радив логувати відповіді від стороннього сервісу: отож, знайте, що цей тип атаки можна провести і через HTTP заголовки. Наприклад, якщо ви вирішили вивести в адмінку якийсь заголовок, який повернув сервер при відповіді на запит, без фільтрації контенту – це вірний спосіб нарватися на атаку XSS. Звичайно, тут я навів дуже рідкісний приклад, але його реалізація можлива. А це означає, що треба бути готовим до такого розвитку подій.
Не надсилайте через API секретну інформацію без необхідності. Намагайтеся стежити за тим, яку інформацію ви надсилаєте у запиті. У будь-якій його частині: у заголовках, параметрах, тілі. Будьте пильні завжди, а з персональними даними ваших клієнтів – тим більше, адже витік такої інформації може нести серйозні юридичні ризики.
Намагайтеся завжди використовувати HTTPS для API запитів . Вибираючи між http і https завжди використовуйте другий варіант: так ви суттєво зменшите ризик витоку інформації.
“200 OK” – тепер ви знаєте, як працювати з основними ризиками API
У цій статті я спробував висвітлити проблеми API, що найчастіше зустрічаються, і методи їх вирішення. Головне, що повинен пам’ятати кожен: під час роботи зі сторонніми API не варто вірити в їхню абсолютну надійність. Проблеми можуть виникнути там, де ви на них найменше очікуєте, тому вкрай важливо ретельно продумувати архітектуру та стратегії обробки помилок у ваших додатках заздалегідь, щоб максимально зменшити потенційні ризики та забезпечити стійкість роботи вашого сервісу в майбутньому.
З квантовими комп’ютерами вже не перший рік пов’язують безліч надій і водночас побоювань. На думку оптимістів, вони дадуть новий ривок у сфері обчислювальних технологій і зможуть вирішувати найскладніші завдання, з якими не справляються найпотужніші машини, що нині існують. Песимісти вважають, що пересічним користувачам всі ці кубити в «люстрах» не принесуть нічого, крім нових викликів у галузі криптографії та захисту персональних даних. Про те, як влаштовані квантові комп’ютери, які вже існують до початку 2024 року, і наскільки виправдані страхи перед ними, для читачів ForkLog розповідає Сергій Голубенко.
1965 року американський інженер Гордон Мур вивів закономірність: кількість транзисторів на мікросхемах подвоюється приблизно кожні два роки. Це спостереження згодом підтвердилося — потужність обчислювальних пристроїв досі стабільно зростає за експонентом.
Однак у 2007 році сам Мур припустив, що виявлена ним закономірність скоро перестане працювати – такі закони фізики. Найбільш перспективним виходом із цього глухого кута вже не перший рік називаю квантові обчислювальні системи (КВС), про які ми сьогодні розповімо.
Їх найважливіша відмінність від звичайних комп’ютерів полягає у способі зберігання та обробки інформації. Традиційні машини, побудовані з урахуванням кремнієвих мікросхем, містять мільйони транзисторів. Виконуючи роль мініатюрних «рубильників», кожен із них може бути або у положенні «включено» («1»), або «вимкнено» («0»). Згодом комп’ютер зберігає та обробляє дані, використовуючи двійкову систему (код) та оперуючи бітами даних.
КВС оперують кубитами (квантовими бітами) і можуть бути побудовані різними способами через надпровідні електричні ланцюги або за рахунок окремих іонів, захопленими магнітними пастками.
Для розуміння цього процесу потрібно вийти за рамки звичного сприйняття світу і перенестися у сферу квантового простору, де більший потенціал мають кубити, які мають здатність перебувати одночасно в кількох станах. Це явище називається суперпозицією. Квантовий стан дозволяє кубіту набувати значення не тільки одиниці або нуля, але й будь-якого між ними, а також обидва значення одночасно – зовсім як у уявному експерименті “Кіт Шредінгера“.
І найцікавіше: пригоди ймовірностей значень миттєво припиняються, щойно втручається спостерігач, якому потрібний лише результат «так» чи «ні». Цей дослідник, оператор квантового комп’ютера, з допомогою спеціального алгоритму отримує лише відповідь «1» чи «0». Перебування кубіту в суперпозиції дозволяє КВП паралельно обробляти значно більший обсяг даних, ніж класичний комп’ютер.
Створити один кубит і керувати ним лише частина завдання. Крім суперпозиції, кубити також відчувають «Сплутані квантові стани» – ще одна ключова квантовомеханічна властивість, при якій стан одного кубіту може залежати від іншого. Простіше кажучи, якщо «заплутати» два кубити і відправити один із них, наприклад, на відстань у кілька десятків кілометрів, використовуючи оптоволокно, то вони збережуть зв’язок і знатимуть один про одного все. Це відкриває неймовірні можливості у транспортуванні інформації з урахуванням квантового шифрування. Але ця технологія має слабкі місця: частки мають звичай губитися дорогою, і тому не всі з них приходять до фінішу.
Частинки, що виступають у ролі кубитів, вкрай сприйнятливі до випадкових збуджень – найменших теплових ефектів або електромагнітного поля сусіднього об’єкта. Через це квантовий комп’ютер видає правильну відповідь поки що лише з ймовірністю 98-99%. Для підтримки стабільної роботи кожну пару кубитів поміщають у холодний вакуум, де крім них немає нічого. Виникають питання: як організувати зберігання кубіту і які частинки можуть виступати у ролі?
Розглянемо на прикладі комп’ютера, який використовує як кубіти частинки іонів, наділені квантовою природою. Завдання: надати відповідній природній частинці (у нашому випадку іону) значення «1» або «0», яке він приймає відповідно на північ або південніше від екватора сфери Блоха. Це дозволяє створити «крани», якими можна керувати (змінювати значення ймовірностей усередині частки), використовуючи низькорівневе програмування. А для захоплення такої пари іонів та їх утримання у тісній заплутаності існує спеціальна пастка з електромагнітних полів. В результаті маємо заплутану пару іонів, якою можна керувати, помістивши у холодний вакуум.
У квантових обчисленнях використовують такі технології:
надпровідні кубити (або струми на кристалах);
фотонні кубити – генерація за допомогою оптичного обладнання заплутаних квантів світла та керування ними до кількох годин при кімнатній температурі;
іонні кубити в магнітних пастках – ланцюжок заряджених ядер іонів, які утримуються за допомогою електромагнітних полів у холодному вакуумі;
твердотільні квантові точки на напівпровідниках , керовані електромагнітним полем або лазерними імпульсами;
квазічастинки в топологічних квантових комп’ютерах — колективні стани кластерів електронів, «заморожених» фотонів або ферміонів Майорани, які поводяться як частинки всередині напівпровідників чи надпровідників.
Далі слід розібратися в принципах роботи квантових комп’ютерів та показати їхню відмінність від класичних.
Квантовий комп’ютер — це об’єднана аналого-цифрова система, яка працює за принципом «безліч значень ймовірностей» і дозволяє за допомогою заданого алгоритму отримати вибірку з кінцевих реалізацій цього алгоритму. Класичний комп’ютер — це цифрова машина, що обробляє інформацію в дискретній формі як рядок з одиниць і нулів.
Тут виникає ще одне закономірне питання: як отримані аналогові дані перевести у звичну цифрову форму? Використовуючи системи перетворення сигналу, вчені зробили низькорівневе програмування частинок. І в цій галузі тепер вирує серйозна робота: треба зробити так, щоб програміст писав високорівневий код, не маючи додаткових поглиблених знань у фізиці та хімії.
Ще одна актуальна проблема полягає в тому, що квантові комп’ютери на даному етапі мають масивну конструкцію і можуть розміщуватись тільки у великих приміщеннях. Форма «люстри», яку для цих цілей використовують у надпровідникових технологіях IBM та Google, вважається найзручнішою. Ця конструкція складається з безлічі мідних проводів, які поєднують усі частини комп’ютера: підсилювачі сигналу кубитів, надпровідні котушки, квантовий процесор, різні засоби захисту від радіації та електромагнітних хвиль. Причому це все в умовах вакууму. Якщо лабораторія використовує інші технології кубітів, форми конструкцій таких комп’ютерів можуть відрізнятися і навіть нагадувати класичний серверний блок.
Особливі властивості кубитів (надпровідність, надплинність і т. д.) починають проявлятися тільки при температурі, близькій доабсолютному нулю. Для охолодження квантового процесора доводиться використовувати установки з гелієм чи азотом.
Наскільки ж виправданий такий клопіт?
Якщо провести порівняння потенційних обчислювальних потужностей, то в класичному комп’ютері вони пов’язані з кількістю бітів: додавання одного транзистора збільшує пам’ять на 1 біт). У квантовому додавання одного кубіта збільшує пам’ять відразу в два рази. Як ми вже говорили, 1 кубит має всього два стани («0» або «1»), а завдяки заплутаності 10 кубітів мають уже 1024 стани; ну а сотня кубітів має 2 в 100 ступеня станів.
Очевидно, тут є що боротися. Але основне завдання — зберегти належний рівень якості заплутаності нових пар кубітів, оскільки просте зростання їх числа не призведе до підвищення продуктивності комп’ютера і не дасть квантової переваги.
Техгіганти та стартапи: квантові комп’ютери сьогодні
В даний час найбільших успіхів у галузі створення КВС досягли наступні корпорації, державні дослідні центри та молоді незалежні проекти.
IBM
Парк квантових комп’ютерів цієї корпорації вже налічує понад 20 машин, доступ до яких організовано через хмарний сервіс IBM Quantum Experience. У грудні 2023 року Quantum Summit представили перший модульний квантовий комп’ютер IBM Quantum System Two. Він базується на 133-кубітному процесорі Heron, який представники компанії називають найпродуктивнішим у світі. IBM також анонсувала процесор Condor з 1121 кубитом та на 50% більшою щільністю їх розміщення.
