Що таке Тест Хауї і як він відноситься до криптовалют?
Регулятори вже багато десятиліть використовують Тест Хауї для визначення належності активів до категорії цінних паперів.
Багато учасників криптоспільства впевнені, що цю схему не можна застосовувати щодо блокчейн-активів.
Нинішній глава SEC Гері Генслер відносить криптовалюти до цінних паперів.
Що таке Тест Хауї?
Тест Хауї (англ. Howey Test) — це перелік критеріїв, які допомагають визначити, чи має актив ознаки цінних паперів і чи є «інвестиційним контрактом».
Інструмент може також застосовуватися до проектів, комерційних угод та інших операцій.
Згідно з тестом Хауї, інвестиційний контракт існує, якщо є «вкладення грошей у спільне підприємство з розумним очікуванням прибутку, який можна отримати від інших зусиль».
У SEC переконані, що деякі криптоактиви та більшість ICO можуть кваліфікуватись як інвестиційні контракти.
Звідки виник Тест Хауї?
Тест Хауї розробили та вперше задіяли на практиці у 1946 році. Приводом для його створення став розгляд SEC із фірмами WJ Howey Co. та Howey-in-the-Hills Service з Флориди.
Підприємства продали населенню ділянки цитрусової плантації. Інвестори домовились із представниками фірм про здачу ділянок в оренду. В результаті WJ Howey Co. з’явилася можливість вирощувати та збирати врожай на чужих землях, займатися маркетингом та ділити зі стейкхолдерами прибуток від продажу. При цьому більшість покупців не мали досвіду в землеробстві і не планували освоювати цю діяльність.
Верховний суд США дійшов висновку, що продані ділянки, по суті, були пропозицією незареєстрованих цінних паперів. Відповідно до закону, угоди мали ознаки інвестиційного контракту — учасникам потрібно було лише вкласти кошти для отримання джерела пасивного доходу.
На основі кейсу SEC vs. WJ Howey Co. з’явилися чотири критерії, що стали основними складовими Тесту Хауї:
Інвестування коштів (у будь-якій формі: готівка, чеки, а згодом і криптоактиви).
Вкладення капіталу спільне підприємство.
Обґрунтовані очікування прибули в інвесторів.
Доход, отриманий зусиллями інших.
Підхід прижився, і з тих пір критерії тесту Хау застосовуються для визначення приналежності різних активів до цінних паперів.
Чому SEC застосовує Тест Хауї до криптовалютів?
З розвитком ринку криптовалют, а особливо після буму первинних пропозицій монет 2017-2018 років, регулятори по всьому світу задалися питанням, чи мають нові активи властивості цінних паперів. З цією метою у деяких випадках американська SEC застосовує Тест Хауї.
Комісія з цінних паперів та бірж США випустила керівництво з використання вищезгаданого фреймворку щодо криптовалют та інших активів на базі блокчейну.
«Термін „цінний папір“ включає „інвестиційний контракт“, так само як і інші інструменти на кшталт акцій, облігацій та передані частки [в капіталі компаній]. Цифровий актив має бути проаналізований для визначення того, чи має він характеристики будь-якого продукту, що відповідає визначенню цінного паперу відповідно до федерального законодавства», — йдеться в документі SEC.
Один із яскравих прикладів застосування Тесту Хауї в контексті криптоіндустрії – кейс із токенсейлом Telegram. Проект TON залучив $1,7 млрд завдяки продажу монет Gram кваліфікованим інвесторам у США та за їх межами, проте так і не запустився через конфлікт із Комісією з цінних паперів та бірж США.
Інший приклад – позов SEC проти Ripple, поданий у 2020 році. Регулятор звинуватив компанію у поширенні незареєстрованих цінних паперів на суму близько $1,3 млрд. у вигляді нативних токенів платформи.
Однак справа, що тривала кілька років, набула несподіваного для багатьох учасників криптоспільства повороту. 13 липня 2023 року Суд Південного округу Нью-Йорка дійшов висновку, що програмні продажі та інші розподіли токена XRP від Ripple не є пропозицією та реалізацією інвестиційних контрактів.
У червні SEC подала до суду на біржу Binance та її CEO Чанпен Чжао, а також на американську компанію Coinbase. В обох випадках претензії стосуються незареєстрованих пропозицій токенів та сервісів для отримання пасивного доходу.
Нинішній глава Комісії Гері Генслер твердо переконаний, що криптовалюти – інвестиційні контракти. Отже, відповідальним за емісію монет платформ необхідно зареєструватися в SEC.
Криптоіндустрія, що багато в чому орієнтується на США, змушена зважати на Тест Хауї. Чимало проектів позиціонують цифрові активи, що випускаються, як токени управління (governance-токени), оскільки ті використовуються в голосуваннях в рамках ДАТ. Однак через правову невизначеність безліч проектів і, відповідно, активів можуть привернути увагу регуляторів.
Чому SEC не відносить біткоїн до цінних паперів?
У червні 2018 року діючий тоді глава SEC Джей Клейтон заявив, що біткоін не є «інвестиційним контрактом».
«Криптовалюти – це замінники суверенних грошей. Біткоїн може замінити долар, євро, ієну. Цей тип валюти не є цінним папером», – сказав він.
За словами Клейтона, до цінних паперів можна віднести токени, оскільки вони виконують роль цифрових активів і фінрегулятор США контролює цю сферу.
«Якщо я даю вам гроші, а ви створюєте підприємство і передаєте мені право на частку від спільного капіталу, то ми говоримо про цінні папери. Комісія регулює пропозиції подібних цінних паперів та торгівлю ними», – прокоментував він.
Також влітку 2018 року директор з корпоративних фінансів SEC Вільям Хінман заявив, що біткоїну та Ethereum більш властиві характеристики товару, що передбачає компетенцію Комісії з термінової біржової торгівлі США (CFTC).
“Якщо мережа криптовалюти досить децентралізована, а покупці не покладаються на третій бік у питанні управління, монета не є цінним папером”, – наголосив чиновник.
