“У комп’ютерній науці всі проблеми можуть бути вирішені за допомогою додаткового рівня непрямості,” – Девід Вілер
Типи даних – це природно
Людина є істотою з дуже розвиненим образним мисленням. Саме наша здатність до створення абстракцій та узагальнення прожитого досвіду стала ключем до розвитку цивілізації. Ми користуємося цими здібностями від народження, навіть не замислюючись. Наприклад, ми з дитинства працюємо з різними типами даних, діючи швидше інтуїтивно, не даючи їм формального опису. Ми знаємо, що числа можна складати і множити, а зі слів складати речення. Навряд чи нам спаде на думку спробувати перемножувати слова. Таким чином, ми розуміємо, коли бачимо написані символи (літери, наприклад), що ми можемо і чого не можемо робити з цими символами, а також знаємо набір допустимих значень символів — наш алфавіт. У прикладі літери — і є тип даних. Ми знаємо безліч значень літер — вони є алфавітом. Крім того, знаємо, що літери ми можемо складати слова – це операції. Це природне уявлення людини лягло основою формального визначення типу даних.
Тип даних – безліч значень та [допустимих] операцій над цими значеннями.
Хоча ми в житті не використовуємо це визначення і навіть не замислюємося про це, кожен день ми стикаємося з різними типами даних: літери, цифри, предмети побуту, продукти харчування. Але навіть при вирішенні побутових питань може виникнути ситуація, коли наявних у розпорядженні простих типів даних може бути недостатньо.
Уявіть собі такий діалог матері та маленького сина років трьох, який ще не дуже освоїв абстрактне мислення:
— Синку, принеси, будь ласка, зі столу ручку, мені треба записати щось!
– Мамо, тут немає ручки!
– Тоді олівець.
– І олівця немає.
– А що є?
— Фломастери є й маркер.
– Ну, тоді неси фломастер!
Доросла людина швидше за все відразу принесла б фломастер і сказала: «ручки не було, думаю, фломастер пригодиться». Чому? — Тому що з якогось рівня розвитку абстрактного мислення та вміння взаємодіяти з іншими людьми людина вже розуміє, що в цьому проханні головне не конкретний тип об’єкта — ручка — а її властивість писати по папері. Таку ж властивість мають й інші об’єкти: олівці, фломастери, маркери, навіть шматочок вугілля. Таким чином, він машинально поєднує кілька типів інструментів в один тип: те, чим можна писати. Це вміння часто спрощує нам повсякденне життя та спілкування з оточуючими, при цьому дещо віддаляючи нас від конкретних фізичних об’єктів. Щоб дістатися роботи, ми використовуємо «громадський транспорт» — маршрути та конкретні вагони чи машини можуть бути різними, але головне, що вони мають потрібні нам властивості: ми можемо увійти, вийти, сплатити за проїзд, ми заздалегідь впевнені в тому, що це можна зробити з кожним з об’єктів цього типу. Коли ми в незнайомому місті хочемо сходити в кафе, ми запитуємо у друзів або в інтернеті: «де в місті Н можна смачно поїсти?», тобто ми не визначаємо конкретний заклад, навіть його тип, а ставимо в основу найважливішу властивість групи закладів: ми можемо прийти туди та замовити їжу.
Іншими словами, у деяких ситуаціях нам важливий не об’єкт конкретного типу, а певні його властивості: тобто, що ми можемо з ним робити. Часто шуканими властивостями володіють кілька типів даних, і всі вони нам так чи інакше підійдуть, як описані вище приклади. Це призводить до визначення абстрактного типу даних. Спочатку наведемо формальне визначення, а потім розкриємо його у більш простих термінах.
Абстрактний тип даних (АТД) – це математична модель для типів даних, де тип даних визначається поведінкою (семантикою) з точки зору користувача даних, а саме в термінах можливих значень, можливих операцій над даними цього типу та поведінки цих операцій.
Що таке математична модель? Хто такий користувач даних? Що мають на увазі під поведінкою операцій? Навіщо взагалі так ускладнювати? Давайте розумітися.
Заглиблюємося в деталі та розбираємо приклади
Щоб не перевантажувати себе новою інформацією, давайте будемо під математичною моделлю об’єкта або явища розуміти просто його формальний опис. Повертаючись, наприклад, з мамою, якій знадобилася ручка, ми можемо переробити її прохання в такий спосіб: «Сину, принеси мені, будь ласка, якийсь інструмент, який може залишати контрастні сліди на папері і при цьому поміщається до мене в руку». Звучить на побутовому рівні досить абсурдно, але саме це і буде формальним описом того, що знадобилося мамі.
Рухаємось далі. Уявімо програміста, перед яким стоїть завдання створення системи електронної черги в травмпункті.
При надходженні до травмпункту людині видається талон з номером (порядковим номером відвідувача травмпункту) та визначається пріоритетність черги: його травма оцінюється за шкалою від 1 до 10, де 10 – травма, яка потребує негайної медичної допомоги. Необхідно реалізувати механізм додавання людини до черги та визначення наступного пацієнта на прийом.
Для вирішення такого завдання потрібно створити програму, яка використовуватиме в коді деякі дані: номери талонів та їх пріоритети. У коді програми будуть проводитись операції над даними. Як ви побачите далі, ці операції не завжди прості, а можуть містити в собі безліч дій, а також мати деякі наслідки для всієї програми і всіх даних, що зберігаються: важкий пацієнт посуне всю чергу назад, тому що йому потрібна термінова медична допомога. Все в сукупності: набори операцій, дії, з яких вони складаються, а також їх наслідки називаються поведінкою операції.
Під користувачем даних ми в цій статті розумітимемо програміста, який використовує ці типи даних у своєму коді.
Залишається найважливіше питання: навіщо все це потрібне? Щоб відповісти на нього, розглянемо завдання докладніше.
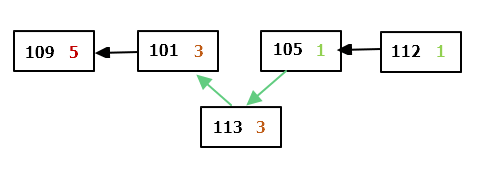
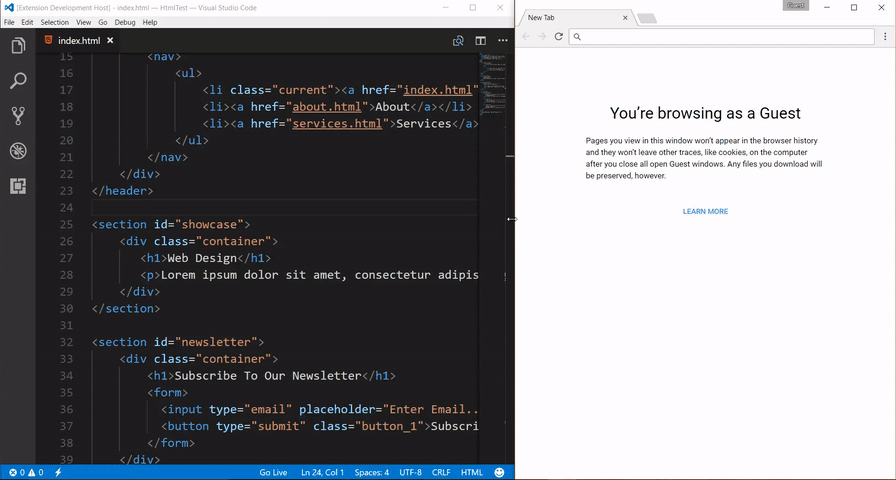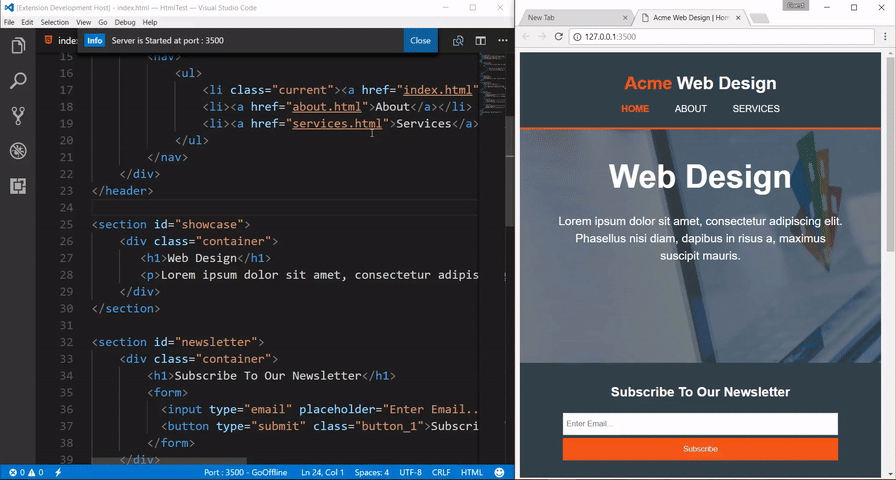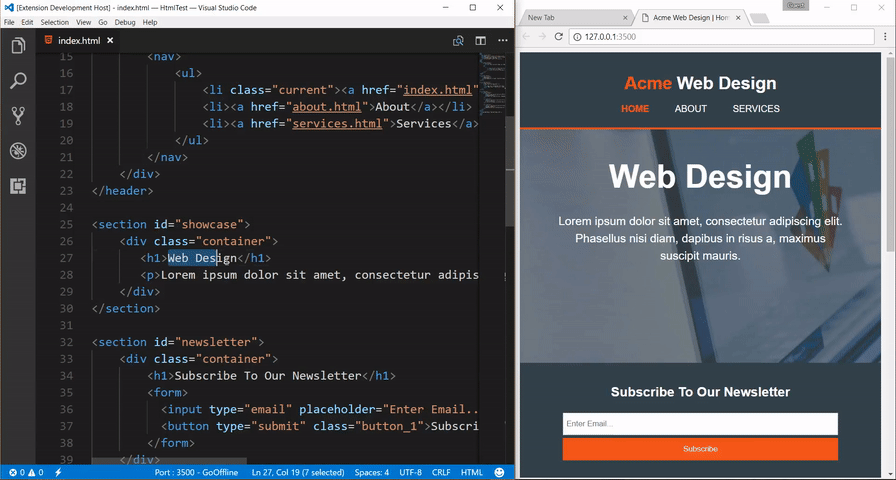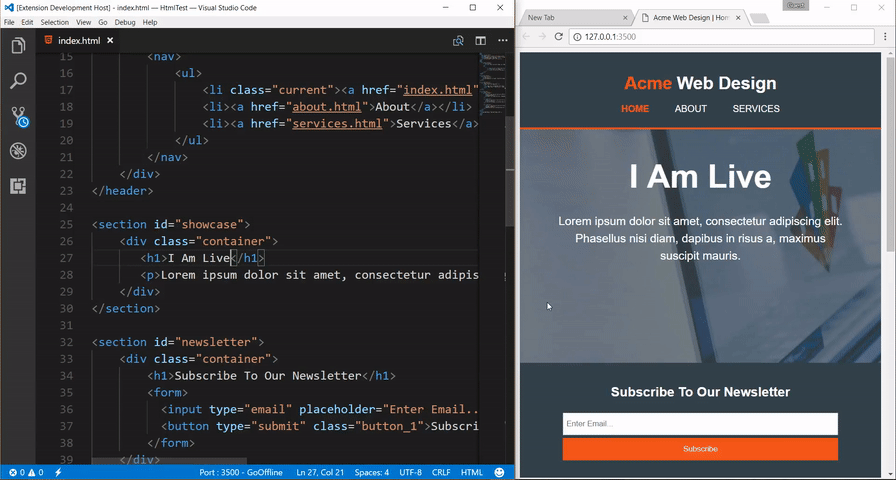
Уявимо, що у черзі вже є талони з номерами 109, 101, 105, 112 з пріоритетами 5, 3, 1, 1 відповідно. Наступному пацієнту видається талон 113 з пріоритетом 3. Тоді цей талон «обходить» номери 105 і 112, тому що їхній пріоритет нижче, і встає позаду талона 101, з яким їх пріоритети рівні (мал. 1). Коли лікар готовий прийняти наступного пацієнта, то буде викликано пацієнта з номером 109 (мал. 2).
Мал. 1. Новий пацієнт у черзі. Мал.2. Вибір наступного пацієнта у черзі.
Давайте напишемо код, який реалізує цю логіку. Будемо використовувати мову javascript . Спочатку опишемо звичайну чергу, без урахування пріоритету. Створимо клас PriorityQueue. Об’єкти цього класу міститимуть спочатку порожній масив data(створюється в конструкторі). Функція add_elemдодаватиме переданий їй параметр – номер талона – в кінець масиву data, а функція get_nextописуватиме виклик лікарем пацієнта на прийом: повертати значення першого елемента в масиві – номер пацієнта, який встав у чергу раніше за всіх інших, видаляючи з масиву цей елемент, так як , вирушаючи прийом, пацієнт залишає чергу. Також визначимо функцію print_que, яка виводитиме в консоль усі елементи черги по порядку.
