Створення власних синтаксичних конструкцій для JavaScript з використанням Babel
Oгляд
З початку давайте поглянемо на те, чого ми доб’ємося, діставшись до кінця цього матеріалу:
function @@ foo(a, b, c) {
return a + b + c;
}
console.log(foo(1, 2)(3)); // 6Ми збираємося реалізувати синтаксичну конструкцію @@, яка дозволяє каррірувати функції. Цей синтаксис схожий на той, що використовується для створення функцій-генераторів , але в нашому випадку замість знака * між ключовим словом function і ім’ям функції розміщується послідовність символів @@. В результаті при оголошенні функцій можна використовувати конструкцію виду function @@ name(arg1, arg2).
У вищенаведеному прикладі при роботі з функцією foo можна скористатися її частковим застосуванням . Виклик функції foo з передачею їй такої кількості параметрів, яке менше ніж кількість необхідних їй аргументів, призведе до повернення нової функції, здатної прийняти залишилися аргументи:
foo(1, 2, 3); // 6
const bar = foo(1, 2); // (n) => 1 + 2 + n
bar(3); // 6Я вибрав саме послідовність символів @@ тому, що в іменах змінних можна використовувати символ @. Це означає, що синтаксично коректно виявиться і конструкція виду function@@foo(){}. Крім того, «оператор» @ застосовується для функцій-декораторів , а мені хотілося використовувати щось абсолютно нове. В результаті я і вибрав конструкцію @@.
Для того щоб домогтися поставленої мети, нам потрібно виконати наступні дії:
- Створити форк парсеру Babel.
- Створити власний плагін Babel для трансформації коду.
Виглядає як щось неможливе?
Насправді, нічого страшного тут немає, ми разом все детально розберемо. Я сподіваюся, що ви, коли це дочитаєте, будете майстерно володіти тонкощами Babel.
Створення ФОРКу Babel
Зайдіть в репозиторій Babel на GitHub і натисніть на кнопку Fork, яка знаходиться в лівій верхній частині сторінки.
І, до речі, якщо тільки що ви вперше створили форк популярного опенсорсний проекту – прийміть вітання!
Тепер клонуйте форк Babel на свій комп’ютер і підготуйте його до роботи .
$ git clone https://github.com/tanhauhau/babel.git
# set up
$ cd babel
$ make bootstrap
$ make buildЗараз дозвольте мені в двох словах розповісти про організацію сховища Babel.
Babel використовує монорепозіторій. Всі пакети (наприклад – @babel/core, @babel/parser, @babel/plugin-transform-react-jsxі так далі) розташовані в папці packages/. Виглядає це так:
- doc
- packages
- babel-core
- babel-parser
- babel-plugin-transform-react-jsx
- ...
- Gulpfile.js
- Makefile
- ...Зазначу, що в Babel для автоматизації завдань використовується Makefile . При складанні проекту, що виконується командою make build, в якості менеджера завдань використовується Gulp .
Короткий курс по перетворенню коду в AST
Якщо ви не знайомі з такими поняттями, як «парсер» і «абстрактне синтаксичне дерево» (Abstract Syntax Tree, AST), то, перш ніж продовжувати читання, я настійно рекомендую вам поглянути на цей матеріал.
Якщо дуже коротко розповісти про те, що відбувається при парсінгу (синтаксичному аналізі) коду, то вийде наступне:
- Код, представлений у вигляді рядка (тип
string), виглядає як довгий список символів:f, u, n, c, t, i, o, n, , @, @, f, ... - На самому початку Babel виконує токенізацію коду. На цьому кроці Babel переглядає код та створює маркери. Наприклад – щось на кшталт
function, @@, foo, (, a, ... - Потім токени пропускають через парсер для їх синтаксичного аналізу. Тут Babel, на основі специфікації мови JavaScript, створює абстрактне синтаксичне дерево.
Ось відмінний ресурс для тих, хто хоче більше дізнатися про компіляторах.
Якщо ви думаєте, що «компілятор» – це щось дуже складне і незрозуміле, то знайте, що насправді все не так вже й таємниче. Компіляція – це просто парсинг коду і створення на його основі нового коду, який ми назвемо XXX. XXX-код може бути представлений машинним кодом (мабуть, саме машинний код – це те, що першим спливає в свідомості більшості з нас при думці про компіляторі). Це може бути JavaScript-код, сумісний з застарілими браузерами. Власне, однією з основних функцій Babel є компіляція сучасного JS-коду в код, зрозумілий застарілим браузерам.
Розробка власного парсеру для Babel
Ми збираємося працювати в папці packages/babel-parser/:
- src/
- tokenizer/
- parser/
- plugins/
- jsx/
- typescript/
- flow/
- ...