Що не так із Тестом Хауї?
Практика показала, що схема першої половини минулого століття не враховує специфічних особливостей криптовалюту.
У цьому переконана і комісарка SEC Хестер Пірс. Вона підкреслила, що багато стартапів залучали фінансування під обіцянку побудувати мережу. Це створювало підстави для визнання токенів, що випускаються, як «інвестиційні контракти» по Тесту Хауї.
На думку Пірс, існування інвестиційного контракту залежить не тільки від активу, а й від обіцянок, що з ним асоціюються. Ці два компоненти не пов’язані один з одним, зазначила вона.
«Те, що я продала вам апельсиновий гай у рамках інвестиційного контракту, не перетворює його на цінний папір. Апельсинова гай плюс обіцянки про те, як я збираюся доглядати її і приносити вам прибуток, — це пропозиція цінних паперів», — пояснила Пірс.
Представниця SEC упевнена, що Тест Хауї сам по собі не дає однозначної відповіді на питання відповідності криптовалюти статусу інвестиційного контракту у відриві від самого процесу їх розміщення, в якому можна виявити подібні ознаки.
Чим governance-токени відрізняються від utility-токенів?
Токени управління (governance) – своєрідні акції в контексті блокчейн-екосистем. Вони надають право голосувати з ключових питань розвитку децентралізованих протоколів.
Governance-токени — не лише інструменти прямої демократії. Їх можна задіяти у багатьох інших юзкейсах.
Utility-токени є засобом взаємодії з сервісами або для отримання доступу до певних функцій, а також спеціальних привілеїв в екосистемах. Такі активи не можуть використовуватися для голосування в рамках ДАТ.
Що таке токен управління?
Токен управління (або governance-токен) – цифровий актив, власники якого можуть голосувати з ключових питань розвитку блокчейн-проекту в рамках децентралізованої автономної організації.
Остання може приймати рішення щодо:
визначення величини різних комісій протоколу та їхнього розподілу серед учасників екосистеми;
змін інтерфейсу користувача;
створення та наповнення фонду розвитку проекту;
грантів розробникам тощо.
Багато криптоактивів в DeFi-екосистемі є governance-токени. Юзкейси останніх не обмежуються лише голосуваннями. Такі монети зазвичай можна задіяти у стейкінгу, лендингових протоколах та прибутковому фермерстві.
Існують рейтинги токенів управління, де вони відсортовані за зменшенням ринкової капіталізації.
Що таке utility-токен?
Utility-токени – криптоактиви, призначені для конкретних юзкейсів у певних екосистемах. Їх також називають нативними чи утилітарними токенами.
Такі активи також відтворюють механіку газу мережі Ethereum. Наприклад, utility-токен MATIC екосистеми Polygon використовується для оплати трансакційних комісій.
Basic Attention Token (BAT) дозволяє винагороджувати користувачів браузера Brave за їхню увагу до рекламних матеріалів, а також виступати як форма оплати рекламодавцям.
У деяких випадках utility-токен необхідний для доступу до платформи, але частіше він застосовується опціонально, для використання певних функцій або привілеїв.
Наприклад, власники BNB отримують знижку на торгові комісії при взаємодії із централізованою біржею Binance, а також можливість підтримки нових проектів на платформі Launchpad.
Цей актив є ключовим елементом BNB Chain. Крім того, він задіяний для оплати трансакційних комісій під час операцій у DeFi-екосистемі.
LINK, нативний токен Chainlink, використовується в основному для оплати роботи операторів нід, на базі яких функціонують оракули децентралізованої мережі.
У чому основні відмінності gobernance-токенів від utility-токенов?
Токени управління багато в чому нагадують прості акції у традиційних фінансах, що дозволяють голосувати з ключових питань громадських компаній.
Утримувачі таких блокчейн-активів виносять, приймають чи відхиляють пропозиції у межах ДАТ.
Таким чином, gobernance-токени — ключовий елемент децентралізованих систем, інструмент прямої демократії.
У свою чергу, utility-токени не дають права голосу – лише можливість застосування у певних юзкейсах. Більшість таких активів є чимось на кшталт урізаної версії governance-токенів.
У чому переваги та недоліки governance-і utility-токенів?
Перерахуємо головні переваги токенів управління:
Децентралізація . Лише при використанні таких активів DeFi-програми можна називати децентралізованими. Без governance-токенів платформи були б безликими наборами смарт-контрактів, підконтрольними лише розробникам та засновникам.
Можливості для співробітництва . Голосування закладають основу конструктивних дискусій щодо майбутнього проектів. Обговорення у свою чергу створюють стимули для співпраці учасників екосистеми.
Залучення . Governance-токени є важелями впливу на майбутнє блокчейн-проектів, які мотивують власників брати участь у голосуваннях.
Є й підводне каміння:
Елементи прямої демократії не гарантують, що проект неодмінно розвиватиметься у правильному напрямку. Завжди є учасники ДАТ, які керуються насамперед егоїстичними інтересами. Серед таких гравців можуть бути великі власники токенів, здатні суттєво впливати на результати голосування.
Якщо ухвалене співтовариством рішення виявиться неоптимальним і в результаті нашкодить проекту, винна буде більшість. Отже, ніхто з учасників ДАТ не відповідатиме.
У кожній децентралізованій автономній організації є власники великої кількості державних-токенів. Вони здатні самостійно створювати пропозиції і домагатися прийнятних собі результатів. Останні можуть суперечити інтересам інших учасників спільноти. Отже, механізм розподілу токенів управління має бути добре продуманий.
Через правову невизначеність безліч проектів і, відповідно, активів можуть привернути увагу регуляторів.
Володіння utility-токенами також може бути пов’язане із значними ризиками. Наприклад, під час «ICO -лихоманки» 2017-2018 років було створено безліч «пустушок», які не мають фундаментальної вартості та перспектив. Такі активи часто випускалися шахраями, щоб отримати кошти початківців криптоінвесторів.
Є винятки – саме в ті роки відбулися токенсейли нині найбільшої централізованої біржі Binance та провідної некастодіальної платформи Uniswap.