Давайте модифікуємо клас, що вийшов, щоб черга враховувала пріоритет елемента. Для цього будемо в масиві dataзберігати не просто переданий елемент, а об’єкт із двома полями: значення ( value) та пріоритет ( priority). У коді такий об’єкт задаватиметься виразом виду var obj = {‘priority’: 1, ‘value’: 112};Перепишемо функцію додавання елемента в чергу:
add_elem(e,p) {
for (var i = this.data.length - 1; i >= 0; i--) {
if(this.data[i].priority >= p){
this.data.splice(i+1,0,{'value':e, 'priority':p});
return;
}
}
this.data.splice(0,0,{'value':e, 'priority':p});
}
Змоделюємо ситуацію, проілюстровану малюнками 1 і 2.
Можлива модифікація: якщо пацієнт перебуває в черзі протягом тривалого часу, наприклад, за цей час лікар уже прийняв як мінімум одного пацієнта з черги, то пріоритет його талона підвищується на 1, проте не може перевищити 8, щоб залишити можливість термінового прийому важких хворих.
Для цього змінимо функцію вибору наступного елемента get_next.
get_next() {
var e = this.data.shift();
for(var i inthis.data){
if(this.data[i].priority<8)
this.data[i].priority++;
}
return e;
}
Можемо помітити, що в даному випадку при вилученні елемента з черги змінюються всі елементи. Це і буде та сама «поведінка операції», про яку йшлося раніше.
Код програми, що вийшов, можна умовно розділити на дві частини: опис класу PriorityQueue і використання цього класу. Зауважимо, що використання класу виглядає досить лаконічно, порівняно з його описом. Працюючи з класом та її функціями програміст, який виступає у разі як користувач класу, може мати уявлення, як саме реалізована логіка роботи всередині функцій класу. Для його роботи достатньо того, що ця логіка відповідає заявленому опису пріоритетної черги. У такому разі кажуть, що клас реалізує певний інтерфейс – набір методів роботи з класом, де зафіксовано вхідні та вихідні параметри. У цьому прикладі це методи add_elem, get_next і print_queue. Можна змінити внутрішню логіку роботи цих методів, якщо цього вимагатиме завдання, як це було у разі підвищення пріоритету при довгому очікуванні. Однак для користувача класу ці зміни не будуть помітними і не вимагатимуть зміни коду основної програми.
Бонус. Що таке структура даних?
У програмуванні також є поняття структури даних, яке певною мірою близьке за змістом типу даних.
У чому різниця? Структура даних – це конкретна програмна реалізація типу даних. Якщо двох людей попросити реалізувати пріоритетну чергу, швидше за все навіть при використанні однієї мови програмування їх реалізації відрізнятимуться, хоча обидві відповідатимуть заявленому інтерфейсу. Тобто вони створять дві різні структури даних.
Структура даних (англ. data structure) — програмна одиниця, що дозволяє зберігати та обробляти безліч однотипних та/або логічно пов’язаних даних у обчислювальній техніці. Для додавання, пошуку, зміни та видалення даних структура даних надає деякий набір функцій, що становлять її інтерфейс.
Висновок
Підіб’ємо підсумки виконаної роботи. Клас PriorityQueueмає такі властивості:
Він може зберігати у собі будь-які елементи з пріоритетом, який задається числом.
Визначено інтерфейс взаємодії з класом: методи add_elem, get_nextі print_queue.
Описані методи реалізують заявлену логіку роботи пріоритетної черги.
Методи мають певну поведінку (див., наприклад, бонус).
Таким чином, ми створили свій абстрактний тип даних та реалізували його мовою javascript . Що ми від цього виграли:
Код основної програми лаконічний і зрозумілий, тому що не містить технічних подробиць внутрішньої роботи черги.
Зручно вносити зміни до логіки роботи черги, не торкаючись основного коду.
Клас PriorityQueueможе бути перевикористаний в інших програмах, де потрібна схожа логіка.
У разі командної роботи можна поділити між людьми роботу над класом та розробку з використанням цього класу. Сполучною ланкою буде інтерфейс класу.
Незважаючи на те, що розробка абстрактного типу даних сама по собі може бути досить трудомісткою, використання АТД здорово допомагає заощадити сили і час при роботі зі складними завданнями. Принцип «розділяй і владарюй» працює тут якнайкраще: створення додаткового рівня абстракції допомагає розробнику розбити складне завдання на дрібніші і простіші, а його колегам спрощує розуміння коду програми, що надзвичайно важливо в командній розробці.
Звичайно, АТД – це не панацея, яка допоможе зробити будь-який код прекрасним, читаним і зрозумілим, уникнувши всіх помилок. Дуже часто навіть досвідчені програмісти у своєму прагненні зробити все правильно та красиво заходять надто далеко в нетрі абстракцій, що навпаки все ускладнює. Коли варто створювати нову абстракцію, а коли це зайве, зрозуміти можна лише з досвідом. Універсального рецепта немає, можна лише порадити намагатися періодично переглядати свій старий код, щоб зробити висновки, що з написаного робить його зрозумілішим, а що через деякий час незрозуміло вже навіть вам самим.
Пам’ятайте, що у висловлювання Девіда Віллера і є і друга, менш відома частина:
У комп’ютерній науці всі проблеми можна вирішити з допомогою додаткового рівня непрямості. Але зазвичай це створює іншу проблему
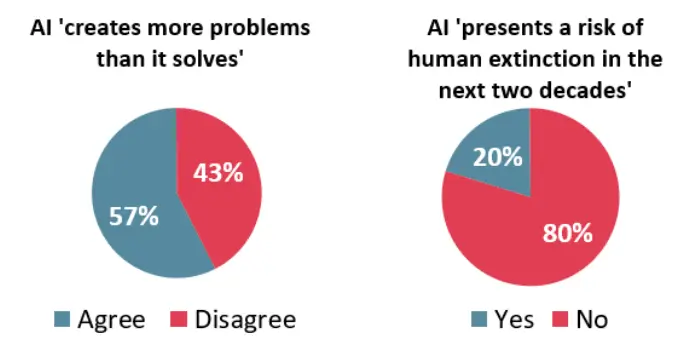
Більше 40% користувачів засумнівалися у етичному застосуванні ШІ
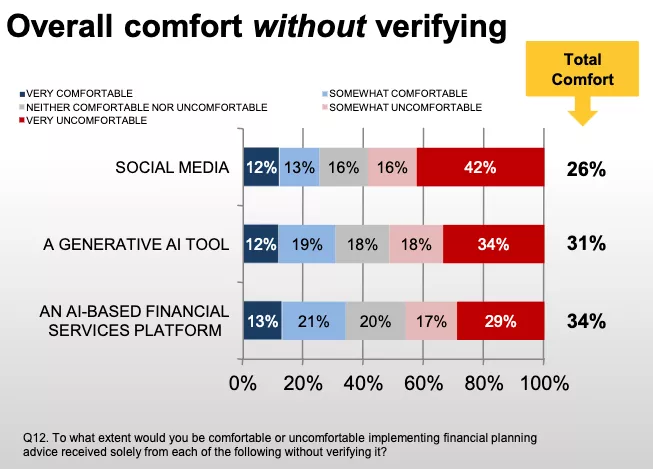
У споживачів зростає недовіра до ШІ фірм — понад 40% респондентів не вірять, що компанії використовують технологію етично. Про це свідчать результати опитування Salesforce.
У дослідженні взяли участь понад 14 000 споживачів та фірм у 25 країнах.
Майже 70% із них заявили, що в міру розвитку ШІ профільним компаніям варто підвищувати довіру до своєї діяльності.
За даними Salesforce, протягом року респонденти стали менш схильні до використання штучного інтелекту. Якщо у 2022 році понад 80% бізнес-покупців та 65% споживачів були готові використати технологію для покращення якості обслуговування — зараз обидва показники впали до 73% та 51% відповідно.
Окреме опитування майже 1500 австралійців від дослідницької фірми Roy Morgan показало, що близько 60% із них впевнені: ШІ «створює більше проблем, ніж вирішує».
Кожен п’ятий респондент пов’язує із цими розробками причину потенційного зникнення людства до 2043 року.
Дані: Roy Morgan.
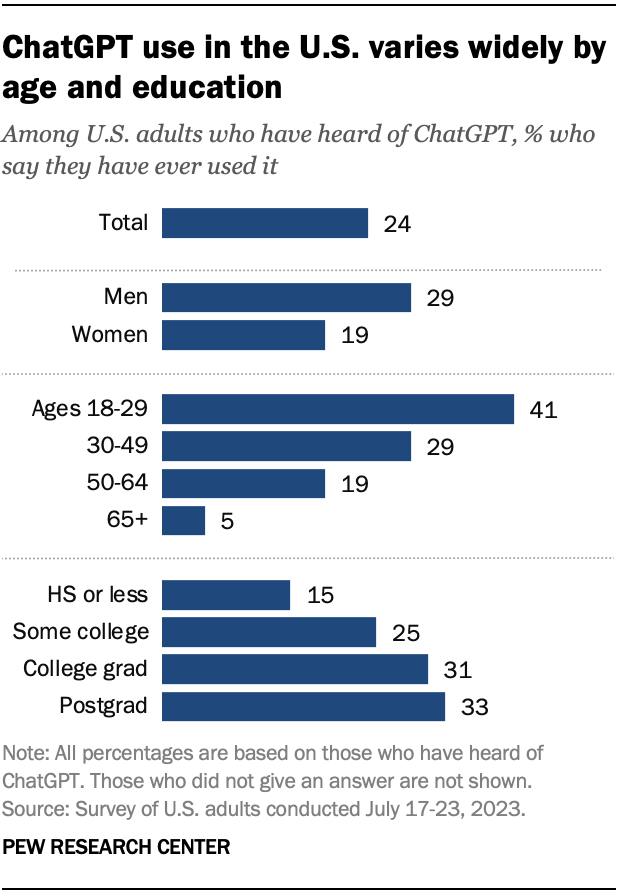
Третє дослідження від Pew Research, у якому взяли участь понад 5000 американців, виявив досить низьку поінформованість людей про ChatGPT. Лише 18% із них використали цього чат-бота.
Дані: Pew Research.
На тлі глобальних дебатів щодо необхідності законодавчого регулювання ШІ майже 70% респондентів виступили за введення більшої кількості правил.
Нагадаємо, згідно з опитуванням CFP, третина інвесторів із США довіряють фінансовим рекомендаціям від штучного інтелекту, не звіряючи їх з іншими джерелами.
Раніше LinkedIn вказав на зростання числа професіоналів із навичками роботи в галузі ШІ.
“Реактивність” – це те, як системи реагують на оновлення даних. Існують різні типи реактивності, але в рамках цієї статті реактивність — це коли ми щось робимо у відповідь на зміну даних.
Патерни реактивності є ключовими для веб-розробки
Ми працюємо з великою кількістю JS на сайтах та у веб-додатках, оскільки браузер – це повністю асинхронне середовище. Ми повинні реагувати на дії користувача, взаємодіяти з сервером, надсилати звіти, моніторити продуктивність тощо. Це включає оновлення UI, мережеві запити, зміни навігації та URL в браузері, що робить каскадне оновлення даних ключовим аспектом веб-розробки.
Реактивність зазвичай асоціюється з фреймворками, але можна багато чому навчитися, реалізуючи реактивність на чистому JS. Ми можемо змішувати та грати з цими патернами для кращої обробки оновлення даних.
Вивчення патернів призводить до зменшення кількості коду та підвищення продуктивності веб-застосунків, незалежно від використовуваного фреймворку.
Мені подобається вивчати патерни, оскільки вони застосовні до будь-якої мови та системи. Паттерни можуть комбінуватися для вирішення завдань конкретної програми, часто приводячи до більш продуктивного і підтримуваного коду.
Видавець/передплатник
Видавець/передплатник (Publisher/Subscriber, PubSub) — один із основних патернів реактивності. Виклик події за допомогою publish() дозволяє передплатникам (підписалися на подію за допомогою subscribe()) реагувати на зміну даних:
Кастомні події – нативний браузерний інтерфейс для PubSub
Браузер надає API для виклику та передплати кастомних подій (custom events). Метод dispatchEvent() дозволяє не тільки викликати подію, але й прикріплювати до неї дані:
Ми можемо обмежити область видимості (scope) кастомної події будь-яким вузлом DOM. У наведеному прикладі ми використовували глобальний об’єкт window, який також відомий як глобальна шина подій (event bus).