- test/Ми вже говорили про токенізаціі і про парсінгу. Знайти код, який реалізує ці процеси, можна в папках з відповідними іменами. В папці plugins/ містяться плагіни (Plug-in), які розширюють можливості базового парсеру і додають в систему підтримку додаткових синтаксисів. Саме так, наприклад, реалізована підтримка jsx і flow.
Давайте вирішимо нашу задачу, скориставшись технікою розробки через тестування (Test-driven development, TDD). По-моєму, легше за все спочатку написати тест, а потім, поступово працюючи над системою, зробити так, щоб цей тест виконувався б без помилок. Такий підхід особливо хороший при роботі в незнайомій кодової базі. TDD спрощує розуміння того, в які місця коду потрібно внести зміни для реалізації задуманого функціоналу.
packages/babel-parser/test/curry-function.js
import { parse } from '../lib';
function getParser(code) {
return () => parse(code, { sourceType: 'module' });
}
describe('curry function syntax', function() {
it('should parse', function() {
expect(getParser(`function @@ foo() {}`)()).toMatchSnapshot();
});
});Запуск тесту для babel-parserможна виконати так: TEST_ONLY=babel-parser TEST_GREP="curry function" make test-only. Це дозволить побачити помилки:
SyntaxError: Unexpected token (1:9)
at Parser.raise (packages/babel-parser/src/parser/location.js:39:63)
at Parser.raise [as unexpected] (packages/babel-parser/src/parser/util.js:133:16)
at Parser.unexpected [as parseIdentifierName] (packages/babel-parser/src/parser/expression.js:2090:18)
at Parser.parseIdentifierName [as parseIdentifier] (packages/babel-parser/src/parser/expression.js:2052:23)
at Parser.parseIdentifier (packages/babel-parser/src/parser/statement.js:1096:52)Якщо ви виявите, що перегляд всіх тестів займає надто багато часу, то можете, для запуску потрібного тесту, викликати jest безпосередньо:
BABEL_ENV=test node_modules/.bin/jest -u packages/babel-parser/test/curry-function.jsНаш парсер виявив 2 токена @, начебто безневинних, там, де їх бути не повинно.
Звідки я це дізнався? Відповідь на це питання нам допоможе знайти використання режиму моніторингу коду, що запускається командою make watch.
Перегляд стека викликів призводить нас до packages / babel-parser / src / parser / expression.js, де викидається виключення this.unexpected().
Додамо в цей файл пару команд логування:
packages/babel-parser/src/parser/expression.js
parseIdentifierName(pos: number, liberal?: boolean): string {
if (this.match(tt.name)) {
// ...
} else {
console.log(this.state.type); // текущий токен
console.log(this.lookahead().type); // следующий токен
throw this.unexpected();
}
}Як видно, обидва токена – це @:
TokenType {
label: '@',
// ...
}Як я дізнався про те, що конструкції this.state.type і this.lookahead().type дадуть мені поточний і наступний токени?
Про це я розповім в розділі даного матеріалу, присвяченому функціям this.eat, this.matchі this.next.
Перш ніж продовжувати – давайте підведемо короткі підсумки:
- Ми написали тест для
babel-parser. - Ми запустили тест за допомогою
make test-only. - Ми скористалися режимом моніторингу коду за допомогою
make watch. - Ми дізналися про стан парсера і вивели в консоль відомості про тип поточного токена (
this.state.type).
А зараз ми зробимо так, щоб 2 символи @сприймалися б не як окремі маркери, а як новий токен @@, той, який ми вирішили використовувати для каррінг функцій.
Новий токен: «@@»
Для початку заглянемо туди, де визначаються типи токенів. Мова йде про фото packages / babel-parser / src / tokenizer / types.js .
Тут можна знайти список токенов. Додамо сюди і визначення нового токена atat:
packages/babel-parser/src/tokenizer/types.js
export const types: { [name: string]: TokenType } = {
// ...
at: new TokenType('@'),
atat: new TokenType('@@'),
};Тепер давайте пошукаємо то місце коду, де, в процесі токенізаціі, створюються токени. Пошук послідовності символів tt.atв babel-parser/src/tokenizer приводить нас до файлу: packages / babel-parser / src / tokenizer / index.js . У babel-parser типи токенів імпортуються як tt.
Тепер, в тому випадку, якщо після поточного символу @ йде ще один @, створимо новий токен tt.atat замість токена tt.at:
packages/babel-parser/src/tokenizer/index.js
getTokenFromCode(code: number): void {
switch (code) {
// ...
case charCodes.atSign:
// якщо наступний символ - это `@`
if (this.input.charCodeAt(this.state.pos + 1) === charCodes.atSign) {
// создадим `tt.atat` вместо `tt.at`
this.finishOp(tt.atat, 2);
} else {
this.finishOp(tt.at, 1);
}
return;
// ...