Вартість та перспективи utility-токенів залежать від якості відповідного проекту та актуальності юзкейсу, в якому вони задіяні. Якщо платформа не має попиту, актив неухильно падає в ціні.
Utility-токени мало сприяють масовому прийняттю криптовалют, оскільки їхнє реальне застосування в основному обмежується окремими платформами та юзкейсами. Тому лише небагато з таких активів зберігали вартість протягом тривалих періодів часу.
Перше що я зробив це поїхав на сервіс перевірив систему на гермітичніст та заправив фріон.
Клімат запрацював. Але не працював додатковій вентілятор охолодження.
На сервісі сказали що треба міняти. Без нього не можна вмикати клімат а то видавить фріон.
Заказав вентілятор (не орігинал) і доробляв його щоб поставити.
Вийшов цілий сериал.
Що таке биткоин-пазли?
Біткоїн-пазли – це 75 гаманців, які містять 969 BTC (~$29,4 млн на момент публікації).
Будь-хто може забрати ці біткоїни, якщо підбере приватні ключі.
Створити аналогічні ігри не так вже й складно.
Хто і коли створив біткоін-пазли?
15 січня 2015 року анонім розподілив 32,9 BTC між 256 адресами: перший отримав 0,001 BTC, другий – 0,002 BTC, третій – 0,003 BTC і так далі, аж до 0,256 BTC.
Користувачі Bitcointalk помітили ці транзакції та виявили закономірність — приватні ключі до адрес у бінарному форматі починалися з нулів, кількість яких поступово зменшувалася.
ключ до першої адреси – 0 … 00000000001, один випадковий біт;
ключ до четвертої адреси – 0 … 00000001000, чотири випадкові біти;
Досі невідомо, хто стоїть за проектом, проте творець пазлів періодично нагадує себе. У 2017 році він перемістив біткоїни з адрес від №161 до №256 на «молодші» адреси. Швидше за все, через те, що в найближчому майбутньому неможливо підібрати ключ довше 160 бітів.
Чому адреси назвали пазлами?
Спільнота припускає , що творець головоломки хотів продемонструвати стійкість біткоін-адрес до перебору ключів. Користувачі ставляться до злому пазлів як завдання з винагородою, а чи не спробі крадіжки.
Анонім намагається підтримувати інтерес спільноти до гри. У квітні 2022 року він збільшив винагороди в 10 разів і забрав біткоїни з кожної п’ятої адреси.
На момент публікації не зламано 75 пазлів ( від №66 до №160 ) з балансами від 6,6 BTC (~$200 500) до 16 BTC (~$486 100). Загальна сума монет у пазлах складає 969 BTC (~$29,4 млн).
Як отримати біткоїни з пазлів?
Для вирішення биткоин-пазла потрібно підібрати приватний ключ до відповідної адреси.
У першу добу з моменту створення головоломки користувачі зламали 29 пазлів. Підбір ключів на адресу №40 зайняв два тижні, на адресу №47 — сім місяців, а на адресу №64 — п’ять років.
Найпростіший з пазлів, що залишилися, містить 66 випадкових бітів. Кількість можливих комбінацій – 7,37 * 10 ^ 19. Якщо перевіряти по мільярду варіантів на секунду на відеокарті GTX 1660 Ti, то на перевірку діапазону піде дві тисячі років.
Учасники спільноти створили десятки інструментів для вирішення пазлів. Ось кілька із них:
Private Key Finder — веб-додаток для підбору ключів до гаманців із біткоїнами та Ethereum. Використовує процесор комп’ютера, не потребує встановлення;
KeyHunt — програма з відкритим вихідним кодом для брутфорсу біткоін-ключів у заданому діапазоні. Використовує процесор, що працює на Linux;
BitCrack – ще один інструмент для брутфорсу приватних ключів. Використовує відеокарту, працює на Windows.
Щоб збільшити шанси підбору, можна приєднатися до пулу 66 Bit Collective . Його учасники розділили діапазон можливих рішень до пазла №66 на 33 млн. частин і перевіряють їх окремо. У разі успіху вони розділять нагороду пропорційно до кількості перевірених ключів.
Як створити біткоін-пазли?
Створити схожу головоломку можна у будь-якій мережі. Для цього потрібно повторити дії аноніма з 2015 року:
Згенерувати 256-бітові рядки, у яких випадковими є від 1 до 256 біт.
Перетворити кожен рядок на приватний ключ за криптографічною формулою обраного блокчейна.
Згенерувати публічні адреси.
Надіслати на них токени. Розмір нагород повинен відповідати кількості випадкових біт у ключі.
Історія біткоін-пазлів показала, що підбір ключів із 60 і більше випадкових бітів може зайняти кілька років.
Щоб зберегти інтерес до гри, варто використовувати кілька адрес з невеликою кількістю випадкових бітів та меншою винагородою, ніж додавати монети за кожний додатковий біт.
Якщо в тебе багато зайкого часу на вихідних, а також є гроші то можна купляти старий BMW X5 e53.
Як власники старих BMW, які люблять свої машини, проводять свої вихідні.
Що таке зрозумілий штучний інтелект (XAI)?
Зрозумілий штучний інтелект (Explainable AI, XAI) — напрямок досліджень у галузі ШІ, який прагне створити системи та моделі, здатні пояснювати свої дії та приймати рішення зрозумілим для людей чином.
Однією з основних проблем у навчанні сучасних штучних інтелектів є «чорна скринька»: системи можуть давати точні відповіді та виконувати складні завдання, але часто важко зрозуміти, яким чином вони дійшли цих результатів.
XAI може бути корисним у областях, де потрібен високий рівень зрозумілості прийнятих рішень, таких як медицина, фінанси, право.
Як визначити ШІ?
Штучний інтелект може бути складним та непрозорим для розуміння. Через це логічно виникає запит на зрозумілий штучний інтелект (Explainable AI, XAI).