Google
У 2019 році співробітники техгіганту заявили про досягнення квантової переваги завдяки 53-кубітному комп’ютеру Sycamore на надпровідниках (щоправда, досягнення було оскаржене IBM). Тест, на думку критиків, був скоріше «показовим виступом» у рамках квантових перегонів. З того часу дослідники змогли додати до показників Sycamore ще 17 кубітів. Тепер він виконує за кілька секунд обчислення, на повторення яких сучасний суперкомп’ютер витратив би 47 років.
У Google, як і IBM, пішли перевіреним шляхом використання класичних мікросхем, впроваджуючи кубити через надпровідники.
Xanadu
Ця канадська компанія навесні 2022 року оголосила про запуск нового квантового комп’ютера Borealis, розгорнувши його в хмарі і надавши загальний доступ. Комп’ютер оснащений 216 фотонними кубитами. Як пише Nature, система успішно подолала бар’єр квантової переваги, закладений алгоритмом. І якщо найпотужнішому сучасному суперкомп’ютеру на виконання цієї операції знадобилося б приблизно 9000 років, Borealis впорався лише за 36 мікросекунд.
Atom Computing
Ця компанія з Каліфорнії створила перший у світі квантовий комп’ютер із 1180 кубитами, використовуючи нейтральні атоми, захоплені лазерами у двомірну сітку. Як результат, у комп’ютері Atom Computing квантові біти здатні працювати без помилок майже хвилину, тоді як аналогічний показник у комп’ютері від IBM становив лише 70-80 мікросекунд.
Науково-технічний університет Китаю
У грудні грудня 2020 року китайські вчені повідомили, що їх комп’ютер Jiuzhang, який працює на заплутаних фотонах, досяг квантової переваги. За 200 секунд вони успішно провели обчислення, які найшвидший у світі цифровий комп’ютер виконав би лише за півмільярда років.
Квантові обчислення та криптовалюти
Існує думка, що квантові комп’ютери в найближчому майбутньому зможуть зламувати блокчейни і, наприклад, знищити біткоін. Ці тривоги небезпідставні, але важливо пам’ятати про два нюанси.
По-перше, загроза більше відноситься до PoW -блокчейн, де під загрозу потрапляє дешифрування хешу. По-друге, шифрування RSA (найпоширеніша альтернатива криптографії еліптичних кривих) може бути квантово-стійким. Хоча коли йдеться про традиційне дешифрування, прийнято вважати навпаки.
Якщо міркувати глобально, багато залежатиме від того, наскільки швидко криптографи у відповідь на потенційні виклики вирішать проблему захисту від квантового злому.
У криптосфері вже є приклади компаній, які заявили про свою повну квантову стійкість: Quantum Resistant Ledger зі своєю криптовалютою QRL, а також технологія розподілу ключів QKD від JPMorgan – для захисту блокчейну від квантових обчислень. Для реалізації квантової стійкості QRL використовує IETF XMSS – схему прямого безпечного підпису на основі хешу з мінімальними припущеннями про безпеку, де XMSS – розширена схема підпису Меркла.
Рух у бік модульних блокчейнів також видається позитивним. Завдяки своїй структурі вони супроводжують простіше впровадження квантових підписів і в майбутньому вирішать проблему розподілу операторів нід для посилення децентралізації та захисту розподілених реєстрів.
Резюмуючи, можна сказати, що об’єднання зусиль блокчейну та квантових обчислень допоможе створити більш безпечні та потенційно революційні обчислювальні рішення, які зрештою дозволять вирішити цілу низку криптографічних та життєвих проблем.
Чи побачимо ми квантовий хардфорк біткоїну чи світовий квантовий інтернет — думаємо, питання часу.
Щоб усім було зручно його писати, обговорювати та рефакторити — без розпухлого беклогу та обличчя девопса.
Мені здається, що якщо запитати 10 випадкових розробників про те, як у них у командах влаштовано роботу над кодом, то в 9 випадків відповідь буде «Ну, як доведеться. Як звикли!».
Це дивно для галузі, в якій є справжній культ менеджерських практик: з них пишуть книги, проводять конференції, їм навчають. Але рідко коли навчають практик хорошої роботи над кодом! У крайньому випадку в команді знайдеться досвідчений лід або людина з хорошим системним мисленням, яка при цьому готова допомогти колегам стати краще.
Нагадаю вам базові правила, з яких потрібно розпочинати роботу в цьому напрямку. Побуду вашим системним лідом на півгодини, так би мовити!
Встановіть стандарти
Стандарти роботи над кодом та принципи його оформлення мають бути легко доступними для кожного учасника команди. Корисно провести невеликий семінар усередині та розібрати, які стандарти бувають.
Доступні всім стандарти полегшують виявлення проблем з якістю коду і дуже допомагають під час код-рев’ю.
Але не перестарайтеся з посібниками! Достатньо встановити суворі правила іменування, інтервалів та відступів, щоб покращити читабельність. Не потрібно регулювати кожен рядок коду. Завжди і скрізь більше правил — це менше швидкості розробки.
Любіть код-рев’ю
Код-рев’ю – це не тільки спосіб виправити помилки і зробити код кращим, це ще й можливість отримати знання про різні області вашої кодової бази. І спосіб поповнювати та покращувати стандарти, само собою.
Багато інженерних команд використовують принцип DoD (Definition of Done) – такий контрольний список виконаного перед тим, як код можна віддавати в продакшен.
Наприклад:
Пройдено юніт-тести.
Пройдено інтеграційні тести.
Усі некритичні баченням внесені в техборг.
Критична бізнес-логіка задокументована у коментарях.
Код відповідає стандартам команди.
Ось кілька інструментів, які допоможуть у ревію:
Husky для нативних гіт-хуків. Husky можна доповнити ESLint і Prettier – для підтримки коду за красою та стилем.
Snyk Code – для статичного аналізу коду, щоб знайти різні типи помилок.
Якщо у вас в команді немає регулярного код-рев’ю, то вам буде дуже важко писати код, що масштабується, ефективний і підтримується.
Спринтуйте борг
Наше завдання – не давати технологу розростатися.
Раджу виділити приблизно 20% ресурсів у кожному спринті на виправлення технічного боргу. Крім того, регулярно проводьте спринт, присвячений усуненню технічного обов’язку – цілком.
Ну, а взагалі є різні стратегії роботи з техборгом, це гідно окремої статті. Наприклад, є стратегія «контрольованої розширюваності» за рахунок низькопріоритетних іш’ю.
Розставляйте пріоритети
У компаніях часто сегментують помилки та звернення користувачів за пріоритетами, щоб насамперед лагодити найважливіше. Але з кодом це зробити складніше.
Наприклад, у JIRA не можна пов’язати проблеми користувачів з кодом та ефективно працювати з технічним боргом. Можна підключити зовнішній трекер, наприклад Stepsize – він дозволяє керувати проблемами прямо із середовища розробки.
Слідкуйте за метриками
У деяких командах прийнято стежити за метриками коду. Є навіть ціла академічна стаття про те, як вони влаштовані.
Наприклад, корисно вважати кількість коментів на 1000 рядків коду – це дасть загальне уявлення про складність. Якщо послідовно стежити за метрикою, можна побачити зміну складності, що буває корисно для техліда або техдира.
Також є поняття зв’язності коду (Code Cohesion). Цією метрикою вимірюють наскільки добре структурована та організована кодова база. Це не дивно, адже високоорганізовану кодову базу легше розуміти, підтримувати та покращувати.
І бонус-трек
Ніщо не покращує код краще за постійного внутрішнього обговорення, такого колективного код-рев’ю. Я раджу проводити їх не рідше 1 разу на місяць. У деяких командах це називають «прожаркою».
Попросіть кожного зібрати по кілька прикладів (доброго та поганого), зберіться у неформальній обстановці, можна з пивом та піцою (краще без ананасів). Описані стандарти, дружня атмосфера та терпимість до помилок – це найкраще, що ви зможете зробити для коду, колег та компанії.
Web Application and API Protection (WAAP): еволюція WAF (Web Application Firewall)
WAAP (Web Application and API Protection) є брандмауером веб-застосунків наступного покоління WAF (Web Application Firewall). Термін вперше почав використовувати Gartner для опису захисту сучасних, постійно змінних веб-сервісів. Так як у світі CI/CD, динаміки та API перших компаній, функцій традиційного WAF (Web Application Firewall) вже недостатньо.
Термін “WAAP” більш точно відповідає тому, як змінився ринок. Клієнти стали вимагати і чекати додаткових засобів захисту для боротьби з ландшафтом загроз , що швидко зростає і розвивається , який частіше включає вплив на інтерфейс програмування додатків (API), використання засобів автоматизації (ботів) для організації атак і розподіленої відмови в обслуговуванні (DDoS-атаки) ). Це також відображає тенденцію до консолідації функціональності, оскільки організації прагнуть більшої операційної та фінансової ефективності.
API-First, WAF-next
Багато компаній, які вже мають веб-додатки, що приносять дохід, запускають програму «API-First». Тепер старі монолітні програми розбиваються на мікросервіси, розроблені в еластичній та гнучкій архітектурі сервісної мережі.
API-First – це підхід до розробки серверних програм, при якому API є найважливішою частиною продукту. При застосуванні такого підходу API вашого продукту має власний цикл розробки, відповідно створюється його артефакт. Очевидно, що у вашому сервісі є залежність від артефакту API, чим забезпечується актуальність специфікації в цьому артефакті. Як видно, необхідно спочатку розробити API, а потім працювати над реалізацією цього API у вашому сервісі. Зазначена черговість розробки є необхідністю прихильності до підходу API‑First, але не визначення самого підходу. First у найменуванні означає, що API – це перший за важливістю продукт. У тому числі і з погляду захисту.
Загальне питання, з яким стикаються більшість організацій: як підвищити безпеку веб-додатків, у тому числі API?