}
}Якщо знову запустити тест – то можна помітити, що відомості про поточному і наступному токенах змінилися:
// поточний токен
TokenType {
label: '@@',
// ...
}
// наступний токен
TokenType {
label: 'name',
// ...
}Це вже виглядає досить-таки непогано. Продовжимо роботу.
Новий парсер
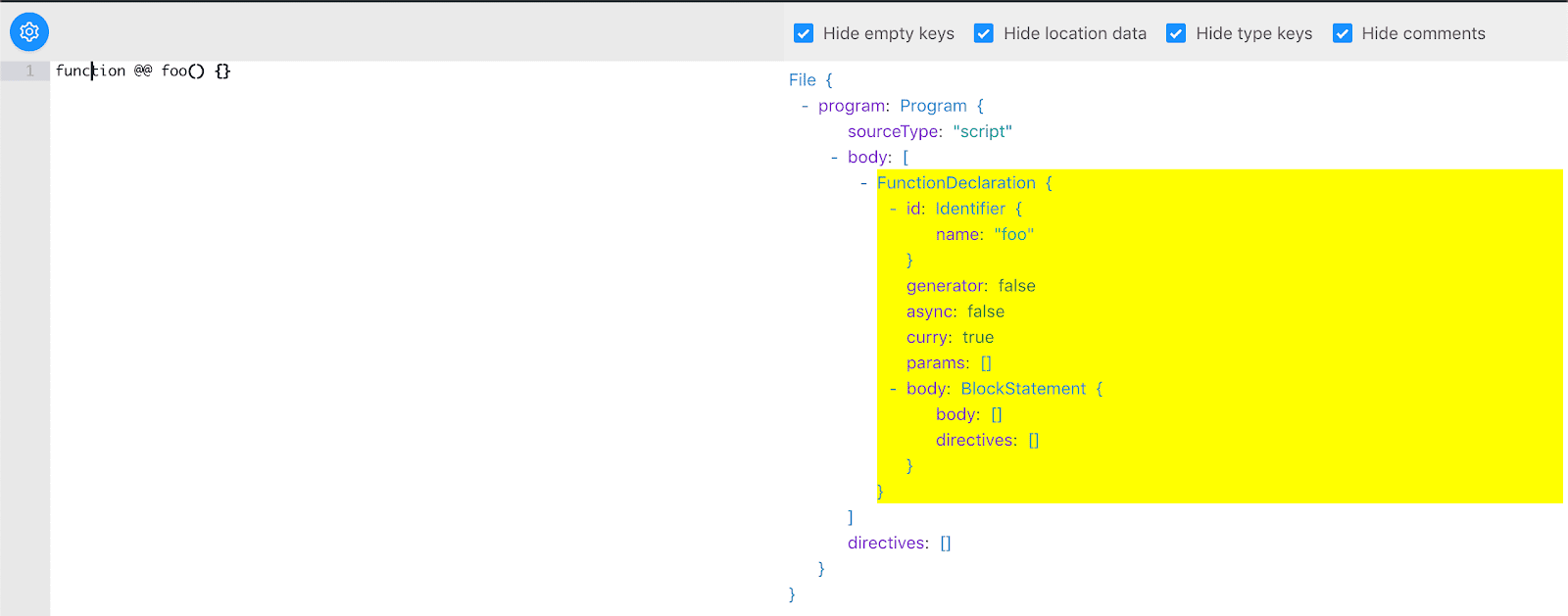
Перш ніж рухатися далі – поглянемо на те, як функції-генератори представлені в AST.

Як бачите, на те, що це – функція-генератор, вказує атрибут generator: true сутності FunctionDeclaration.
Ми можемо застосувати аналогічний підхід для опису функції, що підтримує каррінг. А саме, ми можемо додати до FunctionDeclaration атрибут curry: true.
Власне кажучи, тепер у нас є план. Займемося його реалізацією.
Якщо пошукати в коді по слову FunctionDeclaration – можна вийти на функцію parseFunction, яка оголошена в packages / babel-parser / src / parser / statement.js . Тут можна знайти рядок, в якій встановлюється атрибут generator. Додамо в код ще один рядок:
packages/babel-parser/src/parser/statement.js
export default class StatementParser extends ExpressionParser {
// ...
parseFunction<T: N.NormalFunction>(
node: T,
statement?: number = FUNC_NO_FLAGS,
isAsync?: boolean = false
): T {
// ...
node.generator = this.eat(tt.star);
node.curry = this.eat(tt.atat);
}
}Якщо ми знову запустимо тест, то нас чекатиме приємна несподіванка. Код успішно проходить тестування!