Щоб розібратися в тому, що таке XAI, спочатку слід уважніше подивитися на ШІ взагалі. Технології штучного інтелекту – велика область, яка продовжує інтенсивно зростати. Однак універсального визначення для неї поки що не існує.
У 2021 році Європейська комісія представила регулятивну пропозицію, що дало б юридично обов’язкове визначення ШІ. У документі йдеться, що до штучного інтелекту належать системи, які роблять висновки, прогнози, рекомендації або приймають рішення, що впливають на навколишнє середовище.
Відповідно до юриста та дослідника ШІ Джейкоба Тернера, штучний інтелект також можна визначити як «здатність неприродної сутності приймати рішення на основі процесу оцінки». Об’єднавши визначення Європейської комісії та Тернера, можна сказати, що системи штучного інтелекту здатні «вчитися» і впливати на навколишнє середовище. Штучний інтелект не обмежується програмним забезпеченням, може проявлятися у різних формах, включаючи робототехніку.
Що таке «чорна скринька» в ШІ?
Штучний інтелект приймає «рішення» або створює вихідні дані на основі вхідних даних та алгоритмів. Завдяки здатності навчання та застосуванню різних технік та підходів, ШІ здатний робити це без прямого людського втручання. Це призводить до того, що ШІ-системи часто сприймають як «чорну скриньку».
Під «чорною скринькою» в даному випадку мається на увазі складність розуміння та контролю над рішеннями та діями, які виробляють системи та алгоритми ШІ. Це створює проблеми з прозорістю та відповідальністю, що, у свою чергу, несе різні правові та регуляторні наслідки.
Як цю проблему вирішує XAI?
Поняття зрозумілого штучного інтелекту виникло як у відповідь проблему «чорного ящика». XAI є підхід, спрямований на створення систем ШІ, результати яких можна пояснити в термінах, зрозумілих людині. Основна мета зрозумілого штучного інтелекту — зробити прийняття рішень у системах ШІ прозорим та доступним.
Можна виділити такі фактори, які роблять XAI значним компонентом у сфері розробки та використання ШІ:
Відповідальність. Якщо система ШІ приймає важливе для людини рішення (наприклад, відмова у кредиті або постановка медичного діагнозу), люди повинні розуміти, як і чому це рішення було ухвалено. Концепція XAI дозволить підвищити прозорість та відповідальність подібних процесів, позбавити суспільство від страхів, пов’язаних з використанням технологій ШІ.
Довіра. Люди радше довіряють системам, які вони розуміють. Якщо система ШІ може доступно пояснити свої рішення, люди охоче прийматимуть її рішення.
Поліпшення моделі. Якщо ми можемо зрозуміти, як система ШІ приймає свої рішення, ми можемо використовувати цю інформацію для покращення моделі. Це дозволить ефективно виявляти та усувати упередженості, робити систему точнішими, надійнішими та етичнішими.
Відповідність законодавству. У деяких юрисдикціях, наприклад, у Європейському Союзі із запровадженням Загального регламенту захисту даних (GDPR), потрібно, щоб організації могли пояснити рішення, прийняті з використанням автоматизованих систем.
Прозорість і зрозумілість можуть поступатися місцем іншим інтересам, таким як прибуток або конкурентоспроможність. Це наголошує на необхідності встановлення правильного балансу між інноваціями та етичними міркуваннями при розробці та застосуванні штучного інтелекту.
Підвищення довіри до державних та приватних систем ШІ має важливе значення. Воно стимулює розробників бути більш відповідальними і гарантує, що їх моделі не поширюватимуть дискримінаційних ідей. Крім того, це сприяє запобіганню незаконному використанню баз даних.
XAI відіграє ключову роль цьому процесі. Пояснення означає прозорість ключових факторів та параметрів, що визначають рішення ШІ. Хоча повна зрозумілість може бути недосяжною через внутрішню складність ШІ-систем, можливо встановити певні параметри та значення. Це робить штучний інтелект.
Які є приклади XAI?
Прикладами зрозумілого штучного інтелекту можуть бути різні техніки машинного навчання. Вони підвищують зрозумілість моделей ШІ через різні підходи:
Дерева рішень. Надають чітке візуальне подання процесу ухвалення рішень ШІ.
Системи з урахуванням правил . Визначають алгоритмічні правила у форматі, зрозумілому для людей. Вони можуть бути менш гнучкими щодо інтерпретації.
Байєсівські мережі. Імовірнісні моделі, які показують причинно-наслідкові зв’язки та невизначеності.
Лінійні моделі та аналогічні техніки в нейронних мережах. Ці моделі показують, як кожен вхідний параметр впливає на вихід.
Для досягнення XAI використовуються різні підходи, включаючи візуалізацію, пояснення природною мовою та інтерактивні інтерфейси. Інтерактивні інтерфейси, наприклад, дозволяють користувачам досліджувати, як передбачення моделі змінюються при зміні вхідних даних.
Візуальні інструменти, такі як карти інтенсивності та дерева.
У чому недоліки XAI?
Пояснимий штучний інтелект має кілька обмежень, деякі пов’язані з його застосуванням:
Складність розробки. Великі команди інженерів можуть працювати над алгоритмами протягом багато часу. Це ускладнює розуміння всього процесу розробки та вбудованих у системи ШІ принципів.
Неоднозначність терміна «зрозумілість». Це поняття, що широко трактується, яке може викликати різні інтерпретації при впровадженні XAI. Коли аналізуються ключові параметри та фактори в ШІ, виникають питання: що саме вважати «прозорим» чи «зрозумілим» і які межі цієї зрозумілості?
Швидкий розвиток ШІ. Штучний інтелект розвивається експоненційно. У поєднанні з бездоглядними системами та глибоким навчанням теоретично може досягти рівня загального інтелекту. Це відкриває шлях до нових ідей та інновацій, але й спричиняє додаткові складності при впровадженні XAI.
Які перспективи у XAI?