Розвиток засобів захисту для протидії сучасним атакам
Захист API від сучасних кіберзагроз потребує виходу за рамки традиційних рішень. На допомогу приходить захист веб-застосунків і API (WAAP) – брандмауер веб-додатків наступного покоління (WAF-NG).
Загрози веб-застосунків постійно змінюються, що робить рішення на основі сигнатур немасштабованими. Рішення WAAP допомагають організаціям випереджати середовище загроз додатків, що розвивається завдяки аналітиці в реальному часі та постійному самонавчанню.
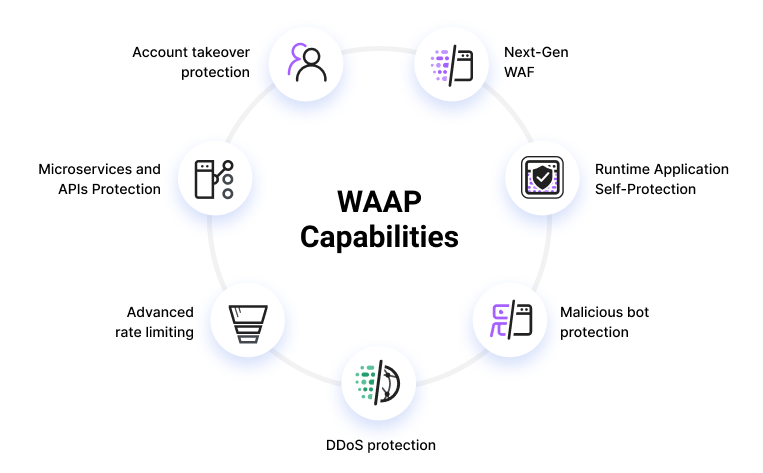
Компоненти WAAP
WAAP – це сукупність методів та технологій, які використовуються для захисту веб-додатків та сервісів від атак та вразливостей. WAAP включає такі технології, як WAF-NG, сканер вразливостей, автоматичне виявлення та блокування атак 0-дня (у тому числі за допомогою віртуального патчингу), виявлення аномалій за допомогою технологій Machine Learning і смарт-капчі.
WAAP є еволюцією класичного WAF і пропонує сучасні автоматизовані механізми захисту для постійно змінних веб-додатків.
Брандмауер веб-додатків наступного покоління (Next-Gen WAF) захищає та контролює веб-програми від широкого спектру атак у точці їх розгортання на рівні додатків.
Самозахист програм під час виконання (RASP), вбудований у домен середовища виконання додатків, забезпечує захист від атак у реальному часі для API та веб-застосунків.
Захист мікросервісів та API забезпечує безпеку мікросервісу, програми або безсерверної функції для створення мікропериметра з урахуванням контексту та даних навколо всіх окремих сервісів.
Тобто до традиційних засобів захисту (WAF) мають бути додані такі можливості:
Захист від ботів/скріпінга (частка ботів (хороших + шкідливих) у світовому інтернет-трафіку майже досягла 50% )
Захист від DDoS-атак рівня L7 (у 2023 році кількість DDoS-атак у всьому світі збільшилася на 63% — в основному через геополітичні чинники. На Росію припало 7,3% від загальної кількості нападів)
Оптимальним варіантом використання отриманих даних буде профіль трафіку: WAF зазвичай приймають рішення на основі окремих запитів або групи запитів, наприклад, всіх запитів в рамках HTTP сеансу або з однієї і тієї ж вихідної IP-адреси. Якщо виявити групу запитів у межах HTTP-сеансу, можна визначити статистично оцінити деякі характеристики. Наприклад, можна перевірити ймовірність певної послідовності HTTP-запитів у межах сеансу. У типових послідовностях зазвичай переважає звичайна поведінка користувача. Атипові послідовності можуть вказувати на небажані дії, наприклад, веб-сканер, що викликає посилання в незвичайному порядку.
Основною відмінністю WAAP від WAF є використання машинного навчання (ML) та/або поведінкового аналізу, а не лише наданих правил безпеки або відомих шаблонів атак».
Щоб виявити небажаний HTTP-сеанс за допомогою методів машинного навчання спочатку необхідно визначити відповідні функції (інжиніринг функцій). Тут базові дані використовуються для ідентифікації атрибутів, для яких модель згодом робить прогнози. Цей крок є важливим для успіху моделі. Приклади таких функцій веб-трафіку включають розподіл часу інтервалів запитів, розмірів об’єктів HTTP або розподіл кодів стану HTTP. Як очевидно з цих прикладів, окремі базові атрибути необроблених даних, такі як позначки часу, можна використовуватиме створення більш складних функцій кілька етапів. На основі цих функцій потім вибираються, налаштовуються та навчаються відповідні моделі машинного навчання. Слушна комбінація різних моделей призводить до створення системи, здатної виявляти певні відхилення в веб-сеансі. Ця система може відповідати на такі питання, як: чи виконувались окремі запити в сеансі людиною, чи це робилося лише програмним забезпеченням? Чи це звичайний користувач або його поведінка говорить про те, що він зловмисник? Якщо запити були викликані будь-яким програмним забезпеченням або ботом, чи це була легітимна пошукова система, інструмент моніторингу або, можливо, небажаний сканер сайту, бот або навіть інструмент атаки?
У цьому контексті кожну веб-програму можна навчати та захищати за допомогою власної спеціальної моделі. Наприклад, певна аномалія в одному додатку може бути абсолютно нормальною поведінкою в іншому. Це дає додаткову перевагу WAAP у порівнянні зі статичними функціями безпеки (класичний WAF), які потребують великих зусиль для налаштування та оптимізації для кожної окремої веб-програми. Під час навчання моделей також необхідно вжити заходів безпеки, щоб гарантувати, що зловмисник не зможе вплинути на етап навчання та побудови датасетів.
Web Application and API Protection знижує ризик компрометації, крадіжки даних, захоплення облікових записів та простою за рахунок інтеграції різних елементів керування безпекою захисту веб-застосунків.
Ймовірно, ви чули заяви типу «HTML і так за замовчуванням має accessibility» або «Не потрібно винаходити цей абсолютно ідеальний елемент управління HTML». Я вважаю, що це загальні заяви, а чи не універсальні істини. Веб-розробникам дуже важливо усвідомлювати недоліки платформи, тому я вирішив зібрати кілька прикладів того, коли у HTML виникають труднощі з точки зору як accessibility, так і usability.
Це неповний список, і він не включає недоліки ARIA. Мені хотілося знайти баланс між широко відомими проблемами і найчастіше зустрічаються (але менш відомими), а також додати до списку те, що ми сприймаємо як належне. У кожному розділі я вкажу ступінь серйозності проблеми, альтернативні рішення та посилання, за якими можна знайти більш детальну інформацію.
<select multiple>
Почнемо з простого. Атрибут multiple елемента <select>не варто використовувати практично ніколи. Він нагадує повну протилежність одиночного <select>. Єдине, що його виправдовує, то це те, що я поки не зустрічав цей атрибут в жодній кодовій базі.
Цитата користувача програми для читання екрана (з чудової статті Сари Хіглі, посилання на яку наведено нижче):
Це зламаний listbox. Він зовсім поламаний, я не бачу, як це можна виправити.
Серйозність : висока. Є велика ймовірність того, що більшість ваших користувачів не вміє працювати з цим жахливим елементом керування.
Що використовувати замість : цілком підходяща альтернатива – список чекбоксів; або можна створити власний listbox із множинним вибором.
Ще один простий приклад для розігріву. Елемент <i>семантично несуттєвий, тому необов’язково «поганий», якщо використовується для звичайного текстового вмісту. Однак найчастіше він застосовується для шрифтів значків.
У звичайній ситуації я навіть не став би включати його до списку, адже це більше помилка розробників, ніж проблема платформи. Проте вже 2024 рік, а я, як і раніше, зустрічаю елемент <i>, що використовується з чимось на кшталт FontAwesome. Це проблемно в основному тому, що веб-шрифт використовується для заміни текстових символів (які можуть мати одне значення) на значки (які ніяк не пов’язані з текстовими символами). сторінки та за промовчанням будуть включені в accessibility-дерево. Крім того, вони погано виглядають, часто (і непередбачувано 🐴) ламаються, призводять до інших проблем з accessibility. Докладніше про всі ці проблеми можна дізнатися з поста Тайлера Стіка, посилання на який наведено нижче.
Серйозність : низька або середня. Можна підвищити accessibility, виключивши його з accessibility-дерева (за допомогою aria-hidden) і задавши текстову альтернативу (за допомогою візуально прихованого тексту ), але елемент все одно залишається проблематичним.
Що використовувати замість : SVG! У них хороша підтримка, і вони у багатьох відношеннях кращі. На відміну від шрифтів SVG призначені саме для відображення графіки, тому через них в accessibility-дереві не з’явиться несподіваний текст. Крім того, їх можна застосовувати безліччю різних способів, так що ви можете вибирати: вбудовувати їх, використовувати спрайти або зберігати всередині CSS (за допомогою mask).
При використанні <svg> слід застосовувати наступний надійний патерн: aria-hidden разом із додатковим альтернативним текстом (який за потреби можна візуально приховати). Наприклад, розмітка кнопки виглядає так:
Неможливо скласти список проблемного HTML та не включити до нього ці списки.
Я не кажу «не користуйтеся списками», у багатьох ситуаціях вони дуже корисні. Але розробники схильні використовувати їх занадто активно, часто просто видалити стилі списків. Іноді ми навіть причіплюємо до них роль ARIA (перевизначаючи таким чином семантику списку), або, гірше за те, додаємо дочірні елементи без <li> стилізації або чогось іншого (створюючи таким чином неприпустиму розмітку). У всіх таких ситуаціях ми втрачаємо всі переваги елементів-списків та потенційно додаємо нові проблеми.