Наші події викликаються на класі, а не глобально window. Обробники можуть безпосередньо підключатися до цього примірника.
Спостерігач
Паттерн “Спостерігач” (Observer) схожий на PubSub. Він дозволяє підписуватись на суб’єкта (Subject). Для повідомлення передплатників про зміну даних суб’єкт викликає метод notify():
Давайте зробимо наших спостерігачів асинхронними! Це дозволить оновлювати дані та запускати спостерігачів асинхронно:
classAsyncData{
constructor(initialData) {
this.data = initialData
this.subscribers = []
}
subscribe(callback) {
if (typeof callback !== 'function') {
thrownewError('Callback must be a function')
}
this.subscribers.push(callback)
}
asyncset(key, value) {
this.data[key] = value
const updates = this.subscribers.map(async (callback) => {
await callback(key, value)
})
awaitPromise.allSettled(updates)
}
}
const data = new AsyncData({ pizza: 'Pepperoni' })
data.subscribe(async (key, value) => {
awaitnewPromise((resolve) =>setTimeout(resolve, 1000))
console.log(`Updated UI for ${key}: ${value}`)
})
data.subscribe(async (key, value) => {
awaitnewPromise((resolve) =>setTimeout(resolve, 500))
console.log(`Logged change for ${key}: ${value}`)
})
asyncfunctionupdateData() {
await data.set('pizza', 'Supreme')
console.log('All updates complete.')
}
updateData()
/**
через 500 мс
Logged change for pizza: Supreme
через 1000 мс
Updated UI for pizza: Supreme
All updates complete.
*/
Реактивні системи
В основі багатьох популярних бібліотек і фреймворків лежать складні реактивні системи: хуки (Hooks) в React, сигнали (Signals) в SolidJS, сутності (Observables) в Rx.js і т.д. Як правило, їх основним завданням є повторний рендеринг компонентів або фрагментів DOM при зміні даних.
Observables (Rx.js)
Паттерн “Спостерігач” і Observables (що можна умовно перекласти як “сутні, що спостерігаються”) – це не одне і те ж, як може здатися на перший погляд.
Observables дозволяють генерувати (produce) послідовність (sequence) значень протягом часу. Розглянемо простий примітив Observable, що відправляє послідовність значень передплатникам, дозволяючи їм реагувати на значення, що генеруються:
classObservable{
constructor(producer) {
this.producer = producer
}
subscribe(observer) {
if (typeof observer !== 'object' || observer === null) {
thrownewError('Observer must be an object with next, error, and complete methods')
}
if (typeof observer.next !== 'function') {
thrownewError('Observer must have a next method')
}
if (typeof observer.error !== 'function') {
thrownewError('Observer must have an error method')
}
if (typeof observer.complete !== 'function') {
thrownewError('Observer must have a complete method')
}
const unsubscribe = this.producer(observer)
return {
unsubscribe: () => {
if (unsubscribe && typeof unsubscribe === 'function') {
unsubscribe()
}
},
}
}
}
Метод next()надсилає дані спостерігачам. Метод complete()закриває потік даних (stream). Метод error()призначений обробки помилок. subscribe()дозволяє передплатити дані, а unsubscribe()— відписатися від них.
Найпопулярнішими бібліотеками, в яких використовується цей патерн, є Rx.js та MobX .
Наш відеоплеєр має багато налаштувань, які можуть змінюватись у будь-який час для модифікації відтворення відео. Kai з нашої команди розробив значення, що спостерігаються (observable-ish values), що являє собою ще один приклад реактивної системи на чистому JS.
Значення, що спостерігаються – це поєднання PubSub з обчислюваними значеннями (computed values), що дозволяють складати результати декількох видавців.
Приклад повідомлення передплатника про зміну значення:
Передача функції кешує результат як значення. Додаткові аргументи передаються функції. Спостережені сутності, викликані функції, є передплатниками, оновлення цих сутностей призводить до повторного обчислення значення.
Якщо функція повертає проміс, значення надається асинхронно після його вирішення.
Основним недоліком цього підходу є модифікація всього DOM при кожному рендерингу. Такі бібліотеки, як lit-html , дозволяють оновлювати DOM інтелектуальніше, коли оновлюються лише модифіковані частини.
Реактивні атрибути DOM – MutationObserver
Одним із способів забезпечення реактивності DOM є маніпулювання атрибутами HTML-елементів. MutationObserver API дозволяє спостерігати за зміною атрибутів і реагувати на них певним чином:
const mutationCallback = (mutationsList) => {
for (const mutation of mutationsList) {
if (
mutation.type !== 'attributes' ||
mutation.attributeName !== 'pizza-type'
)
returnconsole.log('Old:', mutation.oldValue)
console.log('New:', mutation.target.getAttribute('pizza-type'))
}
}
const observer = new MutationObserver(mutationCallback)
observer.observe(document.getElementById('pizza-store'), { attributes: true })
Прим. пер.: MutationObserverдозволяє спостерігати за зміною не лише атрибутів, але також за зміною тексту цільового елемента та його дочірніх елементів.
Реактивні атрибути у веб-компонентах
Веб-компоненти (Web Components) надають нативний спосіб спостереження за оновленнями атрибутів:
Прим. пер.: Крім MutationObserverі IntersectionObserverіснує ще один нативний спостерігач – ResizeObserver .
Зациклювання анімації – requestAnimationFrame
При розробці ігор, при роботі з Canvas або WebGL анімації часто вимагають запису в буфер і наступного запису результатів у циклі, коли потік рендерингу стає доступним. Зазвичай, ми реалізуємо це за допомогою requestAnimationFrame:
functiondrawStuff() {
// Логіка рендерингу гри чи анімації
}
// Функция обробки анімаціїfunctionanimate() {
drawStuff()
requestAnimationFrame(animate) // Продолжаем вызывать `animate` на каждом кадре рендеринга
}
// Запускаєм анімацію
animate()
Реактивні анімації – Web Animations
Web Animations API дозволяє створювати реактивні гранульовані анімації. Приклад використання цього інтерфейсу для анімації масштабу, положення та кольору елемента:
const el = document.getElementById('animated-element')
// Визначаємо властивості анімаціїconst animation = el.animate(
[
// Ключові кадри (keyframes)
{
transform: 'scale(1)',
backgroundColor: 'blue',
left: '50px',
top: '50px',
},
{
transform: 'scale(1.5)',
backgroundColor: 'red',
left: '200px',
top: '200px',
},
],
{
// Налаштування часу
// Тривалість
duration: 1000,
// Напрямокfill: 'forwards',
},
)
// Встановлюємо швидкість відтворення у значення `0`// для призупинення анімації
animation.playbackRate = 0// Реєструємо оброблювач кліку
el.addEventListener('click', () => {
// Якщо анімацію припинено, відновлюємо їїif (animation.playbackRate === 0) {
animation.playbackRate = 1
} else {
// Якщо анімація відтворюється, змінюємо її напрямок
animation.reverse()
}
})
Реактивність такої анімації полягає в тому, що вона може відтворюватись щодо поточного положення в момент взаємодії (як у разі зміни напряму в наведеному прикладі). Анімації та переходи CSS такого робити не дозволяють.
Реактивний CSS – кастомні властивості та calc
Ми можемо писати реактивний CSS за допомогою кастомних властивостей та calc:
Як бачите, сучасний JS дозволяє досягати реактивності безліччю різних способів. Ми можемо комбінувати ці патерни для реактивного рендерингу, логування, анімації, обробки подій користувача та інших речей, що відбуваються в браузері.
Якщо ви працювали з Angular, то, напевно, зустрічалися з RxJS. Потоки, розлогі конструкції, багато аргументів у методу pipe, а кожен аргумент повертають різні функції з різною кількістю аргументів. Існують інтуїтивно зрозумілі функції типу filter або map. Перший явно фільтрує значення потоці, а другий ці значення змінює. Такі функції називають операторами. І чим глибше ви провалюєтеся в RxJS, тим більше різних операторів ви дізнаєтеся. І з часом дістаєтеся потоків потоків. Тобто замість звичайних значень такий потік емітує інші потоки. Такі потоки називають Higher Order Observables. І для роботи з такими потоками є спеціальні оператори. Можливо, ви чули, що такі оператори називають Higher Order Operators (HOO). Вони можуть вирівнювати потоки або, іншими словами, робити їх звичайним.
У цій статті я покажу, що в HOO немає нічого міфічного, і розповім, у яких випадках вам потрібно використовувати оператори вищого порядку. Зараз ви подумаєте, що це нудний лонгрід, але не поспішайте. Ми розглянемо всього 4 оператори: switchMap, exhaustMap, concatMapі mergeMap.
switchMap
switchMapОднозначно найпопулярніший з усіх. Але чому? А з однієї просто причини — цей оператор позбавляє нас від стану гонки, що дуже часто зустрічається.
У цьому коді ми знаходимо input, з яким взаємодіє користувач і підписуємось на подію input. Тобто потік search$ емітит рядка. Усередині підписки бачимо, що у кожен еміт рядка відправляється запит на сервер і відповідь сервісу виводиться у консоль.
У цьому коді можна побачити щонайменше дві проблеми:
Race state. Зазвичай при пошуку чогось користувача важливо бачити результат саме останнього запиту. Але код такого виду не дає нам гарантії, що останні дані, виведені в консоль, відповідають останньому рядку, що випускається в потоці search$.
Subscribe in subscribe та жодного unsubscribe. Є дуже хороше правило, за яким можна позбавити себе багатьох проблем, — на кожен subscrib має бути unsubscribe. Це щонайменше знизить ймовірність витоку пам’яті.
Але давайте подумаємо, як має працювати пошук:
У момент еміту рядка перевірити наявність активних запитів
switchMapгарантує нам, що ми завжди будемо отримувати результати останнього потоку та позбавляє нас race state. Ну і приємний бонус полягатиме в тому, що відмовившись від зовнішньої підписки автоматично відбудеться і відписка від внутрішньої. Профіт!
Резюмуємо. switchMapможна використовувати у випадках, коли нам важливим є результат останньої дії, наприклад, при пошуку або реалізації нескінченного скрола. Якщо всі попередні дії можуть не враховуватися, можна сміливо брати switchMap.
exhaustMap
exhaustMapОднозначно найпопулярніший з усіх. Причина мені не до кінця зрозуміла, але за допомогою нього можна реалізувати пошук, але використовуючи інший підхід.
Як і в першому випадку нам знадобилася ще одна змінна поза потоком. Це додає коду складності і якщо ми захочемо змінити поведінку потоку, все доведеться переписати. Ну і як ви вже здогадалися на допомогу нам приходить exhaustMap.
Резюмуємо. exhaustMapпотрібно використовувати у випадках, коли при активній підписці на потік інші можна ігнорувати, як у разі пошуку натискання кнопки або, наприклад, при пропуску подій початку анімації при її відтворенні.
mergeMap
mergeMap– Оператор, який об’єднує всі внутрішні потоки в один вихідний потік. Це означає, що внутрішні потоки можуть завершуватись у будь-якому порядку, і їх результати будуть об’єднані разом. І це найпростіше пояснення, яке я зміг із себе видавити.
У цьому коді ми бачимо entityId$ – це потік рядків з id певної сутності. Тут ми повинні на кожен id запросити дані щодо сутності з сервера і додати або оновити цю сутність в стор. Власне, саме це наш код і робить і вирішувати тут нема чого. Але проблеми є і в цьому випадку вони абсолютно ідентичні попереднім. Давайте спробуємо ускладнити завдання і ввести обмеження в 3 запити одночасно.
Я навіть не намагався перевіряти код на працездатність, бо написав його у редакторі тексту. Код став складно-читаним. Функція processNextмає кілька побічних ефектів усередині. А ще є додаткові змінні за межами потоку та функції. Скласти все це воєдино досить складно.
Саме такі завдання вирішує mergeMap. Давайте перепишемо перший приклад із використанням цього оператора:
У цьому коді mergeMapпідписується на кожен потік, повернутий entityService.get(id)і їх значення видає в одному єдиному потоці.
Добре, а як бути з обмеженням 3 запити в один момент часу? Виявляється, що mergeMapвже й так усе вміє. Другий аргумент у mergeMapприймає число, яке якраз налаштовує конкурентність.
Резюмуємо. mergeMapвідмінно підходить, коли ви хочете виконувати паралельні дії та поєднувати їх результати. Однак, слід бути обережним, оскільки може виникнути багато активних запитів, якщо вихідний потік випромінює значення занадто швидко.
concatMap
concatMap– Останній оператор вищого порядку. Ключова відмінність полягає в тому, що concatMap підтримує порядок виконання. Він дочекається завершення одного внутрішнього потоку, перш ніж перейде до наступного.