Розглянемо дослідження про «генеративних агентів», автори якого інтегрували мовні моделі ШІ з інтерактивними агентами. У ході експерименту була створена віртуальна пісочниця, що є маленьким містечком з двадцятьма п’ятьма віртуальними «жителями». Спілкуючись природною мовою, вони демонстрували реалістичну індивідуальну та соціальну поведінку. Так один агент «захотів» організувати вечірку, після чого агенти почали самостійно розсилати запрошення.
Слово «самостійно» тут украй важливе. Якщо системи ШІ демонструють поведінку, яку складно простежити до окремих компонентів, це може викликати наслідки, що складно прогнозуються.
XAI здатний запобігти або хоча б пом’якшити деякі ризики використання ШІ. Важливо пам’ятати, що зрештою відповідальність за рішення та дії, що ґрунтуються на ШІ, лежить на людях, навіть якщо не всі рішення штучного інтелекту можуть бути пояснені.
Матеріал підготовлений за участю мовних моделей, розроблених OpenAI. Інформація, представлена тут, частково ґрунтується на машинному навчанні, а не на реальному досвіді чи емпіричних дослідженнях.
BMW X5 e53 Як все починалось….
Преший огляд BMW X5 e53 після покупки. Треба багато чого виправляти. Але це і є саме цікаве.
Це як великий та не дешевий конструктор для дорослих )
Кому цікаво відео підписуйтесь на мій youtube канал BMW-ist та instagram
Також дав авто на українські ресурси DRIVER.TOP та єДрайв
Згорткові нейромережі: що це і для чого вони потрібні?
Згорткові нейронні мережі (Convolutional Neural Networks, CNN) – особливі типи нейронних мереж, які допомагають комп’ютерам бачити та розуміти зображення та відео.
Такі мережі мають кілька шарів, які називаються згортковими. Вони дозволяють CNN вивчати складні особливості та робити більш точні передбачення про вміст візуальних матеріалів.
Згорткові нейромережі застосовуються в тому числі для розпізнавання осіб, автопілотування, медичного прототипування та обробки природної мови.
Як влаштовані згорткові нейромережі?
CNN працюють, імітуючи людський мозок, та використовують набори правил, які допомагають комп’ютеру знаходити особливості у зображеннях, розуміти та інтерпретувати інформацію.
Кожен шар такої мережі обробляє дані та спрямовує виявлені особливості наступного шару для подальшої обробки. Вони використовуються фільтри, які допомагають виділити важливі особливості, наприклад краю чи форми об’єктів на зображенні.
Коли до візуального матеріалу застосовуються фільтри, ми отримуємо згорнуте зображення. Потім CNN його аналізує та виявляє важливі особливості. Цей процес називається вилученням ознак.
Крім згорткових шарів, CNN включають:
шари пулінгу, які зменшують розмір зображення, щоб мережа могла працювати швидше та краще узагальнювати дані;
шари нормалізації, які допомагають запобігти перенавченню та покращити продуктивність мережі;
солозв’язні шари, які використовуються для класифікації.
Як вони працюють?
Згорткові нейронні мережі працюють таким чином:
вхідні дані, такі як зображення або відео, надходять на вхідний шар;
згорткові шари отримують різні ознаки з вхідних даних. Вони використовують фільтри виявлення меж, форм, текстур та інших характеристик;
після кожного згорткового шару застосовується функція активації ReLU. Вона додає нелінійність та допомагає покращити продуктивність мережі;
далі слід шар пулінгу. Він зменшує розмірність карт ознак, вибираючи найважливіші значення кожної області;
повнозв’язні шари приймають вихідні дані з шару пулінгу і використовують набір ваги для класифікації або передбачення. Вони об’єднують виділені ознаки та приймають остаточне рішення.
Приклад виконання завдання.
Припустимо, згорткової нейронної мережі необхідно класифікувати зображення кішок та собак. Операція буде проведена за таким алгоритмом:
вхідний шар: отримує кольорові зображення собаки або кішки у форматі RGB, де кожен піксель представлений значеннями інтенсивності червоного, зеленого та синього кольорів;
згортковий шар: застосовує фільтри до зображення, щоб виділити характеристики, наприклад краю, кути та форми;
шар ReLU: додає нелінійність, застосовуючи функцію активації ReLU до виходу згорткового шару;
шар пулінга: Зменшує розмірність характеристик, вибираючи максимальні значення у кожному ділянці карти ознак;
повторення шарів: безліч згорткових та пулінгових шарів об’єднуються для вилучення все більш складних характеристик із вхідного зображення;
шар розгладжування: перетворює вихід попереднього шару одномерний вектор, що представляє всі характеристики;
повнозв’язковий шар: приймає розгладжений вихід та застосовує ваги для класифікації зображення як собаки чи кішки.
Згорткова нейромережа навчається на прикладах із зображеннями, які вже мають ярлики, що вказують, що на них зображено. У процесі навчання вага фільтрів та повнозв’язкових шарів змінюється, щоб знизити ймовірність помилок між прогнозами мережі та правильними відповідями.
Коли навчання закінчено, CNN може точно визначити, що зображено на нових, ще знайомих, зображеннях кішок і собак. Вона використовує отримані знання про ознаки та шаблони, щоб ухвалити правильне рішення про класифікацію.
Які існують типи згорткових нейронних мереж?