На це надмірне використання списків звернули увагу розробники Safari та почали в деяких випадках видаляти семантику списків; списки, що знаходяться зовні nav та стилізовані list-style: none, Safari списками не вважає. Хоча наміри розробників були хорошими, це призвело до того, що навіть правильно стилізовані списки стають виключно візуальними.
Крім того, упорядковані списки теж мають власні дива. Браузери вважають номери елементів «візуальними», тому при виборі та копіюванні списку номери не включаються до текстового елемента буфера обміну. Це порушує очікування користувачів, особливо якщо номери для них важливі, наприклад, у разі юридичних документів.
Серйозність : низька або середня. Я думаю, що цілком нормально дозволити Safari/VoiceOver робити те, що вони роблять; їх користувачі звикли до цього і навіть можуть очікувати, що веб майже немає списків. Проблема впорядкованих списків та буфера обміну може бути досить серйозною, але її можна вирішити обхідними шляхами.
Що використовувати замість : якщо вам сильно потрібно зберегти семантику списків, то <ul>можна додати role="list". Якщо ви використовуєте іншу роль, то цілком підійдуть звичайні <div>. Ще однією потенційною альтернативою для пар «ключ-значення» може бути <dl>.
Атрибут title напружує мене найбільше, зокрема, через його довгу історію. Він настільки поганий, що у специфікації HTML прямим текстом не рекомендують використовувати його. Проте я зустрічав цей атрибут у кожній кодовій базі, з якою працював.
Ось лише деякі з безлічі проблем title:
Зрячі клавіатурні користувачі ніяк не зможуть отримати доступ до вмісту title.
Користувачі з сенсорними екранами також не можуть отримати доступ до вмісту title.
Стандартну стилізацію підказок (tooltip) не можна змінити ніяким способом.
Над тригером потрібно тримати покажчик довільно довгий час, перш ніж з’явиться.
Підказку, що спливає, неможливо закрити без переміщення вказівника, тому вона може закривати інші частини сторінки.
На підказку неможливо навести покажчик, тобто миша повинна знаходитися над елементом тригера. Тому підказку може перекрити курсор миші, її текст неможливо вибрати, а користувачі екранної лупи не зможуть переглянути її.
Текст усередині спливаючої підказки не масштабується разом з рівнем користувача зуму.
Перенесення довгого тексту всередині підказки неможливо реалізувати; в деяких браузерах він стає шириною з екрана (навіть виходячи за межі вікна браузера), і тільки потім починає працювати перенесення.
Не можна вказати, чи має title бути частиною імені або опису елемента (або ні те, ні інше).
Програми для читання екрана по-різному читають вміст title у різних елементах.
Серйозність : висока. Використовуючи цей атрибут, ви навмисно вибираєте зниження accessibility для більшого відсотка користувачів.
Що використовувати замість : у багатьох випадках достатньо включити текст у вигляді частини вмісту елемента; при необхідності цей текст може бути візуально прихований. В інших випадках aria-labelledby або aria-describedby працюють краще, ніж title. Один із винятків — це iframe, які потрібно розмічати за допомогою title.
Майже у всіх випадках, поряд з описаними вище техніками, краще, ніж titleпідійде власна підказка. Однак у підказок є свої проблеми, тому ще краще буде перепроектувати так, щоб повністю позбутися необхідності підказок. Наприклад, завжди можна відображати текст або використовувати паттерн disclosure.
Спочатку елемент datalist видається успішною альтернативою своїх комбобоксів. Однак чим більше ви його використовуєте, тим глибшим стає розчарування.
Стандартна стилізація елемента вкрай сумнівна.
У десктопному Chrome він відображається як дивно зміщений спливаючий контейнер (popover), який різко змінює своє місце розташування, коли користувач вводить текст; одночасно він від’єднується від елемента введення, коли користувач прокручує сторінку.
У Chrome під Android він відображається поверх віртуальної клавіатури (а не на сторінці) і лише у портретному режимі.
Його зовнішній вигляд неможливо налаштувати. Він не враховує навіть color-scheme.
Він не враховує розмір користувача шрифту і рівень зуму.
В цілому він добре підтримується десктопними програмами читання екрана, але на мобільних для взаємодії з опціями необхідно перейти до кінця сторінки.
У Firefox під Android він взагалі не працює!
Серйозність : середня або висока. У кращому випадку цей елемент може бути корисним як необов’язкова підказка полів введення, які будуть повністю робітниками без додаткової допомоги з боку опцій автоматичного завершення.
Що використовувати замість : <select> або власний комбобокс.
Текст-заповнювач повинен допомагати користувачеві, підказуючи, коли поле введення порожнє. Насправді він часто виконує зворотну функцію.
Текст-заповнювач зазвичай схильний до проблем контрастністю кольорів. Якщо спробувати виправити контрастність кольорів, то він може стати невідмінним від реальних значень, що вводяться. Якщо помістити в нього важливу інформацію (наприклад, вимоги до пароля), то значення, що вводиться, приховує цю важливу інформацію відразу після того, як користувач почне друкувати.
Серйозність : середня або висока. У найкращому разі його можна ігнорувати. У гіршому він може дратувати користувачів та шкодити прибутку.
Що використовувати замість : може, нічого? Цілком можливо досить помітного label. Якщо вам потрібен текст підказки, можна розмістити його зовні поля введення і зв’язати їх за допомогою aria-describedby.
Числові поля введення виконують інкремент/декремент під час використання колеса миші, жестів чи клавіш зі стрілками, внаслідок чого вкрай ймовірні неприємності.
І це на додаток до інших проблем з accessibility, узгодженістю та стилізацією.
Деякі браузери мовчки ігнорують нечислове введення без будь-якого зворотного зв’язку.
Інші браузери дозволяють вводити довільні числа, але запускають події з порожніми значеннями, втрачаючи таким чином дані, введені користувачем.
Кнопки зі стрілками дуже малі та їх складно натискати.
Кнопки зі стрілками неможливо стилізувати (крім простої схеми кольору).
Що використовувати замість : <input inputmode="numeric" pattern="[0-9]*">. Атрибут inputmode допомагає відображати на пристроях із сенсорним екраном зручнішу клавіатуру, а атрибут pattern допомагає з валідацією.
Нативні елементи вибору дати мають неузгодженість у браузерах, а деякі їх частини порушують accessibility.
У десктопному Chrome на кнопку календаря неможливо перейти клавішею Tab.
У десктопному Safari елемент вибору дати не можна закрити з клавіатури.
У десктопному Safari елемент вибору дати має крихітний розмір і неможливо збільшити.
У Chrome та Firefox під Android в елемент вибору дати не можна нічого ввести, тому доводиться використовувати незручний UI календар, навіть якщо користувачу відома дата.
У всіх середовищах формат даних відображається як текст-замінник, який, як ми вже з’ясували, викликає проблеми. Формат дати визначає браузер і він може вибрати щось дивне (наприклад, формат дати США), що призводить до непотрібних труднощів.
Серйозність : висока. Ці неузгодженості не просто невеликі незручності, вони створюють реальні перешкоди для accessibility.
Що використовувати замість прості поля введення тексту, а в деяких випадках навіть select.
Також можна використовувати окремі поля для дня/місяця/року та згрупувати їх за допомогою fieldset. Цей fieldset навіть можна стилізувати так, щоб він виглядав, як одне суцільне поле форми . Однак якщо ви вирішите сховати label поля введення, то я б рекомендував відображати формат дати поза поля вводу (як частина легенди або під полями введення).
Відомо, що власні елементи введення дати дуже складно реалізувати правильно, тому якщо вирішите створити їх, вони повинні бути опціональними і доповнювати поля введення тексту.
Просто не користуйтеся ними. Якої б поведінки ви не очікували від цього елемента… ви, швидше за все, помилитеся. Спочатку елемент <menu> мав на увазі як “контекстне меню”, але його так і не реалізували, а тепер він замінений <ul>.
Серйозність : низька. <menu> просто перетворюється на <ul>.
Що використовувати замість : оскільки термін «меню» перевантажений значеннями, це залежить від того, що ви хочете зробити. Ось деякі з альтернатив:
<ul>(або role="list"), якщо у вас є список.
role="menu"якщо у вас меню в десктопному стилі.
role="listbox", коли у вас щось нагадує власний <select>.
<dialog> або role="dialog" якщо у вас стандартний спливаючий контейнер (можливо, з role="list" всередині).
Варто зазначити, що деякі з цих ролей вимагають підключення взаємодій із JavaScript.
Відключені кнопки чомусь активно використовують, можливо через їхню звичність. Ось два популярні сценарії застосування відключених кнопок:
коли дія тимчасово недоступна, наприклад через те, що потрібна якась обов’язкова задача (наприклад, вибір елемента або правильне заповнення форми).
при відправленні форми, щоб уникнути повторного відправлення.
Однак атрибут disabled не просто запобігає клікам. Він також вимикає функції hover та focus. І це має багато негативних наслідків. Вимкнені кнопки не можуть відображати підказки (які можуть пояснювати, чому кнопка вимкнена). Клавіатурні користувачі не можуть дістатися до вимкнених кнопок через Tab. Якщо кнопка раптово стає вимкненою (наприклад, при відправленні форми), фокус може загубитися і збити з пантелику. Крім того, відключені кнопки звільняються від вимоги контрастності кольорів , підвищуючи ймовірність їх поганої контрастності.
Серйозність : висока. Відключені кнопки зручні (та й то не особливо) тільки для невеликого відсотка бази користувача.
Що використовувати замість : aria-disabled="true" і вручну вимкнути кліки. Однак, при можливості, переробте дизайн так, щоб він не вимагав відключених кнопок.
Нативний програвач відео, як і раніше, має безліч проблем з accessibility і usability. У багатьох браузерах у клавіатурних користувачів виникає проблема з фокусом, тому що вони можуть дістатися не всіх елементів управління, і ці елементи пропадають після початку відтворення відео. У деяких аспектах він незручний і для користувачів програм читання екрана, особливо у разі «просунутих» функцій на кшталт режиму «картинка у картинці».