Щоб практично подивитися на його використання, ми можемо взяти попередній приклад і змінити до нього вимоги. Так вийшло, що нас перестало влаштовувати невпорядкованість запитів, і ми хочемо виконувати їх не паралельно, а по черзі. Тобто конкурентність має стати рівною одиниці.
Але mergeMap з конкурентністю 1 робить те ж саме, що і concatMap! Буквально. Це чудово видно у вихідному коді оператора.
Тобто використання mergeMap із конкурентністю 1 на стільки частий кейс, що його винесли в окремий оператор.
Резюмуємо. concatMapчудово підходить для ситуацій, коли порядок виконання важливий. Якщо ви хочете обробити послідовність дій без паралельної обробки, це ваш вибір.
Висновок
Високовирівневі оператори є потужним інструментом в арсеналі кожного розробника, що працює з реактивним програмуванням. Вони надають гнучкість і елегантність при обробці складних даних і дозволяють скоротити код, роблячи його більш читаним і підтримуваним.
Оператор switchMap чудово підходить, коли нам важливий лише останній результат випромінювання, наприклад, у разі пошуку у реальному часі.
exhaustMap ідеальний для випадків, коли нам потрібно ігнорувати нові об’єкти, що спостерігаються, до завершення поточного.
mergeMap дозволяє обробляти кілька вхідних об’єктів, що спостерігаються паралельно, але може призвести до перевантаження, якщо не контролювати кількість одночасних потоків.
concatMap гарантує порядок обробки, виконуючи кожен внутрішній об’єкт, що спостерігається послідовно.
При правильному використанні ці оператори можуть справлятися з безліччю реактивних завдань, будь то події з інтерфейсу користувача, HTTP-запити або навіть складні анімаційні послідовності.
Однак ключове слово тут – правильне використання . Завжди аналізуйте вимоги вашої програми та ретельно вибирайте відповідний оператор. Це допоможе уникнути небажаних побічних ефектів та створити реактивні рішення, які можуть масштабуватися та легко підтримуватися.
Реактивне програмування пропонує безліч інструментів, серед них високорівневі оператори займають особливе місце. Провівши час на вивчення та розуміння їх особливостей, ви значно можете покращити якість та ефективність вашого коду.
Третина інвесторів у США заявила про довіру фінансовим радам ШІ
Близько 31% інвесторів із США довіряють фінансовим рекомендаціям від штучного інтелекту (ШІ), не звіряючи їх з іншими джерелами. Про це свідчить опитування CFP .
Близько третини із 1153 респондентів фактично отримували поради щодо планування бюджету від нейромереж, при цьому 80% з них відзначили високий рівень задоволеності цим досвідом.
Більше половини опитаних зазначають, що їм все ж таки зручніше користуватися підказками, створеними ШІ та в соціальних мережах, якщо вони перевірені експертами. 52% відзначили бажання скористатися порадами від роботів у майбутньому.
«За останнє десятиліття кількість неперевірених інвестиційних рекомендацій на таких платформах, як TikTok та Instagram різко зросла. Інвестори мають бути обережними з порадами “фінансистів” на цих платформах. Поява інструментів штучного інтелекту, таких як ChatGPT та Bard, ще більше ускладнила перевірку інформації», – зазначив глава CFP Кевін Келлер.
Близько 50% респондентів вірять, що незабаром ШІ зможе доповнити послуги традиційних консультантів. Ще 11% вірять, що нейромережі повністю замінять їх.
Раніше опитування серед керівників служб управління корпоративними ризиками показало, що 66% менеджерів вважають генеративну ШІ загрозою для організацій.
Нагадаємо, за даними дослідження Quartz , штучний інтелект на 15% успішніше справляється з проходженням CAPTCHA, ніж живі люди.
Підбірка VS Code-плагінів для Frontend-розробників і не тільки
Одним із найбільш цінних аспектів Visual Studio Code є його розширюваність за допомогою плагінів, які значно полегшують та покращують робочий процес. У цій статті ми зібрали інструменти – від простих до просунутих – які зроблять вашу розробку більш продуктивною та приємною, дозволяючи зосередитись на творчій частині процесу.
Color Info — Надає коротку інформацію про кольори CSS. За промовчанням розширення працює з будь-яким документом css, sass, scss. Розпізнає всі основні формати кольорів, включаючи іменовані кольори. Можна налаштувати інструмент під власні завдання.
VSCode Icons — допоможе швидше зорієнтуватися серед багатьох файлів. Додає іконки папок та файлів. Немає потрібної іконки? Чи не біда — можна додати свою.
Git History — Покаже історію змін комміта, файлу або окремого рядка. Підтримує гарячі клавіші, порівняння файлів та пошук з історії.
Prettier — Автоматично форматує ваш код, приводить його до єдиного стилю, розставляє таби, пробіл і відступи. Підтримує безліч мов, фреймворків та інтеграцій.
Peacock — Зміна кольору робочої області. Ідеально підходить, якщо у вас є кілька вікон або використовуєте VS Live Share . Має велику документацію та безліч варіантів налаштування.
VS Faker – Генерує фейкові дані (адреси, імена, числа та іншу інформацію), використовуючи бібліотеку Faker. Добре підійде для швидкого тестування.
Live Server — Надає локальний сервер із функцією живого перезавантаження для свого проекту. Простий у використанні, має гарячі клавіші та безліч варіантів налаштування.
GitLens — Розширює можливості Git у VS Code. Дозволяє поглянути на кого, чому і коли було змінено рядок або блок коду, а потім перейти до історії, щоб отримати аналітичні відомості про розвиток коду.
Bookmarks — Допоможе орієнтуватися в коді, легко та швидко переміщаючись між важливими місцями за допомогою закладок. Має великий та зручний функціонал.
ESLint — Перевірка коду та виділення помилок для забезпечення узгодженості та правильності JavaScript-коду відповідно до стандартів.
Quokka.js — Забезпечує миттєве налагодження та виведення результатів JavaScript-виразів у реальному часі.
Path Intellisense — Надає автозаповнення шляхів файлів та папок. Тепер не потрібно лазити папками у пошуку потрібного файлу.
npm Intellisense — Надає підказки під час роботи з npm-пакетами.
Ринок AR-технологій швидко розвивається і, на думку деяких аналітиків, стане одним з важливих драйверів економіки вже протягом цього десятиліття. Як виглядатиме доповнене майбутнє, з якими етичними та юридичними труднощами доведеться зіткнутися і чому важливо думати про це вже зараз, говоримо з Олександрою Танюшиною — дослідницею цифрової філософії.
Доповнене та віртуальне
Де грань, яка відокремлює доповнену реальність (AR) від аналогової?
Олександра: Спочатку потрібно запитати себе, а що саме ми доповнюємо? Коли з’явився вираз «віртуальна реальність» (VR), у філософів з ним відразу виникли проблеми: саме поняття реальності начебто вже передбачає всі можливі існуючі об’єкти. Коли ми говоримо про AR, виникає ідея, що ми доповнюємо чимось фізичну реальність, в якій живемо. Але до реального можна додати лише нереальне — це збій у нашому понятійному словнику.
В побуті зазвичай згадують про девайси, які доповнюють наше візуальне сприйняття.
Олександра: Під AR ми справді маємо на увазі щось, що додається до нашого візуального сенсорного поля — віртуальні цифрові об’єкти. Але це може стосуватися будь-якого перцептивного досвіду: нюху, дотику і так далі. І дуже багато дослідників зараз говорять про те, що доповнена реальність не обмежується візуальними категоріями. Перші технології, що нагадують сучасні VR та AR, були саме мультисенсорними. У 1957 році голлівудський кінематографіст Мортон Хейліг розробив подібний пристрій, він назвав його «Сенсорома». Якщо подивитися на фотографії, що збереглися, то у нас перша асоціація буде з 5D-кінотеатром: екран, аудіальний супровід, якісь джерела запахів, кінетичні пристосування, щоб людина, яка сидить перед екраном, відчувала тактильні впливи. “Сенсорама” забезпечувала приплив абсолютно різних стимулів. Пам’ятаючи про це, ми, у тому числі як потенційні розробники, не повинні зациклюватися на зоровому сприйнятті.
Олександра: Я почала б з більш ранньої статті, в якій закладено концептуальні підстави цього поділу. Йдеться про роботу 1994 року, яку написали канадський дослідник Пол Мілгрем та японський вчений Фуміо Кушино. У ній представлено знамениту шкалу «віртуальність — реальність». Замість розмежування з’являється континуум, і технологія, що нас цікавить, виявляється десь між цими двома полюсами. Тобто віртуальна реальність повністю згенерована цифровим способом, а реальна реальність – це фізичний простір. До цієї статті були претензії, тому що вона концептуально роз’єднувала віртуальність та реальність, що посилає нас до термінологічної проблеми, про яку ми вже згадували. Тому багато філософів наполягають, що замість слова “реальність” краще говорити “фізикальність”.
Що стосується вже сучасних спроб осмислення доповненої реальності, то ми бачимо, що суто технологічно AR розвивається швидше, ніж VR, тому повноцінні VR-простори філософам здаються чимось умогляднішим.
А що з етичним протиставленням віртуальність/доповненість? Ханке у своєму маніфесті каже, що до VR прагнути не треба, бо вона призведе до атомізації, ескапізму, деградації соціальних навичок. А з доповненими технологіями ми всі разом ловитимемо покемонів, багато гулятимемо, соціалізуватимемося і настане повне благоденство. Чи не лукавить Ханке? У короткометражці Кейіті Мацуди Hyper-Reality дистопічне доповнене майбутнє, наприклад, зображено досить моторошно.
Олександра: На етичному рівні поділ віртуальної та доповненої реальностей дуже значущий. Ми припускаємо, що VR — це абсолютно новий цифровий світ, у якому можуть бути інші закони, зокрема фізичні. Але у випадку AR або XR, ми маємо на увазі, що зміни торкнуться нашого повсякденного життя. Як дійти законів, етичних та правових кодексів, які можуть існувати в доповнених просторах, — велике питання. Можливо, темна сторона AR виявиться дуже скоро. Якраз у згаданій короткометражці наочно показано: віртуальних та доповнених об’єктів у світі стає так багато, що самому глядачеві хочеться вийти з нього, поставити на паузу це коротке відео та перепочити. У ньому так багато стимулів, що вони буквально перевантажують нервову систему.
Далі можна придумати безліч сюжетів, які так само антиутопічні: люди перестають звертати увагу на фізичний світ і все більше занурюються в простір стимулів; люди без цифрових об’єктів перестають дізнаватися про своє звичне фізичне оточення і так далі. Ніхто не обіцяє, що AR стане ідеальною технологією, де нам буде зручно жити. З цієї причини до неї потрібно підходити дуже обережно, і ось саме філософи намагаються вже зараз розробити послідовний кодекс, який нам скаже, як краще взаємодіяти з новим середовищем.
Кодекс будівельника доповненої реальності
Чи є вже якісь підступи до цього склепіння правил? Що, наприклад, пропонується?
Олександра: Є етичний кодекс філософа Еріка Раміреса. Він присвячений і віртуальній технології, і технології доповненої реальності. При цьому сам Рамірес зазначає, що AR розвивається дуже стрімко і, головне, вона вже інтегрується в наші соціальні практики, тому він приділяє їй трохи більше уваги. Він описує різні положення про норми моделювання цифрових об’єктів: як вони мають виглядати, щоб, наприклад, більш менш екологічно впроваджуватися в наш звичний візуальний досвід, як їх потрібно виділяти для того, щоб людина могла легко відрізнитивіртуальний об’єкт від справжнього, фізичного об’єкта – виділяти їх кольором, робити напівпрозорими тощо. Рамірес розмірковує про те, які цифрові продукти підходять дітям, а які — іншим віковим категоріям, що можна додавати до нашого звичного сенсорного досвіду, а що не можна. Дуже цікаве дослідження. Воно, звичайно, підлягає подальшому доповненню, тому багато що ще можна вивчати, в тому числі спираючись на нові психологічні та нейробіологічні дослідження та практики безпосереднього застосування доповненої реальності. Але кодекс є, на нього звертають увагу правові інститути та розробники AR.
Складається почуття, ніби досвід майбутньої доповненої реальності повертає нас у міфологічне стан, де всі спілкуються з сутностями, які знаходяться виключно у людському суб’єктивному полі, тобто люди буквально бачать примар. Чи можна чекати на важливі наслідки від цього?
Олександра: Звісно. Дослідник медіа Нікола Лібераті придумав майже мем – «нове доповнене плаття короля». Якийсь час у багатьох з’явиться доступ до AR, але далеко не у всіх. Лібераті пропонує уявний експеримент: якась людина купує цифровий одяг, та інші користувачі її бачать, а люди, які не мають відповідних пристроїв, не бачать. Не така вже й фантастична ситуація, коли навіть інтернетом користуються далеко не всі, а окуляри змішаної реальності від Apple коштують досить дорого.