традиційні CNN , також відомі як «звичайні», складаються з серії згорткових та субдискретизуючих шарів, за якими слідують один або кілька повнозв’язкових шарів. Кожен згортковий шар у такій мережі виконує згортки з використанням фільтрів, що навчаються, для вилучення ознак з вхідного зображення. Прикладом традиційної CNN є архітектура Lenet-5, яка була однією з перших успішних нейронних згорткових мереж для розпізнавання рукописних цифр. Вона складається з двох наборів згорткових та субдискретизуючих шарів, за якими йдуть два повнозв’язні шари. Архітектура Lenet-5 продемонструвала ефективність CNN в ідентифікації зображень, і вони стали широко застосовуватися в галузі комп’ютерного зору;
рекурентні нейронні мережі (Recurrent Neural Networks, RNN )можуть обробляти послідовні дані з огляду на контекст попередніх значень. На відміну від звичайних нейронних мереж, які обробляють дані у фіксованому порядку, RNN можуть працювати з входами змінної довжини та робити висновки, що залежать від попередніх входів. Рекурентні нейромережі широко використовуються для обробки природної мови. Працюючи з текстами вони можуть лише генерувати текст, а й виконувати переклад. Для цього рекурентна нейромережа навчається на парних реченнях, складених двома різними мовами. RNN обробляє пропозиції по одному, створюючи вихідну речення, яка на кожному кроці залежить від вхідної. Завдяки цьому рекурентна нейромережа може правильно перекладати навіть складні тексти, оскільки вона враховує попередні входи та виходи, що дозволяє їй розуміти контекст;
повністю згорткові мережі (Fully Convolutional Networks, FCN) – широко використовуються в задачах комп’ютерного зору, таких як сегментація зображень, виявлення об’єктів та класифікація зображень. Вони навчаються від початку до кінця з використанням методу зворотного розповсюдження помилки (backpropagation) для категоризації чи сегментації зображень. Backpropagation допомагає нейронної мережі обчислити градієнти функції втрат за вагами. Функція втрат використовується для вимірювання того, наскільки добре модель машинного навчання передбачає очікуваний результат для заданого входу. На відміну від традиційних згорткових нейронних мереж, FCN не мають повнозв’язкових шарів і повністю базуються на згорткових шарах. Це робить їх більш гнучкими та ефективними для обчислень;
мережа просторових трансформацій (Spatial Transformer Network, STN) — застосовується у завданнях комп’ютерного зору поліпшення здатності нейронної мережі розпізнавати об’єкти чи візерунки на зображенні незалежно від розташування, орієнтації чи масштабу. Це називається просторовою інваріантністю. Прикладом використання STN є мережа, яка застосовує перетворення вхідного зображення перед його обробкою. Перетворення може включати вирівнювання об’єктів на зображенні, виправлення перспективних спотворень або інші зміни, що покращують роботу мережі у конкретній задачі. STN допомагає мережі обробляти зображення, враховуючи їх просторові особливості, та покращує її здатність розпізнавати об’єкти у різних умовах.
Які переваги у CNN?
Однією з головних переваг згорткових нейронних мереж є інваріантність до зсуву. Це означає, як уже було сказано вище, що CNN може розпізнавати об’єкти на зображенні незалежно від їхнього розташування.
Ще одна перевага – загальне використання параметрів. Це означає, що той самий набір параметрів застосовується для всіх частин вхідного зображення. Такий підхід дозволяє мережі бути більш компактною та ефективною, оскільки вона не повинна запам’ятовувати окремі параметри для кожної області матеріалу, що вивчається. Натомість вона узагальнює знання про ознаки на всьому зображенні, що особливо корисно при роботі з великими обсягами даних.
Інші переваги CNN включають ієрархічні уявлення, які дозволяють моделювати складні структури даних та стійкість до змін, що робить їх надійними для різних умов зображень. Крім того, згорткові мережі можуть бути навчені end-to-end, тобто навчання моделі відбувається по всьому шляху від вхідних даних до висновку, що прискорює процес навчання і підвищує загальну продуктивність мережі.
CNN можуть вивчати різні рівні параметрів вхідного зображення. Верхні шари мережі вивчають складніші характеристики, такі як частини та форми об’єктів, а нижні шари – простіші елементи, наприклад межі та текстури. Ця ієрархічна модель дозволяє розпізнавати об’єкти на різних рівнях абстракції, що є особливо корисним для складних завдань, таких як виявлення об’єктів та сегментація.
Крім того, CNN можуть бути навчені по всій мережі відразу. Це означає, що градієнтний спуск (алгоритм оптимізації) може одночасно оптимізувати всі параметри мережі для покращення її продуктивності та швидкої збіжності. Градієнтний спуск дозволяє моделі коригувати параметри з урахуванням інформації про помилку, щоб мінімізувати втрати у процесі навчання.
А які недоліки?
Для навчання CNN потрібен великий обсяг розмічених даних, і він часто займає багато часу. Це з високими вимогами до обчислювальної потужності.
Архітектура CNN, що включає кількість та тип шарів, може впливати на продуктивність мережі. Наприклад, додавання більшого числа шарів дозволяє підвищити точність моделі, але й збільшує складність мережі, а з нею вимоги до обчислювальних ресурсів. Глибокі архітектури CNN також страждають від перенавчання, коли мережа зосереджується на тренувальних даних та погано застосовує отримані знання до нових, невідомих даних.
У завданнях, де потрібне контекстне розуміння, наприклад, в обробці природної мови, згорткові мережі можуть мати обмеження. Для таких завдань найкращі інші типи нейронних мереж, які спеціалізуються на аналізі послідовностей та враховують контекстуальні залежності між елементами.
Незважаючи на ці недоліки, згорткові нейронні мережі все ще широко застосовуються і демонструють високу ефективність у глибокому навчанні. Вони є ключовим інструментом у галузі штучних нейромереж, особливо у завданнях комп’ютерного зору.
Матеріал підготовлений за участю мовних моделей розроблених OpenAI. Інформація, представлена тут, частково ґрунтується на машинному навчанні, а не на реальному досвіді чи емпіричних дослідженнях.
BMW X5 E53 або як відволектись від кодінгу
Жив собі нудно і не цікаво. Кодінг, сон, кодінг, і так по колу…
І я вирішив придбати собі BMW X5 E53 2004 з купою косяків. Не будучи механіком, я буду їх ремотнувати.
Тепер я буду ремонтувати свого малого BMW X5 E53 у вихідні дні без гаража та інструментів (інструмент буду докупати в процесі). Я буду вести відео-блог із процесом відновлення. І розповім, що я роблю і як)
Кому цікаво відео підписуйтесь на мій youtube канал BMW-ist та instagram
Також дав авто на українські ресурси DRIVER.TOP та єДрайв
Нейромережa – це математична модель, що працює за принципом людського мозку. Вона навчається шляхом первинної обробки великого набору даних, не вимагаючи написання окремого коду під конкретне завдання.