Рекомендую прочитати наведену нижче статтю Адріана Розеллі, щоб глибше вивчити підтримку цього елемента в різних браузерах і програмах читання екрана.
Серйозність : середня або висока.
Що використовувати замість : точно не знаю. Можливо, альтернативний програвач відео, якщо він розроблявся з урахуванням accessibility. Але чим би ви не користувалися, не забудьте додати підписи та транскрипції, а також надайте можливість скачування відео для його перегляду у зручному для користувача плеєрі. І заради піклування про користувачів не застосовуйте autoplay.
Посилання в Інтернеті можуть мати протокол, що не відноситься до http на кшталт mailto: або tel:. Ці протоколи активно використовують, щоб допомогти користувачам (або спамерам) надіслати електронний лист або набрати номер. Однак дуже сміливо було б вважати, що користувач заходить на сайт з того ж пристрою, який буде використовуватися для надсилання електронного листа або набору телефонного номера, і що він хоче використовувати для цього програму за промовчанням. Це може призвести до роздратування, коли користувач просто шукає спосіб скопіювати номер або набрати його з іншого пристрою. Найгірше, адресу пошти/номер часто приховують під посиланням, відображаючи замість нього щось марне типу «Написати мені».
Серйозність : низька або середня. Це дратує і збиває з пантелику, але, напевно, нічого особливо страшного в цьому немає. Користувачі знаходять способи вирішити проблему.
Що використовувати замість : просто покажіть реальну адресу пошти або номер телефону. Його можна легко скопіювати або перенести вручну на потрібний пристрій. Крім того, багато пристроїв автоматично відображають підказку під час вибору тексту, який можна розпізнати як пошту/номер.
На завершення хочу повторити, що з реалізації accessibility недостатньо «просто використовувати HTML». Навіть маючи найкращі наміри та використовуючи абсолютно правильну розмітку HTML, можна створити UI без потрібного рівня accessibility, якщо підійти до справи без старанності.
Я впевнений, що за десять років цей список буде виглядати інакше (і, сподіваюся, стане коротшим). Чим більше людей цікавитиметься цією темою, тим доступнішою стане інформація. Це змусить органи стандартизації та постачальників браузерів удосконалювати платформу та наблизити нас до Інтернету з більшим ступенем accessibility. Ви особисто можете допомогти, повідомляючи про нових баг або коментуючи вже знайдені:
Що таке ефект Лінді та як його використовувати в інвестиціях
Що таке ефект Лінді?
Ефект (закон) Лінді – теорія, згідно з якою очікувана тривалість існування феномена прямо пропорційна тому, що він існував до цього. Вперше закономірність виявили на Бродвеї, де постановки, що протрималися на сцені 100 днів, найчастіше могли розраховувати на такий же термін «життя» у майбутньому (якщо шоу йде 200 днів, йому прогнозують ще стільки ж).
Появу теорії приписують фінансисту Альберту Голдману, який 1964 року опублікував у газеті The New Republic статтю «Закон Лінді». Він припустив, що тривалість успішної кар’єри коміків залежить від кількості та частоти їхніх публічних виступів.
Пізніше до цього ефекту звернувся математик Бенуа Мандельброт, який працював в IBM, і згадав закон Лінді в книзі 1982 року «Фрактальна геометрія природи». У наші дні теорію популяризував письменник Нассім Талеб. Він описав закон Лінді у своїй книзі 2012 року «Антихрупність».
«Якщо книга перевидавалася протягом сорока років, я можу передбачити, що її перевидатимуть ще сорок років. Однак, і в цьому головна відмінність від псованих явищ, якщо книгу перевидаватимуть і через десять років, можна буде прогнозувати, що вона перевидаватиметься і через півстоліття. Ось чому речі, які оточують нас довгий час, як правило, не „старіють“, подібно до людей, — вони „старіють“ навпаки. Щороку, який річ зуміла пережити, подвоює її очікувану тривалість життя», – пише Талеб.
У такому вигляді теорія стала найбільш популярною для застосування під час інвестування в ідеї, продукти та активи.
Як ефект Лінді використовують інвестори?
В інвестиційній діяльності ефект Лінді є своєрідним знаком якості — «перевірено часом». Якщо перенести припущення Талеба про книжки на активи компаній, ми отримаємо таке: що довше «живе» фірма, то вищі шанси, що вона «виживе» у майбутньому.
Наприклад, якщо фінансовий гігант JPMorgan існує більше двох століть, то ймовірність, що він продовжить роботу в наступні 10 років, набагато вища, ніж у біржі Coinbase. І навпаки, закриття компанії Coinbase в найближчі 10 років можна прогнозувати з більшою впевненістю, ніж банкрутство JP Morgan.
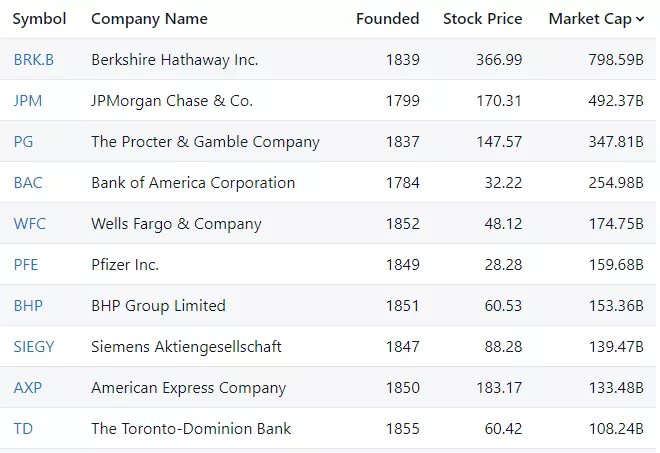
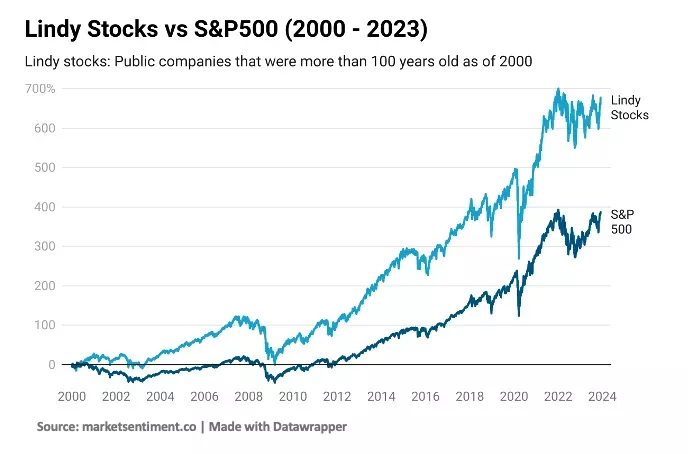
Як приклад звернімося до даних про капіталізацію 10 найстаріших громадських підприємств.
Логічно припустити, що старі компанії мають міцні зв’язки на всіх рівнях, найкращий досвід у побудові бізнесу, підборі кадрів та виборі векторів розвитку. І нехай закон Лінді не гарантує вищі прибутковості при інвестуванні в старі компанії щодо молодих, є докази ефективності цієї стратегії у довгостроковій перспективі.
Аналітики з Market Sentiment провели ретроспективний аналіз стратегії вкладення $100 у компанії, яким понад 100 років порівнявши її з інвестуванням такої ж суми в активи з індексу S&P 500.
Експерти виявили, що з 2000 по 2023 рік акції Лінді зросли на 676%. За цей же час індекс S&P 500 показав прибутковість лише на 386%.
За допомогою ефекту Лінді інвестори прогнозують не лише «живучість» тієї чи іншої компанії, а й технологічні та інші тренди. Наприклад, якщо Web3-соцмережі не приживуться протягом найближчих п’яти років, то навряд чи вони продовжать існувати в наступне десятиліття.
Як застосувати ефект Лінді до біткоїну?
Якщо звертатися до закону Лінді, перша криптовалюта нічим не відрізняється від інших технологічних трендів. Однак варто врахувати, що біткоїн вже прижився у всьому світі.
Наприклад, схвалення спотового біткоін- ETF може свідчити про остаточне прийняття цифрового золота глобальною фінансовою спільнотою.
Отже ефект Лінді для BTC варто розглядати з точки зору стабільного розвитку першої криптовалюти. Якщо біткоїн зміг «вижити» за минулі 15 років, він, ймовірно, продовжить існувати й у наступні 15 років.
Як застосувати ефект Лінді до альткоїнів?
У той час як біткоїн виглядає дуже «живучим», ринок альткоїнів таким не є.
Аналітики часто відзначають циклічність, якої схильні ціни на криптовалюти. Передбачається, що це корелює приблизно з чотирирічними періодами між халвінгами в мережі біткоїну.
Згідно зі статистикою CoinGecko, понад 50% усіх криптовалютів, перерахованих на їх платформі, припинили своє існування. За даними сервісу, з 2014 року «померло» 14 039 проектів, а запущені під час бичачого ринку 2021 постраждали найбільше.
Звідси може випливати, що для застосування ефекту Лінді до альткоїнів варто розглядати тільки ті токени, які пережили хоча б два цикли халвінгу біткоїну, тобто близько восьми років.
Отже, якщо якийсь альткоїн проіснував, наприклад, чотири роки, це не означає, що він проживе ще стільки ж. А якщо він зміг витримати на ринку вісім і більше років, ймовірність того, що він котируватиметься надалі, стає вже вищою.
Як писати чистіший CSS: дюжина порад від банальних до неочевидних
CSS як технологія справді трохи роздутий, але не такий хаотичний і складний, як його іноді описують. Просто потрібно прагнути лаконічності – у тому числі, за допомогою описаних підходів.