Ситуація може розвиватися і у зворотний бік. У New York Times виходила гучна стаття про те, що онлайн — це розвага для бідних, яким недоступні «справжні речі». І ми можемо уявити, що AR теж стане іграшкою для незаможних. Багаті зможуть дозволити собі справжній одяг, і доповнена сукня буде не у короля, а у бідняка.
Олександра: Цілком правильно. Ці сюжети саме про те, що спочатку VR та AR – це технології, які замінюють реальний досвід. Все це було докладно описано науковими фантастами ще в середині минулого сторіччя. Дуже розхожий антиутопічний сюжет: за допомогою доповненої реальності ми намагаємось маскувати відсутність реального статку у нашому звичному світі.
Доповнене право
Також цікаво, кому насправді будуть належати права власності на об’єкти доповненої реальності і чи можна їх оскаржити, якщо хтось розмістив такий об’єкт на твоїй ділянці?
Олександра: Якраз у це поле зараз активно вторгаються філософи, котрі займаються дослідженнями відеоігор (так звані game studies). В іграх практики присвоєння цифрових продуктів є. Нині все це переміщається у нашу реальну соціальну практику, наш світ поступово стає подібністю до відеоігри. Принаймні у правових аспектах точно.
Згадується випадок з 2017 року з покемонами у храмі, коли технологія доповненої реальності вторглася до традиційного сакрального простору, до церкви, і з цього вийшов зразковий юридичний скандал. Зовнішній спостерігач міг бачити людину, яка дивиться у смартфон у храмі. Але виявилося, що це має зокрема юридичні наслідки, цілком реальні. Що ти думаєш з цього приводу?
Олександра: Дуже складно повною мірою відрефлексувати цей випадок, тому що ми не маємо підстав у реальній правовій системі, які могли б чітко сказати, що дозволено робити з девайсами в релігійних інституціях, а що не дозволено. Існують більш менш традиційні норми суспільної поведінки, а індивідуальне цифрове користування досі не регулюється.
Є дуже цікавий кейс, пов’язаний не стільки з релігійним простором, скільки з педагогічним — школою чи дитячим садком. Припустимо, користувач за допомогою смартфона переглядає контент, який можна назвати дорослим, у дитячих освітніх закладах, але при цьому доступ до цього контенту у нього є суто індивідуальним, тільки через його пристрій. Чи є така дія підставою для санкцій чи все-таки, коли до такого контенту більше ніхто не має доступу, ми можемо говорити, що його перегляд подібний до уяви? Ніхто не може нам заборонити, наприклад, думати про якийсь дорослий зміст, перебуваючи в школі, якщо доступу до наших думок більше ні в кого немає. Тут починаються серйозні етико-моральні міркування. Прецеденту в юридичному плані поки не було, тож чекаємо, коли він з’явиться.
Поки це опосередковано екраном смартфона, є ризик, що хтось у нього зазирне, і це може бути сприйняте як порушення суспільної моралі. А коли контент транслюватиметься, наприклад, на сітківку ока? З іншого боку, на відміну від уяви, у нашого сприйняття є фізичний корелят — цифровий носій, сервер, який стримає картинку. Через нього ми можемо дізнатися, хто що бачить. Це не фантазія. Правильно?
Олександра: Так, звісно. І тут саме філософи, які особливо люблять пофантазувати, починають говорити про те, що AR – це не тільки реальність, опосередкована екраном, – ми можемо також уявити, що нам не просто транслюватимуть картинку на сітківку ока, а відправлять її безпосередньо в наш мозок за допомогою нейрочіпів. Контент сприйматиметься користувачем виключно суб’єктивно. А якщо він буде доступний, скажімо, великим корпораціям, які розробляють подібні технології, то тут йтиметься про зовсім фантастичні сюжети — залишимо це філософам, які люблять розважатися з такими умопобудовами. Але етичних побоювань вистачає і на цьому етапі.
Не реальність другого сорту
Які сюжети у філософії доповненої реальності тобі цікаві? Кого з авторів радиш почитати?
Олександра: Мені особисто особливо цікаві питання, які пов’язані з нтологією. Те, про що ми говорили раніше, — це здебільшого аспекти, пов’язані з етикою та знанням. Але якщо покопатися глибше у метафізичних проблемах, то виникне питання: а чим об’єкти доповненої реальності є на фундаментальному рівні? Що являють собою речі, які ми бачимо за допомогою наших смартфонів та AR-окулярів? Цими питаннями задаються багато філософів. Девід Чалмерс, автор книги про філософію VR, наприклад, є віртуальним реалістом. На його думку, цифрові та звичні нам об’єкти мають схожий метафізичний статус. Звичайно, з цією тезою непросто погодитися, тому численні філософи сперечаються з Чалмерсом і намагаються його спростувати.
Вважаю, що онтологія так чи інакше веде до етичних результатів. І навпаки, наші метафізичні погляди завжди є наслідком етичних переконань. Якщо звернутися до того ж Чалмерсу, він, безумовно, не тільки копається в онтології цифрових об’єктів і робить сумнівні твердження про те, що віртуальна реальність реальна, а доповнена реальність – та ж реальність, що і фізична, просто вона трохи по-іншому існує. Після цих тверджень у нього випливають розлогі розділи про те, як ми повинні з цими положеннями жити далі. Які наслідки для нашої етики, для наших соціальних повсякденних взаємодій призводять до того, що ми починаємо розуміти, як доповнена реальність стає частиною нашої звичної реальності. Тобто, це не реальність другого сорту.
Дебати по Tailwind CSS: ще один класний інструмент, відкинутий веб-пуристами
Як і React, CSS інструмент Tailwind регулярно обговорюється в колах веб-розробників. Він дуже популярний, але й має неабияку частку ненависників.
Tailwind CSS як фреймворк для розробників досить простий у розумінні. По суті, він дозволяє вам вбудовувати код CSS у ваш HTML код . Щоб, як мовиться в слогані Tailwind : ” швидко створювати сучасні веб-сайти, не залишаючи HTML “. Таким чином, це позбавляє розробників необхідності контекстно перемикатися з HTML на таблицю стилів CSS.
Власна документація Tailwind вказує на поширене заперечення проти такого підходу: хіба це не просто вбудовані стилі? Ті з вас, хто жив у 1990-х роках, напевно пам’ятають, що колись, ще до того, як відбулася революція CSS, їм доводилося додавати розмітку стилів у свої HTML-файли. Але, за словами Tailwind, його підхід «утилітарного класу» пропонує більше функціональності, ніж убудовані стилі, включаючи можливість створювати адаптивний дизайн (дизайн, адаптований для мобільних пристроїв).
Таким чином, простота використання – особливо в порівнянні з кодуванням та подальшим обслуговуванням CSS-файлу – і можливість створювати свій стиль усередині HTML є основними причинами, з яких багато розробників люблять Tailwind.
У своєму посту Метт Рікард додав як ключові переваги фреймворку наступні пункти:
можливість копіювання та вставки.
менше залежностей, менша площа.
можливість повторного використання.
Що стосується його критиків, то загальна причина їхньої неприязні до Tailwind полягає в тому, що він якимось чином «поважно ставиться до платформи, на якій знаходиться», як висловився Джаред Уайт у нещодавньому пості. Коли я запитав його про це, він вказав мені на свій попередній пост, де викладаються його конкретні критичні зауваження. Коротко підіб’ємо підсумок: він вважає, що Tailwind “просуває потворний HTML”, йому не подобається, що “CSS-файли, створені для Tailwind, є нестандартними (тобто пропрієтарними) і принципово несумісні з усіма іншими CSS-фреймворками та інструментами”, він вважає, що “Tailwind забуває про існування веб-компонентів” і, нарешті, він вважає, що це «заохочує суп із тегами div/span».
У двох словах, Tailwind має потворну розмітку і є нестандартним – це, мабуть, основна скарга Джареда Уайта та інших критиків Tailwind. Джефф Сандберг згадав аналогічні скарги у своєму недавньому пості у блозі, в якому виступав проти попутного вітру. Насамкінець Сандберг висловився докладніше про зростання Tailwind за рахунок безпосереднього написання CSS: «Tailwind – це симптом того, що я вважаю більш серйозною проблемою в розробці. У процесі розробки спостерігається стрімке погіршення якості гордості за майстерність.»
Так хто ж має рацію.
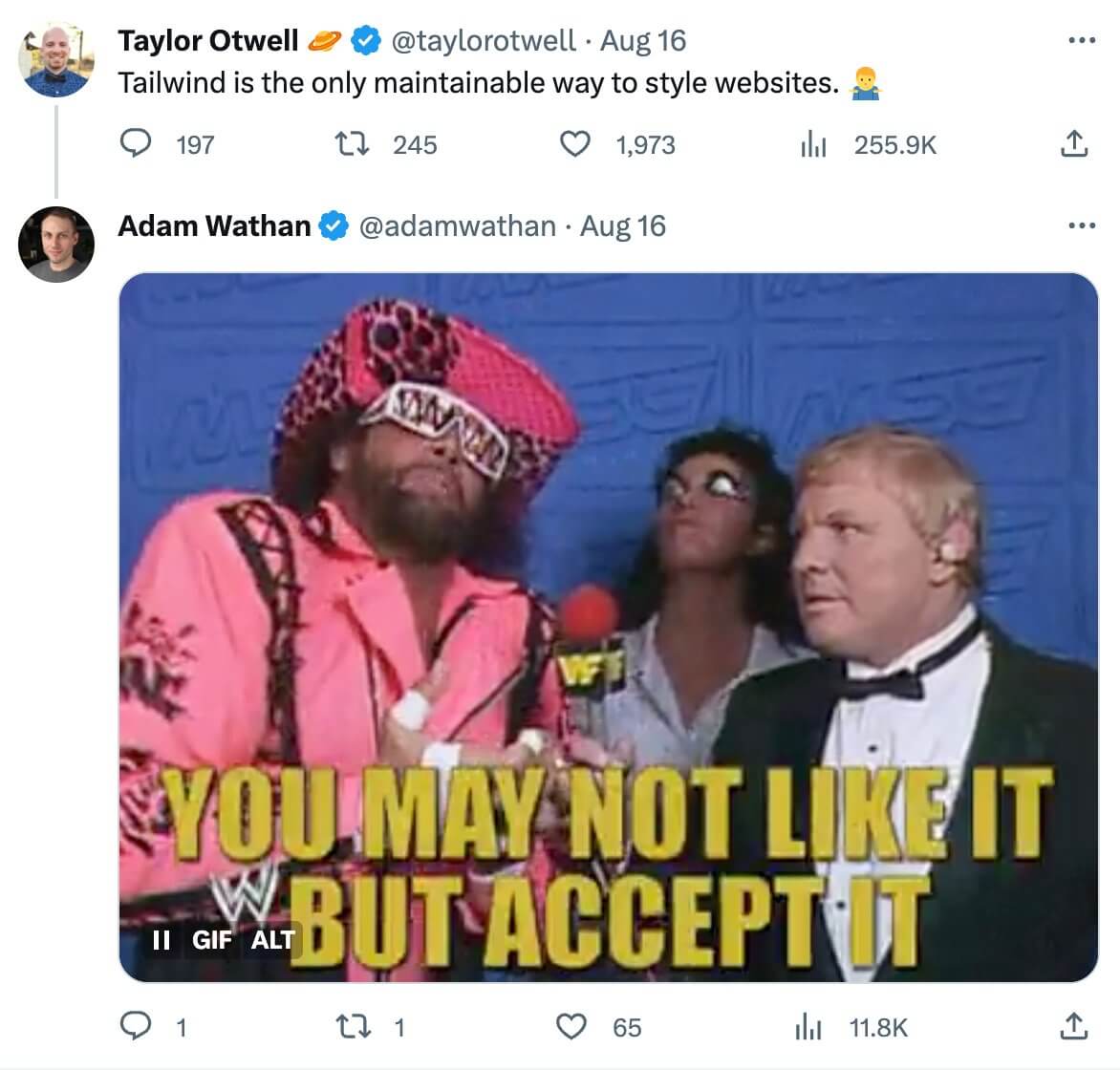
Творець Tailwind, Адам Вотан, без сумніву, багато разів обговорював людей на таких платформах, як X/Twitter. Я переглянув деякі з недавніх тем, але ця гіфка, яку він опублікував із зображенням мачо Ренді Севіджа, схоже, підбиває підсумок його позиції:
З одного боку, я не звинувачую жодного практикуючого веб-розробника за бажання використовувати найпростіший з доступних інструментів, а також той, який добре поєднується з іншими інструментами, наприклад Tailwind можна використовувати з Next.js . Це прагматичний підхід до веб-розробки; і в деяких випадках у розробників може навіть не бути вибору, якщо в проекті вже використовується Tailwind, а вони щойно приєдналися до команди.