В останні роки комп’ютерні нейромережі набули великого розвитку. В основному їх використовують для завдань, де потрібно обробити текст, відео, аудіо та іншу інформацію.
Особливої популярності набули нейромережі, здатні швидко генерувати зображення з текстового запиту, поєднувати графічні об’єкти чи відтворювати відсутні елементи, зокрема людські обличчя. Вони не замінюють роботу дизайнерів та художників, але допомагають оптимізувати рутинні процеси.
Як нейромережі генерують зображення
Нейросети є одним із способів машинного навчання та лежать в основі алгоритмів глибокого навчання. Вони складаються з нейронів, які отримують, обробляють та повертають інформацію. Нейрони з’єднані між собою синапсами.
ІІ-моделі покладаються на навчальні дані для пошуку закономірностей та вирішення безлічі завдань на кшталт розпізнавання чи генерації зображень.
Наприклад, при пошуку схожих картинок за допомогою Google “Об’єктива” система також використовує нейромережу. Вона шукає подібність з іншими зображеннями з бази даних.
За подібним принципом алгоритми генерують ілюстрації з текстової підказки. Користувач вводить будь-який запит природною мовою і нейромережа комбінує відомі їй елементи.
Деякі моделі не здатні створювати зображення за текстом, але можуть накладати візуальні ефекти на готові картинки, стилізувати їх під роботи відомих художників або змінювати вибрані об’єкти.
Потенціал таких систем безмежний, особливо у сфері мистецтва. У 2022 році широку популярність набули ІІ-генератори зображень.
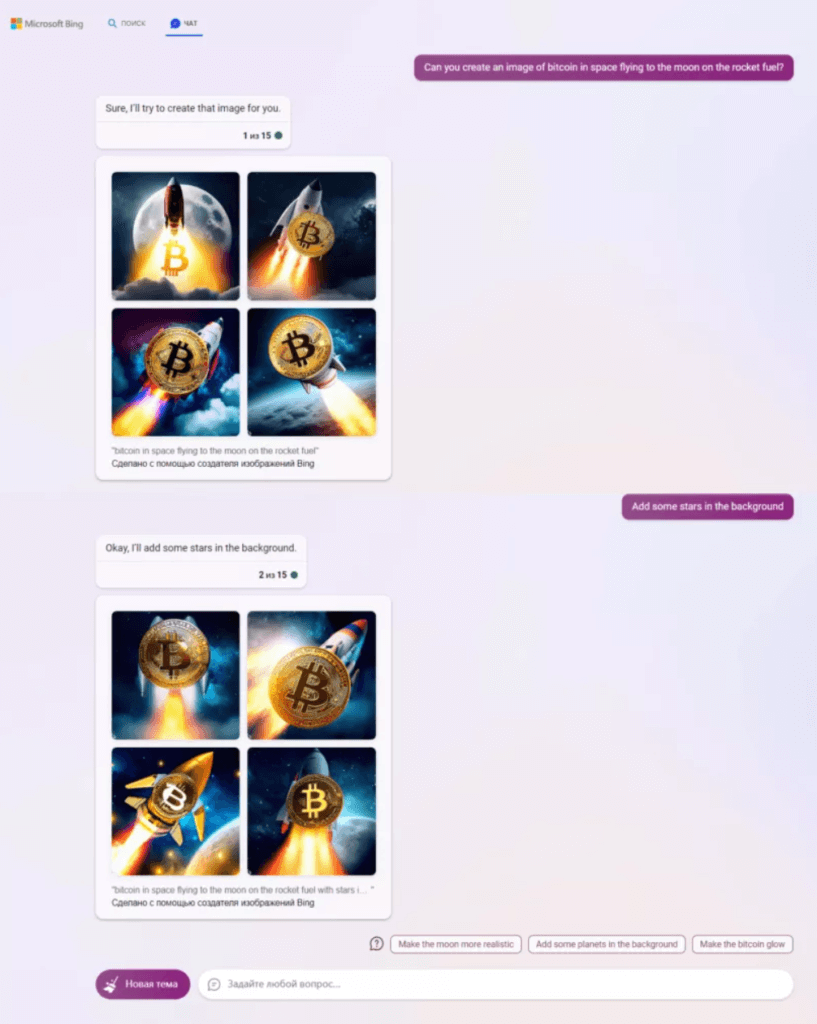
Сервіс від компанії Microsoft заснований на нейромережі DALL-E. У березні 2023 року техгігант запустив окремий сайт для інструментів та інтегрував його в чат Bing.
У жовтні 2022 року відбувся публічний реліз сервісу, що дозволило вільно реєструватися у сервісі та користуватися ним. Наразі система генерує понад 2 млн зображень на день. У той же час, щоб створити профіль у DALL-E 2, знадобиться номер телефону з обмеженого списку країн.
У квітні ІІ-генератор з’явився у браузері Edge. Він доступний з бічної панелі програм для користувачів по всьому світу.
Щоб застосувати сервіс, необхідно відкрити вікно браузера, ввести підказку і дочекатися результату. Image Creator згенерує чотири варіанти зображень, які можна завантажити.
Щоб уникнути використання інструменту для створення токсичного контенту, Microsoft запровадила власний механізм захисту на додаток до методів OpenAI.
Компанія також прямо уточнює, що зображення створюються штучним інтелектом та помічають результати водяними знаками.
Інструмент надає користувачам 25 бустерів на тиждень, призначених для прискорення створення картинок. Кожен запит списується один токен.
За вичерпанням бустерів, компанія пропонує отримати їх за бали системи винагороди Microsoft Rewards або дочекатися поновлення.
Веб-сервіс дозволяє створювати зображення безкоштовно та без реєстрації, але є Premium-версія. Також користувачам доступний мобільний додаток на Android та iOS .
Щоб створити картинку, потрібно ввести текстовий запит довжиною до 200 символів і вибрати стиль візуалізації. Через 10-20 секунд нейромережа видасть результат у роздільній здатності 960×1568 пікселів.