Ненависть до CSS цілком можна зрозуміти – врешті-решт технологія розвивається вже понад 25 років. Нові браузери, що з’являються на ринку, реалізують підтримку CSS по-різному, що призводить до того, що частина коду працює в одному браузері, але не працює в інших. А розробнику доводиться інтегрувати до коду купу вендорних префіксів. Адже це потім ще треба розширювати і підтримувати!
Щоб не потонути в коді, користуйтеся більш сучасними та наочними підходами. Про деяких із них ми й поговоримо.
Підійдіть до вивчення CSS з правильного боку
Найкращий спосіб не вивчати CSS – це використовувати фреймворки, на зразок Bootstrap або Tailwind CSS. Ці інструменти допомагають швидко отримати гарний інтерфейс користувача, але ніяк не сприяють вивченню основ CSS (використовуючи їх, ви навчаєте тільки сам інструмент). І ви точно відчуєте біль і страждання при спробі від них відмовитися.
Вивчення основ CSS дає більше контролю над кодом та творчістю. І найкраща порада – почати з блокової моделі CSS, тому що зрозумівши її, ви знайдете більше сенсу у всій іншій мові.
Просто думайте про кожен HTML-елемент, як про блок, всередині якого міститься контент. Блок може мати висоту ( height) та ширину ( width), межу ( border), відступи всередині ( padding), а також пробіли навколо цієї межі зовні ( margin). Все, що CSS пов’язане з макетом і розташуванням, спирається на блокову модель.
Якщо ви відкриєте інструменти Chrome, побачите, як обчислюється блокова модель для будь-якого елемента на сторінці.
І це автоматично приводить нас до наступної поради.
Використовуйте Flexbox
Історично розташування елементів один щодо одного було одним із найскладніших аспектів CSS.
Ох вже це споконвічне питання про те, як центрувати елемент divі по горизонталі, і по вертикалі! Один із варіантів це реалізувати – задати дочірньому елементу абсолютне позиціонування, а потім перемістити його в нижній правий кут, використовуючи властивості top і left. Щоб помістити в центр не верхній лівий кут елемента, а саме його центр, потрібно також вказати властивість transform: translate(-50%, -50%). Ця властивість переміщає елемент вгору на 50% його висоти вздовж осі Y і вліво на 50% його ширини вздовж вісь X. У результаті потрібної точки виявиться саме центр.
Більш сучасний інструмент CSS – це flex, який створює гнучкий стовпець або рядок в будь-якому місці інтерфейсу користувача. У flex-елемента також є осі X і Y, якими можна вирівняти його дочірні елементи (їх можна вирівняти вздовж головної осі за допомогою властивості justify-content: center). Перемістити елемент в центр і по горизонталі, і по вертикалі можна за допомогою властивості align-items, вирівнявши відносно поперечної осі.
Flex – це перший інструмент, до якого слід звертатися, коли справа стосується макету. Але він має один істотний недолік. Якщо користувальницький інтерфейс великий і складний, з безліччю рядків і стовпців, що перетинаються, в HTML-коді буде занадто багато елементів-контейнерів. Ці елементи не мають семантичного значення і існують просто для того, щоб CSS-код був, до чого прикріпитися.
На заміну їм є сучасна функція CSS – Grid. На відміну від flex, який працює тільки з окремими стовпцями та рядками, gridдозволяє думати про макет в цілому. Якщо ви займаєтеся веб-розробкою досить довго, ця ідея може здатися вам знайомою, тому що дуже нагадує таблиці. Просто gridнабагато більш дружелюбний до розробників.
Встановлюючи grid, можна визначити його дочірні елементи як набір стовпців і рядків. Стовпці мають ширину, яку можна визначити за допомогою властивості. grid-template-columns.Можна використовувати значення frабо fractional unit, яка ділитиме доступний простір з іншими стовпцями в сітці. Ми також можемо визначити декілька рядків, після чого кожен елемент усередині сітки буде розміщуватися автоматично.
У наступному прикладі дочірні елементи розміщуються в сітці 2 рядки та 3 стовпці. Середній стовпець має фіксовану ширину 500px, а інші два стовпці займають простір, що залишився. Рядки мають фіксовану висоту 100pxі 200pxвідповідно.
У контексті адаптивних макетів найчастіше йдеться просто про зміну ширини чогось залежно від доступного місця на екрані пристрою або в області видимості. Є кілька способів її скоригувати.
Допустимо, ви хочете, щоб стаття займала 50% ширини. Але на маленьких екранах її необхідно зробити фіксованою – шириною 200 пікселів, а на великих – 800 пікселів. Ви можете зробити це, вказавши @media, які застосовуватимуться, залежно від розмірів області перегляду. Проблема в тому, що @mediaбудуть розмножуватися разом із зростанням проекту і підтримувати це стане складно.
Ви можете змінити ситуацію, використовуючи функції min, maxта clamp. З їх допомогою код легко реорганізується в:
article {
width: clamp(200px, 50%, 800px);
}
Тут 200px– мінімальне значення, 800px– максимальне, а 50%– переважне.
Використовуйте aspect-ratio
Наступна порада для тих, хто вставляє на сторінки адаптивні зображення або відео, які підтримують певне співвідношення сторін, наприклад 16:9.
Щоб усе нормально відображалося, завжди доводилося додавати зверху відступ padding-top: 56.25%, а потім задавати дочірньому елементу абсолютне позиціонування.
Але це можна спростити, використовуючи таку властивість video, як aspect-ratio. У нашому випадку – aspect-ratio: 16/9.
video {
width: 100%;
aspect-ratio: 16 / 9;
}
Задавайте змінні користувача
Ми часто використовуємо те саме значення кольору в декількох місцях на сторінці. Якщо потрібно змінити колір, доводиться змінювати кожен рядок коду, який посилається на нього.
Але набагато простіше визначити докорінно глобальну змінну, на яку можна буде посилатися скрізь, де це необхідно. Якщо доведеться змінити цей колір, потрібно буде поміняти лише один рядок.
:root {
--main-color: hsl(0, 100%, 50%);
}
p {
--main-color: green; /* переопределение, как в обычном css */color: var(--main-color);
}
h1 {
color: var(--main-color);
}
h2 {
color: var(--main-color);
}
Змінні каскадуються, як і решта CSS. Це означає, що будь-яку глобальну змінну можна поставити докорінно, але перевизначити глибше в дереві. Також змінні можна комбінувати для складання складніших значень. Наприклад, колір RGB можна визначити на основі трьох інших змінних.
Раніше використання змінних було прерогативою препроцесорів CSS, дуже приємно, що такий корисний інструмент перекочував і в сам CSS. До речі, нещодавно в CSS з’явився і nestling (раніше він також існував лише в препроцесорах).
Використовуйте просту математику
CSS насправді не є мовою програмування у традиційному сенсі. Але в ньому є можливість виконувати базові обчислення за допомогою функції calc, де доступні деякі базові математичні обчислення. Але найцікавіше, що у цій функції можна комбінувати різні одиниці виміру. Наприклад, можна відняти 50 пікселів із поточної ширини області перегляду.
Допустимо, в коді є анімація, в якій елементи падають зверху. Але ми хочемо їх упорядкувати, щоб вони з’являлися один за одним. Один із способів досягти цього — застосувати різну затримку анімації для кожного окремого елемента.
Але за великої кількості елементів таке важко організувати в коді. Складніший підхід — визначити вбудовану змінну CSS для порядкового номера кожного елемента. З її допомогою можна визначити затримку анімації як порядковий номер, помножений на 100 мілісекунд. Так можна обробляти безліч елементів, не збільшуючи обсяг CSS.
Вище ми згадували, що CSS не є повноцінною мовою програмування, але насправді в неї вбудований механізм керування станом. Ви можете відстежувати поточну позицію у своєму CSS-коді, не написавши жодного рядка JavaScript.
Відмінний приклад – нумерація заголовків. Простий спосіб зробити це — вручну додати ці цифри до самого HTML. Але якщо ви будь-коли захочете додати новий заголовок, доведеться перенумерувати все вручну.
Більш розумний підхід – лічильник CSS. Він створюється через властивість скидання лічильника ( counter-reset). Йому можна дати будь-яке ім’я, а потім збільшувати щоразу, коли застосовується потрібний селектор за допомогою counter-increment. Такий лічильник почнеться з 0 і щоразу збільшуватиметься на одиницю.
Можна подумати, що при створенні складного меню, що розкривається, для керування відкритим і закритим станом повинен використовуватися деякий JavaScript. Але тільки з CSS також можна просунутися досить далеко.
Швидше за все, ви знайомі з псевдокласом focus, який застосовується до елемента, коли ви вводите форму або натискаєте кнопку. Його можна використовувати, щоб відкрити меню. Але при натисканні на щось всередині меню втрачає фокус і закривається. Саме в цей момент зазвичай використовується JavaScript для керування станом.
Однак усередині є ще один псевдоклас focus-within. Він залишається активним, якщо в результаті взаємодії з елементами на сторінці фокус зберігся у будь-яких дочірніх елементів меню. Так що в цьому випадку можна взагалі не використовувати JavaScript для включення та вимкнення станів.
Використовуйте відносні одиниці
Коли можливо, замість статичних значень пікселів використовуйте відносні одиниці.
При розробці адаптивних макетів у вас можуть бути заголовки або контейнери з фіксованими полями та відступами. Ви змінюєте їх на екранах меншого розміру за допомогою @media.Якщо у точному дотриманні розмірів цих полів немає потреби, це overhead. Підтримувати таке складно, плюс це не дуже добре працює на пристроях, що автоматично масштабують шрифти під розмір екрану.