З іншого боку, відхилення від існуючих веб-стандартів (хоч би яким незначним воно було) може стати проблемою надалі. Якщо ви більше не працюєте безпосередньо з CSS-файлами, а натомість працюєте з абстракцією, такою як Tailwind, чи не означає це, що у вас менше шансів зрозуміти технологію, що лежить в основі?
Я думаю, Уна Кравець з Google чудово підсумувала це під час недавньої дискусії в X / Twitter про Tailwind: « Tailwind може стати відмінним рішенням , а проблеми виникають, коли люди думають, що їм не потрібно вивчати CSS, якщо вони вивчають Tailwind, що в зрештою обмежує їх », – написала вона у Твіттері у червні.
Порівнюючи дебати про Tailwind з реакцією Стоуша
Дискусія про Tailwind трохи відрізняється від тієї, яку ми вели з приводу React протягом останніх кількох років. Є вагомі докази того, що React насправді шкідливий для Інтернету, в першу чергу через велике навантаження, яке він створює на браузери, що може означати проблеми з продуктивністю для багатьох користувачів.
Кількість непотрібного JavaScript на веб-сторінках через React можна навіть розглядати як етичну проблему. Алекс Рассел (Alex Russell) з команди Microsoft Edge написав наприкінці минулого року, що «сайти продовжують відправляти більше скриптів, ніж це розумно для більш ніж 80% користувачів по всьому світу, збільшуючи розрив між бідними та незаможними».
Однак у випадку Tailwind кінцевий користувач, мабуть, не постраждає. Критики Tailwind скаржаться частково на естетику («потворна розмітка») і частково те, що Tailwind нібито робить з мистецтвом веб-розробки (нестандартний підхід).
Веб-розробник Пол Скенлон різко відповів критикам Tailwind, коли я запитав його про цю дискусію. «Я пишу CSS майже 20 років і він жахливий і завжди складний в обслуговуванні, як і ваш, — сказав він. — Tailwind, принаймні, стандартизував те, наскільки жахливо виглядає».
Сандберг благає розробників дати CSS «ще одну спробу». І, можливо, вони так і зроблять після того, як закінчать свою денну оплачувану роботу в таких крутих інструментах як Next.js і Tailwind.
Елві Рей Сміт – першопрохідник комп’ютерної анімації, співзасновник компанії Pixar, який залишив легендарну студію через розбіжності зі Стівом Джобсом. У книзі «Піксель. Історія однієї точки», він розповідає, як виникли технології, що змінили наші уявлення про мистецтво та світ взагалі. Публікуємо уривок, присвячений тому, як ще 2000 року Сміту довелося заспокоювати стурбованих прогресом акторів.
У 1996 році співробітники студії Pixar отримали спеціальну технічну нагороду Американської академії кінематографічних мистецтв і наук, першу з багатьох, що відбулися далі. Технічні нагороди роздають на церемонії, так само гламурній, як і телевізійна церемонія вручення премії «Оскар», — ті самі смокінги та сукні, лімузини та кінозірки, розкішний банкет та короткі подяки. Різниця лише в тому, що телебачення не транслює її на весь світ, і знамениті журналісти не беруть інтерв’ю у номінантів на червоній килимовій доріжці. Академія цілком обґрунтовано вважає, що широкому загалу навряд чи цікаві генератори туману або павутини та інші технічні досягнення, за які вручається премія протягом багатьох років.
Захід завжди веде кінозірка. У 1996 році це був Річард Дрейфус, відомий нам за безліччю ролей, але особливо за роллю Курта в «Американських графіті» Джорджа Лукаса. Я, Ед Катмулл та ще кілька людей з Pixar, номіновані на премію, сиділи за одним столиком. Лише кількома місяцями раніше пройшла тріумфальна прем’єра «Історії іграшок».
На початку своєї урочистої промови Дрейфус зазначив, що актори та технічні фахівці залежать один від одного і ця інша церемонія вручення премії «Оскар», яка не транслюється по телебаченню, дуже важлива для таких акторів, як він сам. “Ми всі, і актори, і технарі, разом йдемо в майбутнє”, – сказав він. Але згодом додав іронії. Він вказав на наш столик і сказав: “Зверніть увагу, хлопці з Pixar, що я сказав разом!” По залі промайнув нервовий смішок. Багато акторів, очевидно, неодноразово чули надмірно жваві заяви від моїх колег по галузі, що «з дня на день ми замінимо живих акторів на симуляції».
2000 року мені запропонували написати статтю для журналу Scientific American якраз на цю тему — про можливість заміни живих акторів. У ній я висловив думку, що у людях є щось особливе. Ми ще не можемо не те, що замінити, а навіть пояснити це.
Я називаю це творчістю , але термін не зовсім точний. Я маю на увазі те, що зробили Т’юрінг, Котельников та Фур’є, що роблять програмісти, інженери та розробники моделей, що роблять аніматори та актори.
Це те, що зробив Т’юрінг, коли винайшов машинні обчислення і комп’ютер із програмою, що зберігається в пам’яті, здавалося б, з нічого. Це дивовижний творчий стрибок, один із найбільших за всю історію. Ця технічна творчість теоретичного різновиду — у вежі зі слонової кістки. Котельников зробив те саме, створивши теорему відліків, зробивши ще один великий творчий стрибок. І, звичайно, він відштовхувався від великої творчої ідеї Фур’є.
Це те, що роблять програмісти або дозволяє їм створити з дуже довгого списку зовні безглуздих комп’ютерних інструкцій програму, яка робить щось осмислене — наприклад, обчислює «Історію іграшок». Постійне вдосконалення неймовірно швидких комп’ютерів, описане законом Мура, є ще одним прикладом цього. Інший приклад — створення всередині комп’ютера складних моделей, скажімо, персонажів з використанням геометрії та мови затінення.
І це те, що роблять аніматори, коли вдихають життя у своїх персонажів і змушують нас повірити, ніби стос трикутників усвідомлює себе і відчуває біль. Це художня творчість. Їм займаються й актори, які переконують нас, ніби у їхніх тілах живе розум, що належить зовсім іншим людям. Насправді актори та аніматори вважають, що використовують один і той самий навик. Pixar на співбесіді відбирає аніматорів, які мають акторські здібності.
Те, що я написав 2000-го, залишається актуальним і сьогодні, через два десятиліття: ми поняття не маємо, як замінити живих акторів. Але ми можемо замінити зовнішність актора. Образ на екрані, що втілює актора, називається аватаром. Ми можемо замінити актора на екрані переконливим аватаром – навіть на крупному плані, що передає гру емоцій. Я знаю, що це можливо, і робилося вже не раз. Подивіться на Бреда Пітта в «Загадковій історії Бенджаміна Баттона» (2008), де Бред Пітт — не Бред Пітт, а його аватар, цифрове уявлення його зовнішності. Але річ у тому, що аватаром «керує» великий актор, а саме сам Бред Пітт. Аватар замінив не його чи його майстерність, а лише його екранну зовнішність. Переконливі емоції належать актору, а не будь-якій комп’ютерній програмі.
Я передбачив у 2000 році, що ми зможемо зняти фільм із живими акторами, не використовуючи кінокамеру, якщо актори контролюватимуть свої аватари. Пророцтво, в якому я екстраполював результати безперервного розвитку комп’ютерної анімації, збулося через вісім років у «Загадковій історії Бенджаміна Баттона».
<…>
Тоді, в 2000 році, я зробив кілька магічних пасів і припустив, що оскільки знадобилося 20 років для переходу від ідеї комп’ютерного анімаційного фільму в 1975 році до його реалізації в 1995 році, можливо, ще 20 років знадобиться, щоб прийти до першого фільму. без камери», але не «без акторів». Отже, 2020 рік, коли я вношу останні правки в цей розділ, вже настав, так що, очевидно, мої магічні паси не мали ефекту. Немає жодних свідчень, що можна зняти емоційно переконливий фільм за участю одних лише людських аватарів, без справжніх людей у кадрі. І, звичайно ж, немає жодних свідчень заміни акторів або аніматорів, що наближаються, їх комп’ютерними симуляціями. Річард Дрейфус може розслабитися, їх не передбачається і в найближчому майбутньому.
<…>
Кілька років тому, коли я був у Королівському коледжі в Кембриджі, де моя дружина проводила свою наукову відпустку, — у тому самому, де Алан Т’юрінг написав свою основну роботу, — до мене підійшов мій старий колега з ігор з пікселями Джон Бронскілл. “Елві, нам більше не потрібно буде програмувати!” – Він приголомшив мене заявою. Джон зробив собі ім’я, створюючи розширення для графічного редактора Adobe Photoshop, мабуть, найпопулярнішої піксельної програми у професійному світі.
“Що ти маєш на увазі?” – Запитав я. “Прочитай ось це”, – сказав він, сунувши мені в руки науковий журнал. Він був відкритий на статті з дослідницької лабораторії штучного інтелекту Каліфорнійського університету в Берклі. У ній описувалася нейромережа певного типу, яку навчили за допомогою 1000 немаркованих довільних фотографій коней та 1000 немаркованих довільних фотографій зебр. Фото коней містили різну кількість коней різного кольору, розташованих у довільному порядку. Фотографії зебр теж використовувалися різні, хоча кольори зебр, звісно, не відрізнялися. Усі ці фотографії були цифровими, які з пікселів. Після відповідного навчання (не описуватиму його технологію) мережа навчилася робити наступний разючий фокус: отримавши на вході довільну фотографію зебри, мережа заміняла кожну зебру на коня. Насправді вона просто перефарбовувала зебру у кольори коня чи навпаки.
“Як це працює? — спитав я і додав: — Я навіть не думаю, що ця проблема має чітке визначення». Що таке для комп’ютера кінь? Що таке зебра? Як він зіставляє одне з одним?
Джон просто відмахнувся: Я не знаю. І ніхто не знає. Воно просто робить це! Це надто складно для зворотного проектування».
Та сама нейронна мережа здатна і на інші дивовижні речі. Якщо навчити її на пейзажних фотографіях та картинах Ван Гога, вона зробить із будь-якого знімка природи картину у стилі Ван Гога. Або навпаки. Або у стилі Моне. Або перетворить літні краєвиди на зимові. Або навпаки.
Я згадую тут про це, щоб поставити запитання: що буде далі в Цифровому Світлі? Зізнаюся, я не розумію, що відбувається і наскільки це важливо у довгостроковій перспективі. Але давайте трохи поміркуємо.
Т’юрінг дозволив своїй універсальній машині Тьюринга — або комп’ютеру з програмою, що зберігається в пам’яті, — виконувати операції над самою програмою, як над даними. Саме в цьому і полягає суть його винаходу – комп’ютера з програмою, що зберігається в пам’яті. Чи належить робота програми «кінь-зебра» до операцій, у яких програма сама модифікує себе? Тьюринга особливо приваблювала така можливість, як і створення штучного інтелекту. Операційні системи сучасних комп’ютерів зазвичай забороняють програмам самомодифікуватись, щоб не призвести до повного хаосу.
Нейронна мережа моделюється на звичайному комп’ютері, тому програма, що виконує моделювання, не модифікує себе. Але припустимо, що нейронна мережа була справжньою нейронної мережею, а чи не просто симуляцією. Чи можна її витлумачити як програму, що модифікує саму себе? Я думаю, що так. Наш мозок — це, безперечно, нейронна мережа, і, наскільки нам відомо, у ньому немає сховища програм, окремого від сховища даних. І, ймовірно, він не робить нічого, що виходить за рамки обчислень Тьюринга. Ми не знайшли жодного іншого алгоритмічного процесу за 80 років із моменту появи цієї концепції.
У 1965 році я вступив до аспірантури Стенфорда, тому що він входив до двох відомих мені університетів, де викладали захоплюючий новий предмет – штучний інтелект (у наші дні його часто скорочено називають ШІ). Ще його викладали у Массачусетському технологічному інституті. Я навчався у Джона Маккарті, батька-засновника штучного інтелекту у Стенфорді. І я кілька разів докладно розмовляв із Марвіном Мінськи з МТІ, ще одним батьком-засновником цього напряму.
Через кілька років я кинув займатися ШІ, вирішивши, що за мого життя прориву в цій галузі не станеться. Можливо, я зробив передчасний висновок, якщо врахувати, що в запасі, мабуть, є ще два десятиліття, але тим часом я допоміг зняти перший цифровий фільм. Оскільки я зробив це, я тепер маю час повернутися до роздумів про ШІ. Хоча насправді я ніколи не переставав про нього думати.