Готові зображення можна завантажити чи опублікувати у стрічці на сайті сервісу.
Опція “Редагувати з текстом” дозволяє за допомогою підказки змінити згенероване зображення. Можна перемалювати зображення, додати або видалити елемент, переробити стиль об’єкта або зробити інверсію ілюстрації.
Функція перебуває у беті і точність її досить низька.
У безкоштовній версії відредагувати малюнок можна лише двічі. Потім потрібно перезалити зображення або змінити нове.
Крім того, сервіс надає можливість на запит стилізувати власну картинку.
Premium-підписка коштує $9,99 на місяць або $89,99 на рік. Сервіс також пропонує користувачам можливість одноразового платежу $169,99.
Генератор зображень тексту, створений компанією Stability AI. У вересні 2022 року сервіс став доступним для широкої аудиторії.
Модель навчили створювати картинки за будь-яким текстовим запитом, включаючи зображення з громадськими діячами та оголеними людьми. Однак у листопаді 2022 року компанія оновила алгоритм, «послабивши» його здатність створювати NSFW-контент та ілюстрації у стилі конкретних художників.
Нейросеть малює безкоштовно.
Користувачеві достатньо ввести текстовий запит, який може складатися з будь-якої кількості слів. Потім модель згенерує чотири варіанти ілюстрації з роздільною здатністю 512×512 пікселів.
У грудні 2022 року засновник пошуковика для картинок та ІІ-підказок Lexica Шаріф Хамім представив генератор зображень Lexica Aperture. Алгоритм вміє створювати фотореалістичні ілюстрації на текстовий запит.
Нейросеть доступна безкоштовно після входу в систему через простий веб-інтерфейс. Вона створює зображення в книжковій або альбомній орієнтації з роздільною здатністю 768×1152 пікселів.
Під полем введення підказки можна вказати негативний запит — те, чого має бути малюнку. Також сервіс дозволяє завантажити референсну картинку.
Готове зображення можна розширити чи створити його варіації.
Платформа призначена для створення та редагування зображень. Сервіс вимагає реєстрації облікового запису та має обмеження на безкоштовне використання.
На сайті проекту є три режими роботи.
Text 2 Dream
Дозволяє створювати малюнки за текстовим описом. Користувачеві необхідно вигадати підказку або натиснути кнопку «рандомний запит».
Генератор працює відносно швидко, але іноді не дотягує рівня DALL-E 2 або Stable Diffusion. Це стосується інтерпретації слів та створених малюнків.
Deep Dream
Режим дозволяє проводити глибоке оброблення вихідного зображення за допомогою алгоритмів штучного інтелекту. Для цього потрібно завантажити картинку та задати параметри: початкову глибину, ІІ-посилення та шар нейромережі.
Deep Style
У цьому режимі користувач може стилізувати існуюче зображення. Йому потрібно завантажити картинку чи фото та вибрати референсну ілюстрацію зі списку.
Що стосується обмежень на безкоштовне використання, то при реєстрації облікового запису користувачеві нараховують 30 одиниць енергії. Вони згоряють при застосуванні інструментів: по п’ять балів за запит у Deep Style або Text 2 Dream та по два бали за звернення до Deep Dream.
Енергію можна докупити. Найдешевший тариф коштує $19 на місяць.
У січні 2021 року компанія OpenAI здійснила революцію в області ІІ, представивши генератор картинок за текстовим запитом DALL-E.
Це трансформер , побудований на базі великої мовної моделі GPT-3 з 12 млрд параметрів та навчений на парах «текст-зображення».
Нейросеть генерує зображення з роздільною здатністю 256×256 пікселів. Вона має різноманітний набір можливостей, включаючи створення антропоморфних тварин та об’єктів, реалістичне поєднання незв’язаних концепцій, рендеринг тексту та застосування перетворень до існуючих ілюстрацій.
У квітні 2022 року компанія випустила другу версію нейромережі, здатну з меншою затримкою генерувати реалістичні картинки з роздільною здатністю 1024×1024 пікселів.
DALL-E 2 дозволяє вибирати та редагувати певні області існуючих зображень, додавати або видаляти елементи разом із тінями, створювати колажі та варіації готових малюнків.
Також у новій версії нейромережі доступна функція Outpanting. З її допомогою можна розширити зображення за допомогою текстових підказок. При додаванні нових об’єктів система враховує існуючі візуальні елементи на кшталт тіней, відбитків та текстур.
У жовтні 2022 року OpenAI закрила список очікування для бета-версії генератора зображень.
Нейросеть доступна в усіх країнах, крім Афганістану, Білорусі, Венесуели, Ірану, Китаю та Росії.
У лютому 2023 року стало відомо, що Україну виключили зі списку держав, де заблоковано сервіси компанії. Однак алгоритми OpenAI не працюють на тимчасово окупованих Росією територіях.
Користувачі з регіонів, де технологія недоступна, зможуть взаємодіяти з DALL-E 2 тільки за наявності VPN-сервісу та активного телефонного номера з відкритої для продуктів OpenAI держави.
Реєстрація в DALL-E 2 безкоштовна. Для створення зображень будуть потрібні кредити, які списуються по одному при надсиланні кожного текстового запиту.
Раніше новим користувачам надавали безкоштовні спроби створення картинок. Однак нещодавно це змінилося.
Нейросеть стала платною для акаунтів, зареєстрованих після 6 квітня 2023 року. 115 спроб коштують $15.
При цьому користувачі, які створили обліковий запис раніше вказаної дати, досі можуть використовувати нейромережу безкоштовно. Вони отримають 50 кредитів, кількість яких за місяць зменшиться до 15. Кількість спроб відновлюється кожні 30 днів.
Різні компанії та відомі бренди використовують DALL-E 2. Журнали Cosmopolitan та The Economist задіяли нейромережу для генерації обкладинок. Microsoft запустила на базі сервісу власну програму Designer , яка вміє створювати контент на кшталт тексту, рекламних банерів, листівок та логотипів.