Замість фіксованих одиниць, на зразок пікселів, можна використовувати відносні – emабо rem:
em– автоматично розрахує розмір, спираючись на шрифт елемента (а оскільки розмір шрифту успадковується та рідко перевизначається, за фактом em спиратиметься на шрифт найближчого батьківського елемента). Якщо розмір шрифту 16px, то 2em дорівнюватиме 32px;
rem– Працює аналогічно, але спирається на розмір кореневого шрифту. Цей спосіб кращий
Єдине зауваження – em та rem реагують на зміну розміру шрифту браузера. Отже, якщо хтось у своєму браузері збільшить розмір тексту, зовнішній вигляд сторінки може змінитися.
У CSS є інші відносні одиниці, зокрема ch – ширина символу. За допомогою неї можна продати один трюк.
Якщо ви справді серйозно ставитеся до дизайну, можливо, ви читали «Основи стилю в друкарні» Роберта Брінгхерста. Він каже, що оптимальний розмір абзацу становить від 45 до 75 символів. У CSS ми можемо забезпечити зразкове дотримання цього правила за допомогою функції clamp, яку згадували вище ( width: clamp(45ch, 50%, 75ch);). Так кожен абзац матиме ідеальну ширину.
Відверто кажучи 45ch– це не рівно 45 символів, а відстань, на якій можна розмістити 45 нулів. Якщо використовується моноширинний шрифт, все працює ідеально. Якщо ні, краще перевірити результат практично.
Орієнтуйтеся на кольори HSL (замість RGB)
RGB – це червоний, зелений, синій, де кожен елемент може мати значення від 0 до 255. Шістнадцятковий формат містить ту ж інформацію, але в компактнішому вигляді, який ще складніше інтерпретувати.
HSL – це відтінок, насиченість та яскравість. І такий формат спрощує обчислення гарної палітри кольорів. Просто виберіть насиченість і яскравість, а потім збільште відтінок на певну величину, наприклад, на 25. Так можна отримати кілька кольорів, поєднання яких виглядає добре. Ще простіше за допомогою HSL затемнити або висвітлити елемент інтерфейсу. На відміну від RGB, для цього не доведеться ставити окремий колір.
Не забувайте виправити прокручування
На веб-сайтах з фіксованою навігаційною панеллю часто зустрічається одна проблема. Коли ви переходите до якірного посилання, сторінка автоматично прокручується, але потрібний заголовок закривається фіксованою навігаційною панеллю.
Щоб цього уникнути, виправте властивість scroll-padding, яка додасть додатковий відступ.
PS Рука не піднялася оголосити це окремою порадою, але в оригінальній добірці автори рекомендували використовувати емодзі як імена класів. З їхньої точки зору так код стане більш читаним.
Як це випливає із самої назви, монолітний блокчейн — розподілена система з єдиною структурою. У ній ноди відповідають за консенсус, виконання транзакцій та доступність даних.
На відміну від модульних, монолітних блокчейнах всі ці завдання виконуються на одному рівні або в групі тісно пов’язаних ланцюгів (також працюють на одному рівні).
Більшість блокчейнів криптоекосистеми – монолітні. Наприклад, біткоін, Solana, Ethereum (на перших етапах розвитку).
Розглянемо принцип роботи монолітного блокчейну з прикладу протоколу биткоина:
Біткоїн-нода отримує транзакцію від іншого учасника мережі, перевіряє підпис та забезпечує відповідність цих даних правилам консенсусу.
Якщо транзакція валідна, нода додає її домемпул(або відхиляє її).
Майнер «дістає» транзакцію з мемпулу та додає її до блок-кандидата.
Якщо майнеру вдається знайти значенняnonceдля блоку-кандидата (як вимагають правила Proof-of-Work), з’являється можливість транслювати цей блок іншим вузлам мережі. Останні також перевіряють транзакції і, якщо все сходиться, додають новий блок у ланцюжок.
Доступність даних . Кожна нода містить копію всього блокчейна, зберігаючи кожну транзакцію. Вузол однорангової мережі може запитати дані іншого вузла.
Виконання . Усі ноди перевіряють транзакції з їхньої відповідність правилам алгоритму консенсусу. У блокчейнах на основі облікових записів (які зазвичай підтримують смарт-контракти) вузли виконують транзакції для обчислення нового стану мережі.
Консенсус . Ноди «домовляються» між собою, які транзакції будуть оброблятися для нових блоків та їх порядок.
Врегулювання чи вирішення спорів (settlement) . Ця функція гарантує незворотність підтверджених транзакцій та забезпечує арбітраж у разі заперечення їх валідності.
Архітектура монолітних блокчейнів передбачає, що ноди виконують усі ці функції. У модульних системах виконання відокремлено від врегулювання, консенсусу та доступності даних.
Що таке модульні блокчейни?
Модульний підхід знаменує собою кардинальну зміну парадигми під час побудови блокчейнів. Суть полягає у спеціалізації: один блокчейн відповідає за виконання транзакцій, інший за підтримку консенсусу.
Таким чином, модульний блокчейн сфокусований на виконанні лише деяких завдань, передаючи інші одному або декільком окремим рівням. Компоненти таких систем можна подати у вигляді кубиків Lego, які можна комбінувати для створення різних конструкцій.
Модульні блокчейни являють собою модулі, що підключаються, кожен з яких може замінюватися або об’єднуватися з іншим залежно від конкретного юзкейсу.
Приклад таких модулів – роллапи. Ці рішення масштабування спеціалізуються з обробки транзакцій (виконанні). За консенсус, доступність даних та врегулювання відповідає батьківський ланцюжок.
Як працюють модульні блокчейни?
Розглянемо принцип роботи Ethereum у контексті модульного підходу. Як і біткоїн, а також багато інших блокчейнів першого покоління, мережа другої за капіталізацією криптовалюти була спроектована як монолітна система. Однак для вирішення трилеми масштабування ефір перетворюється на модульну структуру.
Один із важливих етапів на цьому шляху – реалізація шардингу. Ідея полягає в поступовій відмові від моделі, де кожна нода має обчислювати кожну операцію, на користь моделі паралельного виконання, в якій ноди обробляють лише певні обчислення. Це дозволяє обробляти безліч транзакцій одночасно.
Шардинг розбиває блокчейн на кілька підмереж, кожна з яких обробляє свою частину активності. Розділяючи функції на кілька компонентів, досягається більш висока ефективність і продуктивність, ніж якби всі частини системи працювали над тими самими завданнями.
Ethereum-розробники впроваджують систему із 64 компонентів (шардів), що працюють паралельно. Ноди управляють лише частиною реєстру, яку вони закріплені (виконують процеси і підтверджують транзакції), а чи не підтримують весь реєстр.
У контексті модульного підходу шардчейни зберігають різні частини даних Ethereum. Сегментування виконання дозволяє кожному із 64 компонентів обробляти власний набір транзакцій. Такий підхід допомагає збільшити пропускну спроможність системи та підвищити швидкість виконання операцій.
Деякі розробники є прихильникам орієнтованого на роли підходу до підвищення продуктивності Ethereum.
На відміну від інших (більш централізованих) рішень масштабування на кшталт сайдчейнів, роллапи тісно пов’язані з батьківським ланцюжком. Вони представляють своєрідне розширення для поліпшення пропускної спроможності системи.
Завдяки ролапам блокчейн Ethereum «передає на аутсорсинг» обчислення, фокусуючись на врегулюванні, консенсусі та доступності даних.
L2-рішення здатні кардинально оптимізувати обробку транзакцій без шкоди безпеці або децентралізації системи.
Які переваги та недоліки у монолітних блокчейнів?
Монолітні блокчейни – історично перший підхід до побудови розподілених систем. Однак за такої схеми складно вирішити проблему масштабування, не пожертвувавши безпекою чи децентралізацією.
Основна перевага монолітних блокчейнів полягає у їх простоті. З однорівневим дизайном менше складнощів при створенні та обслуговуванні системи. Такий підхід також зрозуміліший для новачків, які намагаються розібратися в особливостях технології.
Головні недоліки монолітних блокчейнів:
низька пропускна здатність , що впливає на ефективність системи. Для підвищення продуктивності розробники можуть зменшувати інтервал між блоками та збільшувати їх розмір. Це передбачає більш високі вимоги до обладнання для нід. Як результат, зменшується кількість нід, здатних валідувати ланцюг, що загрожує централізацією та пов’язаними з нею ризиками;
обмежена гнучкість . Впровадження змін та покращень у монолітних блокчейнах може виявитися складним завданням – систему непросто оптимізувати без досягнення компромісу з іншими її аспектами. Така негнучкість породжує труднощі адаптації мережі до потреб і технологічним досягненням;
безперервне зростання розміру блокчейна з часом, що з необхідністю зберігання всіх транзакційних даних. Внаслідок цього підвищуються вимоги до обладнання, створюючи ризики для децентралізації;
обмежений контроль . Програми повинні дотримуватись визначених правил мережі, в якій вони розгорнуті: парадигмі програмування, можливостям реалізації хардфорків, культурі спільноти тощо;
можливі труднощі залучення майнерів або валідаторів , від яких залежить безпека мережі.
«Накладні витрати при розгортанні монолітних блокчейнів високі. Що ще гірше, фрагментується безпека, оскільки кожен ланцюжок має завдання зі створення власного набору валідаторів. Якщо ми хочемо інтернет блокчейнів, не можна, щоб кожен із них забезпечував власну безпеку», — зазначають представники проекту Celestia.
За їх словами, фрагментація через відносну закритість монолітних блокчейнів може створювати перешкоди інтероперабельності, ускладнювати життя розробникам і негативно позначатися на досвіді користувача.
Які переваги та недоліки у модульних блокчейнів?