Мене спантеличило зауваження Джона Бронскілла. Я завжди припускав, що коли мені пояснюватимуть принцип роботи ШІ, я все зрозумію. Проте переді мною був приклад машинного навчання, можливо, недостатньо розвиненого, щоб називатися ШІ, і я нічого не зрозумів. Можливо тому, що мережа модифікує свою власну програму? Ми знаємо, що, як правило, не можна бути впевненим навіть у такій простій речі, як чи зупиниться врешті-решт програма, тому, ймовірно, і немає нічого дивного в тому, що ми не можемо зрозуміти, як працює ця програма «зебра- кінь».
Сама природа нинішньої революції полягає в тому, що ми не можемо передбачити її, не можемо зазирнути вперед далі, ніж один порядок величини. Нам просто потрібно осідлати хвилю і побачити, яке захоплююче і навіть загадкове місце вона нас винесе.
Відрізнити дружину від кішки: з чого починався китайський ШІ
Китайська система нагляду — страшилка для ЗМІ, технологічна революція чи похмура антиутопія, яка чекає на весь світ? У цьому вирішив розібратися американський журналіст Джеффрі Кейн. Він вирушив прямо в Сіньцзян — регіон, з одного боку, сумнозвісний «санаторіями» для уйгурів, а з іншого — китайською столицею в галузі досліджень штучного інтелекту. За підсумками поїздки Кейн написав книгу ” Держава суворого режиму “. Публікуємо з незначними скороченнями розділ «Глибинна нейронна мережа».
У роботі з іноземними партнерами китайські корпорації, які підтримує держава, практикували те, що в бізнесі називається «примусовою передачею інтелектуальної власності». Щоб вийти на закритий ринок Китаю, іноземним компаніям доводилося зазвичай домовлятися з китайськими партнерами. Одна з неформальних вимог полягала у передачі китайським компаніям про чутливих технологій — напівпровідників, медичної апаратури та нафтогазового обладнання.
За правилами Світової організації торгівлі така вимога є незаконною, проте американські компанії хоч і неохоче, але все ж таки розкривали свої комерційні таємниці в надії отримати доступ до 1,4 млрд потенційних клієнтів у Китаї.
Коли Китай почав накопичувати дані про своїх громадян, збираючи інформацію про використання додатків і сервісів, подібних до WeChat, перспектива стати лідерами в розширюваній і прибутковій індустрії штучного інтелекту залучила багато місцевих високотехнологічних компаній, що зароджуються. Китайські дослідники в галузі ШІ, яких ставало дедалі більше, уважно стежили за відкриттями, що відбувалися у США, світовому лідері галузі. Китайські компанії сподівалися розкрити таємниці штучного інтелекту, розшукуючи талановитих розробників-китайців, які навчалися за кордоном і працювали в Microsoft і Amazon, і заманюючи їх на батьківщину високими зарплатами та закликами до патріотизму. До початку 2010-х років китайські програмісти наблизилися до створення глибинної нейронної мережі — святого Грааля наглядової держави; системи,
Протягом багатьох років дослідники в області ШІ покладалися на так звану “засновану на правилах” систему програмування. Вони закладали в комп’ютер програму для розпізнавання кішки, повідомляючи йому: «Шукай коло з двома трикутниками зверху». Такий підхід був виправданий, оскільки на більше комп’ютерів не вистачало обчислювальної потужності. Однак він також і обмежував можливості ШІ: не всі зображення кішок являють собою ідеальне коло з двома трикутниками зверху, і не всі кола з трикутниками зверху є кішками.
Більш сучасна технологія — глибинна нейронна мережа — мала цілу низку переваг. У операторів більше не було необхідності виконувати монотонну та трудомістку роботу з ручної категоризації зображень та даних, а потім писати правила для системи штучного інтелекту. Натомість програмне забезпечення навчилося самостійно поєднувати розрізнені дані, переглядаючи величезний обсяг інформації, а потім навчатися на основі цих даних. Згодом програма могла вдосконалювати алгоритм виконання завдання, на вирішення якої її й створювали. Чим менше операторів контролювало та обмежувало програмне забезпечення, тим більше варіантів застосування ШІ з’являлося у компаній. Глибинні нейронні мережі навчилися керувати безпілотними автомобілями, допомагати лікарям ставити діагнози, а також виявляти шахрайство із кредитними картками.
До 2012 року ідея про те, що глибинна нейронна мережа здатна вплинути на ринок, вважалася нісенітницею. Як би не намагалися програмісти з Microsoft Research Asia і нових компаній, що виникають, їх праці ні до чого не приводили. У 2012 році розробники в області ШІ в Китаї та Кремнієвій долині говорили мені, що створення нейронної мережі стане золотою житловою для Microsoft. У травні 2011 року Microsoft придбала Skype, популярну в усьому світі програму для дзвінків та відеоконференцій, здійснивши найбільшу на той момент угоду в галузі. Якби Skype або Microsoft Windows вміли розпізнавати голос і обличчя, це стало б проривом. Було б закладено основу функції перекладу у часі і систем кібербезпеки, що спираються на технологію розпізнавання осіб.
У 2011 році в Пекіні я познайомився з групою молодих китайських дослідників, які працюють до втрати пульсу і без вихідних у спробах вирішити цілий комплекс питань, що терзають їх. Головні з них звучали так: «Як комп’ютерна система може навчитися „бачити“ та „сприймати“ людину? Як вона може почути та дізнатися його голос? Чи може ШІ навчитися говорити?»
«Зараз слушний момент, — казав мені один із них за вечерею після роботи. — Інтернет та соціальні мережі можуть бути джерелами даних, з якими працюватиме ШІ. Ми можемо збирати інформацію про кліки в інтернеті, покупки та переваги людей».
За його словами, у 2005 році до інтернету було підключено менше 10% населення Китаю, але вони швидко стали найактивнішими користувачами соціальних мереж, мобільних додатків та мобільних платежів у світі. У 2011 році своїм власним інтернет-підключенням набуло майже 40% населення, або близько 513 млн осіб. Всі ці користувачі залишали інформацію про свої покупки та дії в інтернеті, яку можна було використовувати, щоб навчити нейронні мережі вирішувати безліч завдань, включаючи стеження за користувачами.
У тому ж 2011 році двоє молодших наукових співробітників, які працювали з відомим дослідником в галузі ШІ Джеффрі Хінтоном , професором інформатики Університету Торонто та співробітником Google, зробили важливе відкриття в галузі апаратного забезпечення. Дослідники зрозуміли, що можуть використовувати графічні процесори (GPU) – пристрої, що покращують графіку в комп’ютерних іграх, – щоб підвищити швидкість обробки даних глибинною нейронною мережею. Розробники в області ШІ могли використовувати характерні для GPU методи відображення форм та зображень на екрані та навчати нейронну мережу пошуку закономірностей.
Раніше створення нейронної мережі коштувало дуже дорого. Але вартість ключового обладнання, на якому працює програмне забезпечення, знизилася завдяки гіпотезі з графічними процесорами. Протягом багатьох років вони ставали дешевшими і дешевшими, навіть незважаючи на збільшення їх пам’яті та обчислювальної потужності.
З удосконаленням апаратного забезпечення та зростанням кількості масивів даних настав ідеальний час для створення глибинної нейронної мережі, яка обробляла б ці дані.
Методом спроб і помилок команда Microsoft під керівництвом доктора Сунь Цзяня знайшла рішення: збільшити кількість «шарів» у нейронній мережі, що дозволило б системі штучного інтелекту постійно оновлювати свої знання та навчатися на інформації, що проходить через неї. Шари нейронної мережі схожі на скупчення нейронів, які отримують дані, обробляють їх, а потім передають на наступні шари для подальшої обробки – так ШІ дізнається все більше про предмет, що аналізується.
Теоретично, що більше шарів, то краще мислить машина. Насправді все виявилося складніше. Одна з проблем полягала в тому, що після проходження кожного шару сигнали пропадали, що заважало дослідникам Microsoft навчати систему.
У 2012 році розпізнавати зображення вдалося навчити систему з вісьмома нейронними шарами. До 2014 року – з тридцятьма. Збільшивши кількість шарів, команда дослідників зробила прорив у тому, що стосується можливості комп’ютера розпізнавати об’єкти на відео та зображення. “Ми навіть не вірили, що ця одна-єдина ідея може виявитися настільки важливою”, – говорив доктор Сунь.
Китайська технологічна екосистема почала привертати увагу венчурних капіталістів, які стали менш зосереджені на традиційних фінансових та технологічних центрах у Кремнієвій долині та Нью-Йорку. Вони прагнули негайно розпочати роботу у двох галузях, де ховався величезний потенціал для наглядової екосистеми: у технологіях розпізнавання облич та розпізнавання мови.
Перша велика інвестиція прийшла у технологію розпізнавання осіб.
У 2013 році створена Кай-Фу Лі венчурна фірма Sinovation Ventures, що спеціалізується на ШІ, підтримала платформу розпізнавання осіб Megvii (Mega Vision), що розвивається. Сума інвестицій не розкривалася. Потім SenseTime (конкурент Megvii, заснований у Гонконгу в 2014 році) випустила перший алгоритм, здатний за певних умов ідентифікувати людей з точністю, що перевищує можливості людського ока, і заявила, що перевершила показники Facebook, — це стало віхою в індустрії ШІ.
За словами Ян Фаня, керівника відділу розробки SenseTime і колишнього співробітника Microsoft, додатки «громадської безпеки» виявилися прибутковим ринком.
“Існує високий, конкурентний попит, обумовлений системами “розумного” міста та відеоспостереження”, – говорив він в інтерв’ю Forbes Asia.
Але програмного забезпечення для розпізнавання осіб потрібні були найсучасніші напівпровідники. Звідки їм було взятися?
SenseTime та інші китайські компанії, що займаються питаннями штучного інтелекту, звернулися по напівпровідники до американських фірм. З’ясувалося, що їхніх колег із США цікавили китайські технології створення програмного забезпечення для мобільних додатків та правоохоронної системи. Американський телекомунікаційний оператор Qualcomm домовився з Megvii про співпрацю: в обмін на напівпровідники Qualcomm отримував право використовувати програмні засоби систем ШІ Megvii у своїх пристроях.
“У Китаї спостерігається вибуховий попит”, – зазначав Лі Сюй, співзасновник і генеральний директор SenseTime, на бізнес-конференції в червні 2016 року в ході спільного виступу з Джеффом Хербстом, віце-президентом з питань розвитку підрозділу венчурного інвестування Nvidia.
Через сім-вісім років після свого заснування у 1993 році компанія Nvidia стала провідним виробником графічних процесорів. Тепер вона готувалася знімати вершки з буму, що насувається, в індустрії штучного інтелекту.
Незабаром Nvidia почала укладати гучні угоди з китайськими фірмами, які займаються технологією розпізнавання осіб. За допомогою чіпів, вироблених Nvidia та її основним конкурентом Intel, у Центрі хмарних обчислень в Урумчі, відкритому в 2016 році, були створені одні з найпотужніших у світі комп’ютерів, які використовуються для стеження. За день ці комп’ютери переглядають більше записів із камер відеоспостереження, ніж за рік.
«У Китаї я бачу камери на кожному ліхтарному стовпі, — говорив Гербст. — Здається, що проглядається просто все. Але проблема в тому, що відео надходить у диспетчерську, в якій сидить хлопець і чекає, коли щось станеться. Хіба це все не потрібно автоматизувати?
Лі Сюй визнавав інтерес китайського уряду до питань громадської безпеки, як і той факт, що «існуюча система спостереження була серйозно обмежена відсутністю інтелектуального механізму управління, особливо щодо обробки відео».
Він запропонував піти альтернативним шляхом.
Лі Сюй знав, що технологія чіпів Nvidia, запозичена зі подібних технологій обробки графіки, відігравала «фундаментальну» роль у його роботі і що для підтримки технології розпізнавання осіб Nvidia задіяно 14 тисяч таких чіпів у серверах по всій Азії.
“Відчуваю, нас з вами чекає довга співпраця”, – сказав йому Гербст з Nvidia під час бізнес-конференції. Можливо, Гербст цього й не хотів, але його слова пролунали зловісно. До 2015 року всі складові наглядової екосистеми стали на свої місця: програмне забезпечення навчилося розпізнавати особи, сканувати текстові повідомлення та електронні листи, а також виявляти закономірності у писемному мовленні та взаємодії людей.
Тепер інвестори почали вкладати свої гроші у наступний ключовий елемент: програмне забезпечення, здатне розуміти та обробляти людський голос.
Наприкінці 1990-х років молодий перспективний дослідник Лю Цінфен відмовився від стажування в Microsoft Research Asia і присвятив кар’єру своєму стартапу iFlyTek, поставивши за мету розробку передової технології розпізнавання голосу.