З плюсів модульних блокчейнів можна виділити:
масштабованість завдяки тому, що обробка транзакцій та інші ресурсомісткі завдання покладаються на L2-мережі. Останні здатні обробляти великі обсяги ончейн-операцій без шкоди для безпеки чи децентралізації;
високий рівень безпеки та децентралізації , що забезпечується базовим рівнем;
гнучкість та сумісність з іншими L1- та L2-системами, що дозволяє розробникам легко запускати різні мережі та віртуальні машини, включаючи EVM;
хороший користувальницький досвід. Зокрема, модульний дизайн дозволяє досягти високого рівня інтероперабельності. Це дозволяє розробникам створювати універсальні програми, знижувати вхідні бар’єри для новачків та спрощувати взаємодію для існуючих блокчейн-користувачів;
перспективність . Модульні блокчейни краще адаптуються до змін та покращень технології. Виносячи окремі функції інші рівні, ланцюжка легше оновлювати, не надаючи істотного впливу всю систему;
рівномірне розподілення безпеки між мережами модульної системи.
суверенність . Програми на основі монолітних блокчейнів пов’язані з певним набором правил (технічні аспекти, мова програмування для створення смарт-контрактів, соціальний консенсус тощо). У контексті модульних систем розробники можуть вільно вносити зміни в технологічний стек, наприклад, для створення більш ефективного середовища виконання або зміни механізму обробки транзакцій.
складність . Розробка та обслуговування багаторівневої архітектури модульних блокчейнів може виявитися непростим завданням. Складність подібних систем — потенційний бар’єр і для новачків індустрії, які тільки починають розбиратися в нових технологіях;
не настільки довгий послужний список у порівнянні з монолітними блокчейнами. Багато модульних систем ще доведеться довести свою життєздатність;
ризики, пов’язані з безпекою . Якщо неефективний рівень, який відповідає за консенсус і доступність даних, модульна система може вийти з ладу;
потенційно низький попит на криптоактиви деяких модульних блокчейнів через їхнє обмежене застосування. Наприклад, відповідальний за консенсус і доступність даних рівень, швидше за все, менш активно використовуватиме власний utility-токен, ніж у випадку з рівнем виконання.
Які приклади модульних блокчейнів?
Celestia та Polygon Avail
Celestia — один із найвідоміших представників модульних блокчейнів. У жовтні 2022 року проект залучив $55 млн у раунді під керівництвом Bain Capital Crypto та Polychain Capital.
Блокчейн дозволяє ролапам та іншим модульним ланцюжкам використовувати Celestia для забезпечення доступності даних та консенсусу. Ноди можуть підтверджувати доступність даних без необхідності завантаження всього набору конкретного блоку.
Архітектура Celestia розроблена таким чином, щоб дозволити її вузлам одночасно досягати консенсусу в різних мережах при виконанні офчейн транзакцій.
Чіткий поділ рівнів консенсусу та виконання дозволяє Celestia зосередитись на створенні організованого та системного підходу до зберігання даних, залишаючи виконання транзакцій окремим ланцюжкам.
У березні 2023 року компанія виділила розроблену модульну структуру Rollkit для підтримки роліпів на блокчейні біткоїну в окремий напрямок бізнесу.
Восени 2023 розробники Celestia запустили мейннет Lemon Mint, а токен TIA почав торгуватися на ряді великих бірж.
Проект Polygon розробляє подібне модульне рішення – Avail. Воно призначене для зниження навантаження на блокчейни за рахунок перенесення даних та підвищення масштабованості «в усіх напрямках».
Avail позиціонується як шар доступності даних для Optimism, Validium та інших рішень на базі доказів з нульовим розголошенням , які працюватимуть поверх нього. Технологія дозволить розміщувати та підтверджувати доступність даних поза мережею, виступаючи ключовим компонентом концепції модульної мережевої структури.
“Avail спеціалізується на впорядковуванні транзакцій і збереженні їх доступності, не займаючись валідацією, як це відбувається в типових блокчейнах”, – пояснив співзасновник Polygon Анураг Арджун.
Рішення дозволяє створювати довільні блокчейни з будь-яким середовищем виконання (EVM,wasmта інші) без шкоди для децентралізації чи безпеки.
Ролапи
Як згадувалося, роллапы працюють у контексті модульного підходу. Optimistic rollups використовують Optimistic Virtual Machine, а ZK-rollups – zkEVM як рівень виконання (смарт-контракти, обробка транзакцій).
Обидва типи роллапів покладаються на Ethereum для інших важливих функцій:
доступність даних та консенсус . Ролапи публікують дані транзакцій до основної мережі як CALLDATA;
врегулювання . Усі об’єднані транзакції фіналізуються до Ethereum. Що стосується ZK-rollups це відбувається після верифікації докази з нульовим розголошенням. У контексті Optimistic rollups пакети транзакцій за замовчуванням вважаються валідними, а транзакції перевіряють лише якщо хтось її оскаржив.
Validium
Технологія масштабування під назвою Validium має багато спільного із ZK-rollups. Її особливість у тому, що транзакції виконуються офчейном. Потім система відправляє дані пакетами (батчами) у батьківський ланцюжок разом із доказом валідності.
У таких платформах може використовуватися структура типу «комітету доступності даних» (DAC) або окремої мережі на базі Proof-of-Stake як у випадку з Celestia.
Таким чином, модульний стек Validium складається з таких елементів:
рівень виконання;
рівень врегулювання та безпеки (батьківський ланцюжок);
рівень доступності даних та консенсусу (DAC або окрема PoS-мережа).
Приклади систем на базі Validium (відповідно до L2Beat): Immutable X, ZKFair, ApeX, rhino.fi, Sorare.
Стиснення css класів. Як зробити веб ще швидше. Next.js
Довгі роки точилися суперечки, як краще називати класи – по бему, за цілями, за компонентами або як завгодно, але з додаванням хеша. І це дійсно важливе питання, який спосіб буде комфортний у розробці великого проекту, що розвивається. Але що ці способи означають для користувача, чи потрібні йому ці класи і як вони пов’язані з його досвідом?
Часом, заходячи в стилі проектів, я мимоволі лякаюся довжині імен, що склалася – модуль, блок, елемент, поделемент, модифікатор 1, модифікатор 2. БЕМ дійсно чудовий і я не збираюся його заперечувати, але його розміри залишають бажати кращого.
Довгі класи збільшують вагу сторінки, це означає збільшення часу завантаження найголовнішого для рендеру сторінки – документа і файлу стилів, від яких безпосередньо залежать метрики FCP, LCP.
Це стало однією з причин, чому я довгий час задивляюся на модулі (на додаток до ізоляції стилів та їх зберігання там, де вони використовуються).
Модулі дають можливість називати класи коротшими, тільки під поточний компонент, зберігаючи при цьому зручність розробки. Але тепер до класів додаються хеші, роблячи їх довшими, а отже перевага не така, як хотілося б. Тому нарешті до теми статті.
Стиснення імен класів
Отже, які є методи скоротити класи:
Називати класи коротше (Спасибі, Кеп, так);
Називати класи повноцінно, але при складанні залишати лише хеш;
Називати імена за певним правилом чи алгоритмом.
Перший спосіб не підходить для чогось більшого, ніж to-do лист – зробивши класи занадто короткими ми або втрачаємо DX, або ризикуємо перетину.
Для другого і третього способу, css-loader пропонує властивість localIdentNameдля модулів.
Підібравши правило можна значно скоротити розмір класів, але все ж таки, значно не одно максимально. Максимальним зменшенням імен класів буде збереження символів – .a, .b, .c, …, etc.
Таким підходом користуються, наприклад, Google, Facebook, Instagram
Щоб реалізувати таке рішення, нас цікавить властивість getLocalIdent, яка дозволяє передавати функцію для генерування імені. Також можна використовувати такі пакети як posthtml-minify-classnames або mangle-css-class-webpack-plugin .
На цьому можна було б завершувати статтю, якби не одна деталь. Я використовую next.js.
Рішення
Next.js має кілька особливостей, які не дозволяють використовувати ці рішення. Найбільш очевидною особливістю є те, що він не дає можливості налаштувати getLocalIdent зовні.
Саме тому я, 3 роки тому зробив пакет next-classnames-minifier. У ньому я реалізував алгоритм підбору імен та налаштував вбудовування getLocalIdentу потрібні правила у вебпаку. За наступні роки пакет трохи оновлювався, але було в ньому те, що не дозволяло мені назвати його завершеним і готовим для використання в комерційних проектах.
Головною проблемою була необхідність щоразу видаляти папку зібраного додатка та кешу в ci, що, безумовно, дуже позначалося на зручності розробки. І це друга особливість Некста – його система кешування.
Якщо компонент зібрався, то при наступному запуску режиму розробки або збирання він може не перезбиратися. Тобто при перезапуску, алгоритм починав працювати з чистого листа і генерував класи з найпростіших імен ( .a, .b, .c), але в ряді компонентів і стилів, що не перебираються, такі імена були додані при минулому запуску.
З цієї причини рішення і не включене до next.js
Потоваришувати з Next.js
Очевидно, критично важливим завданням було позбавити проблеми очищення кешу. І рішення знайшлося. Тепер пакет, подібно до next.js, кешує результати – згенеровані імена – і при кожному запуску відновлює їх з кешу, аналізуючи їх та перевіряючи їхню актуальність.
При цьому швидкість збірки не стала довшою, адже пакет використовує все той же оптимізований алгоритм підбору імені, а за рахунок кешування пакет працює ще швидше [ ніж базове створення імен з генеруванням хешу ].
Ефективність
Можна знайти статті з ефективністю стиснення 30%, 50% і навіть 70%. Насправді все дуже індивідуально. Наприклад, якщо у вас був клас:
.postsListItemTitle {
font-size: 24px;
}
З нього вийде:
.j1 {
font-size: 24px;
}
21 символ ( .j1{font-size: 24px;}) замість 44 ( .postsListItemTitle__h53_j{font-size: 24px;}) – економія 52%. Цей клас використовується в 20 картках на сторінці, що зменшує вагу та html.
У середньому, мабуть, можна говорити про зменшення ваги css на 10-20%.