«Я сказав йому, що він талановитий молодий дослідник, але Китай дуже відстає від американських гігантів індустрії розпізнавання мови, таких як Nuance, а ще в Китаї буде менше споживачів цієї технології, — писав Кай-Фу Лі. — Треба віддати Лю належне: він проігнорував мою пораду і з головою поринув у роботу над iFlyTek».
У 2010 році iFlyTek створила в Сіньцзяні лабораторію, що розробила технологію розпізнавання мови для перекладу уйгурської мови на мандаринський діалект китайської. Незабаром цю технологію почнуть використовувати для стеження та нагляду за населенням Уйгура. До 2016 року iFlyTek постачала до Кашгару вже двадцять п’ять систем «голосових відбитків», які створювали унікальні голосові підписи, які допомагали ідентифікувати та відстежувати людей.
«Усі ці компанії приходили до Сіньцзяна на моїх очах, — згадуєІрфан. — Я бачив їхню апаратуру, їхнє програмне забезпечення». Десятки уйгурів, які втекли із Сіньцзяну після 2014 року, згадували, що помічали логотипи цих компаній на обладнанні. Присутність цих компаній у Сіньцзяні відображена в урядових тендерах, що збереглися в інтернеті, в офіційних корпоративних звітах, доповідях про положення з правами людини, американських санкційних документах, а також у повідомленнях китайських державних засобів масової інформації. «Але багато хто не бачив у цьому нічого небезпечного. Настрій був такий: “Ми просто боремося зі злочинністю”», – зауважує Ірфан.
У період з 2010 до 2015 року на синьцзянський ринок нарешті вийшла і компанія Huawei, національний технологічний символ Китаю, яка розробила сервіси хмарних обчислень у співпраці з місцевою поліцією. Huawei (грубий переклад:“Китай подає надії”) була заснована колишнім військовим інженером Жень Чженфеєм зі стартовим капіталом у три тисячі доларів. У 1980-х роках компанія почала розробляти телефонні комутатори – копіюючи іноземні зразки. Будучи одними з перших апологетів прискореного технологічного розвитку, що просувається урядом, Huawei стала відома в країні та за кордоном завдяки своїй апаратурі для відеоспостереження та мережевого обладнання, а також нарощувала свою присутність на ринку смартфонів.
Жень Чженфей, якого колишні співробітники описують не інакше як напівмістичну фігуру, що висловлюється притчами про струмки та гірські вершини, виношував грандіозні плани щодо глобальної експансії. Ці плани могли бути реалізовані лише в тому випадку, якби західні демократії вдалося переконати, що Huawei не пов’язана з Комуністичною партією Китаю (КПК) і не використовуватиме свої технології для шпигунства. Водночас керівники Huawei прагнули продавати мережеве обладнання владі Сіньцзяну, розглядаючи суспільну безпеку як прибутковий бізнес.
«У 2015 році ми були на заході з тимбілдингу, — розповідав мені Вільям Пламмер, колишній американський дипломат, який обійняв посаду віце-президента Huawei із зовнішніх зв’язків у Вашингтоні. — Хтось показав слайд із написом: „У чому суть Huawei?“ І перший пункт говорив: „Для внутрішньої аудиторії Huawei — китайська компанія, яка підтримує Комуністичну партію Китаю“. Потім йшов другий пункт: „Для зарубіжної аудиторії Huawei — незалежна компанія, яка дотримується міжнародно визнаної корпоративної практики“.
По суті, вони мали на увазі, що в Китаї потрібно дотримуватись правил Китаю, а в інших країнах — правил цих країн. Але помістити це у презентацію… Один лише цей слайд уже був компрометуючим».
До 2015 року виявився доступним завершальний елемент наглядової екосистеми: дешевша технологія для камер відеоспостереження. Досить дешева, щоб набути поширення у промислових масштабах. На ринок Сіньцзяну вийшла китайська компанія Hikvision, найбільший у світі виробник камер відеоспостереження. Вона надала мільйони камер, які дозволили владі встановити стеження за населенням. Камери були настільки просунутими, що могли ідентифікувати людей на відстані п’ятнадцяти кілометрів та використовували програмне забезпечення ШІ від iFlyTek, SenseTime та інших компаній для аналізу осіб та голосу.
«Скайнет», радикальна і всепроникна державна наглядова система, яка концептуально зародилася десятиліттям раніше, тепер могла втілитись у реальність.
Весь цей технологічний ривок і в певному сенсі зловісний синтез різних елементів, що призвели до державотворення на основі штучного інтелекту, не залишилися непоміченими. Вже 2010 року стривожилися Сполучені Штати, найбільший суперник Китаю на міжнародній арені.
Американські політики почали підозрювати, що Huawei та її партнери є прикриттям, що дозволяє Народно-визвольній армії Китаю (НОАК) користуватися бекдорами в обладнанні та програмному забезпеченні з метою кібершпигунства.
«З високим ступенем упевненості можемо заявити, що зростаюча роль міжнародних компаній та іноземних осіб у ланцюжках постачання інформаційних технологій та послуг США створить загрозу безперервній потайливій диверсійній діяльності», — говорили документи Агентства національної безпеки США (АНБ), відповідального за перехоплення комунікацій у світовому масштабі . 2010 року ці записи оприлюднив викривач Едвард Сноуден.
Крім того, злиті Сноуденом документи показали, що АНБ стежило за двадцятьма китайськими групами хакерів, які намагалися зламати державні мережеві структури США, а також мережі Google та інших компаній. До того ж АНБ сподівалася дістатися до Huawei підводних кабелів, що прокладаються, щоб відстежувати комунікації користувачів, яких воно вважало «високопріоритетними цілями», — на Кубі, в Ірані, Афганістані та Пакистані.
АНБ проникло в центральний офіс Huawei, відстежувало комунікації її топ-менеджерів, а також провело операцію під назвоюShotgiant, Націлену на виявлення зв’язку між Huawei та Народно-визвольною армією Китаю. Наступним кроком АНБ стала спроба використовувати технології Huawei, які компанія продавала в інші країни та організації: впровадитись у вироблені Huawei сервери та телефонні мережі та вести кібератаки на ці країни. Все це вдалося здійснити завдяки безмежним хакерським можливостям, а також бекдорам, створеним за співпраці з американськими телеком-компаніями, що дозволило подолати звичні технологічні бар’єри для здійснення масового шпигунства за іноземними громадянами.
Представники Сполучених Штатів та Китаю заговорили про холодну війну, незважаючи на торговельні та технологічні зв’язки між країнами. У 2012 році комісія Конгресу оприлюднила результати річного розслідування, заявивши про отримання від колишніх співробітників Huawei документів, що свідчать про те, що компанія надавала свої послуги підрозділам кібервійськ армії Китаю.
Влада США почала придивлятися до дочки генерального директора Женя, Мен Ваньчжоу, відомої під англізованим прізвисько «Кеті». Як світська левиця Huawei Кеті проводила ділові заходи, які включали сесії питань і відповідей зАланом Грінспеномта іншими гостями. ФБР та Міністерство внутрішньої безпеки закулісно стежили за діловою активністю «Кеті» та Huawei. Вони підозрювали, що «Кеті» займалася підставною компанією в Ірані під назвою Skycom, яка порушувала торгові санкції США, ведучи бізнес з іранськими телеком-компаніями.
«Ми представили уряду США інформацію про Huawei в Ірані, про Skycom і про те, що це була незалежна компанія, хоч вона [Мен Ваньчжоу] входила до ради директорів протягом двох років, — зізнався мені Пламмер. — Ми надали ці запевнення, бо нам так було сказано, і нам здавалося, що так буде краще. Але це було брехнею. Співробітники Skycom в Ірані розгулювали з візитними картками Huawei».
Пламмер розповів, що у 2013 році йому надійшов дзвінок від розлюченого начальства з Huawei. Агенти Міністерства внутрішньої безпеки направили Мен на додатковий огляд, затримавши її перед посадкою на рейс у нью-йоркському аеропорту імені Джона Кеннеді, коли вона поверталася з одного зі своїх гламурних бізнес-заходів.
«Вони чотири години утримували її комп’ютер, планшет та обидва телефони, — розповідав Пламмер. — Влада США все скопіювала». Мен звільнили. Керівники Huawei приготувалися до майбутньої юридичної битви, закривши офіс Skycom у столиці Ірану Тегерані, та дистанціювалися від Skycom.
Але поки Сполучені Штати поливали брудом Huawei і Китай, звинувачуючи їх у передбачуваній установці бекдорів, що дозволяють здійснювати хакерську діяльність за підтримки держави, а також в управлінні підставною компанією, АНБ було спіймано на впровадженні власних бекдорів в американські мережеві продукти, що поставляються до Китаю.
Німецька газета Der Spiegel придбала п’ятдесятисторінковий каталог, створений підрозділом АНБ під назвою «Відділ просунутих мережевих технологій» (Advanced Network Technology Division), який займався перехопленням інформації в найбільш захищених мережах. АНБ отримало доступ до вантажів американської компанії мережевого обладнання Cisco, що прямували до Китаю, і потай встановило в них пристрої спостереження. Компанія Cisco пізніше заявляла, що не знала про зло, вчинений своїм же урядом.
Ще один мережевий продукт АНБ, HALLUXWATER, виявився “бекдор-імплантатом”. Він зламував фаєрволли Huawei, що дозволяло АНБ впроваджувати шкідливе програмне забезпечення та керувати пам’яттю пристроїв.
«У такій контролюючій поведінці Сполучених Штатів немає нічого несподіваного, – повідомив Жень Чженфей журналістам у Лондоні. — Але ж тепер це було доведено».
Незабаром на тлі геополітичного суперництва, що зароджується, Китай розкрив свої карти. У цій країні видобувається 93% світових запасів рідкісноземельних елементів, таких як літій та кобальт, що експортуються в інші країни та необхідні для вдосконалення батарей та дисплеїв в айфонах та телевізорах. У вересні 2010 року китайський рибальський траулер зіткнувся з двома японськими катерами берегової охорони неподалік спірних островів Сенкаку. Японія заарештувала капітана траулера за підозрою у порушенні її прав на вилов риби в регіоні, який вона контролює, і на який давно претендує Китай.
Китай завдав удару у відповідь. Він заблокував експорт рідкісноземельних елементів в Японію, поставивши під загрозу виробництво неймовірно популярної Toyota Prius, для двигуна якої потрібно близько кілограма рідкісноземельних елементів.
Трохи більше двох тижнів Японія звільнила членів екіпажу траулера, не пред’явивши звинувачень.
“Китай і Японія – значущі сусіди з важливими обов’язками в міжнародному співтоваристві”, – заспокійливо заявив прем’єр-міністр Наото Кан у Нью-Йорку на Генеральній асамблеї ООН.
Але в міру того як Друга холодна війна набирала оберту, розбіжність між американською та китайською технологічними стратегіями ставала очевидною.
Китай намагався викрасти американські технології, включаючи комерційні таємниці та інтелектуальну власність, щоб передати їх приватним китайським компаніям, які хотіли обставити Кремнієву долину.
Сполучені Штати, у свою чергу, хотіли впровадитись у Huawei та інші китайські компанії. Їхня мета полягала не в крадіжці китайських технологій, на той момент ще недосконалих, і передачі їх приватним компаніям на кшталт Amazon і Google, а скоріше у зборі інформації про можливі зв’язки цих організацій з військовими структурами, а також загрози національній безпеці США з боку Китаю та його компаній.
Під час журналістського відрядження у червні 2014 року, блукаючи вулицями Пекіна, Шанхаю та китайського технологічного центру Шеньчжень, я відчував зростання самопроголошеного, майже відчутного націоналізму — особливо серед китайської молоді.
Здавалося, розмови про нову холодну війну викликають у людей тривогу, яку посилювала державна пропаганда.
Керівник однієї місцевої технологічної компанії спробував пояснити мені новоявлену самовпевненість Китаю. “Ви ж знаєте, що Google пішов з Китаю”, – повідомив він мені з гордістю. Після чотирьох років роботи на китайському ринку Google закрив свій китайський пошуковий сайт у 2010 році, у розпал конфлікту з приводу злому ресурсів компанії та цензурування пошукових результатів. «Але це не має жодного значення, – пояснив він. — Ми маємо свою пошукову систему Baidu. Тепер ми маємо свої власні компанії. Світ змінюється, і я сподіваюся, що Кремнієва долина та АНБ не домінуватимуть вічно».
«Але не здається вам, що якщо Китай хоче досягти рівня Кремнієвої долини, йому доведеться відкрити інтернет, — запитав я, — щоб дослідники могли отримувати інформацію, необхідну для створення якісних технологій?» «Це теж не має значення, – відповів він. — У Китаї наші технології пов’язані із майбутнім нашої країни. Ми не маємо такого явного поділу влади, як у США. Наша єдина мета – зробити Китай великим. Ми хочемо бути з американцями на рівних, щоб ніхто більше не дивився на нас згори».