PASS packages/babel-parser/test/curry-function.js
curry function syntax
✓ should parse (12ms)І це все? Що ми такого зробили, щоб тест дивним чином опинився пройденим?
Для того щоб це з’ясувати – давайте поговоримо про те, як працює парсинг. В процесі цієї розмови, сподіваюся, ви зрозумієте те, як подіяла на Babel рядок node.curry = this.eat(tt.atat);.
Як працює парсинг
Парсер отримує список токенов від системи токенізаціі коду і, по одному розглядаючи токени, будує AST. Для того щоб прийняти рішення про те, як саме використовувати маркери, і зрозуміти, який токен можна очікувати наступним, парсер звертається до специфікації граматики мови.
Специфікація граматики виглядає приблизно так:
...
ExponentiationExpression -> UnaryExpression
UpdateExpression ** ExponentiationExpression
MultiplicativeExpression -> ExponentiationExpression
MultiplicativeExpression ("*" or "/" or "%") ExponentiationExpression
AdditiveExpression -> MultiplicativeExpression
AdditiveExpression + MultiplicativeExpression
AdditiveExpression - MultiplicativeExpression
...Вона описує пріоритет виконання виразів або операторів. Наприклад, вираз AdditiveExpression може представляти одна з наступних конструкцій:
- Вираз
MultiplicativeExpression. - Вираз
AdditiveExpression, за яким слід токен оператора «+», за яким слід виразMultiplicativeExpression. - Вираз
AdditiveExpression, за яким слід токен «-», за яким слід виразMultiplicativeExpression.
В результаті, якщо у нас є вираз 1 + 2 * 3, то воно буде виглядати так:
(AdditiveExpression "+" 1 (MultiplicativeExpression "*" 2 3))А ось таким воно не буде:
(MultiplicativeExpression "*" (AdditiveExpression "+" 1 2) 3)Програма, з використанням цих правил, перетворюється в код, що видається парсером:
class Parser {
// ...
parseAdditiveExpression() {
const left = this.parseMultiplicativeExpression();
// якщо поточний токен - це `+` чи `-`
if (this.match(tt.plus) || this.match(tt.minus)) {
const operator = this.state.type;
// перейти до наступного токену
this.nextToken();
const right = this.parseMultiplicativeExpression();
// создати вузол
this.finishNode(
{
operator,
left,
right,
},
'BinaryExpression'
);
} else {
// вернути MultiplicativeExpression
return left;
}
}
}Зверніть увагу на те, що тут наведено надзвичайно спрощений варіант того, що насправді присутній в Babel. Але я сподіваюся, що цей фрагмент коду дозволяє проілюструвати сутність того, що відбувається.
Як бачите, парсер, за своєю природою, рекурсівен. Він переходить від конструкцій з найнижчим пріоритетом до конструкцій з найвищим пріоритетом. Наприклад – parseAdditiveExpression викликає parseMultiplicativeExpression, а ця конструкція викликає parseExponentiationExpression і так далі. Цей рекурсивний процес називають синтаксичним аналізом методом рекурсивного спуску ( Recursive Descent Parsing ).
Функції this.eat, this.match, this.next
Можливо, ви помітили, що в раніше наведених прикладах використовувалися деякі допоміжні функції, такі, як this.eat, this.match, this.nextта інші. Це – внутрішні функції парсера Babel. Подібні функції, правда, не унікальні для Babel, вони зазвичай присутні і в інших парсером.
- Функція
this.matchповертає логічне значення, яке вказує на те, чи відповідає поточний токен заданій умові. - Функція
this.nextздійснює переміщення за списком токенов вперед, до наступного токені. - Функція
this.eatповертає той же, що повертає функціяthis.match, при цьому, якщоthis.matchповертаєtrue, тоthis.eatвиконує, перед поверненнямtrue, викликthis.next. - Функція
this.lookaheadдозволяє отримати наступний токен без переміщення вперед, що допомагає прийняти рішення по поточному вузлу.
Якщо ви знову поглянете на змінений нами код парсера, то виявите, що читати його стало набагато легше:
packages/babel-parser/src/parser/statement.js
export default class StatementParser extends ExpressionParser {
parseStatementContent(/* ...*/) {
// ...
// NOTE: мы викликаємо match для перевірки поточного токену
if (this.match(tt._function)) {
this.next();
// NOTE: у оголошення функції пріоритет вище, ніж у звичайного виразу
this.parseFunction();
}
}
// ...
parseFunction(/* ... */) {
// NOTE: ми викликаємо eat для перевірки існування необов'язкового токена
node.generator = this.eat(tt.star);
node.curry = this.eat(tt.atat);
node.id = this.parseFunctionId();
}
}Можливо, вам цікаво дізнатися про те, як я зміг візуалізувати створений мною синтаксис в Babel AST Explorer, коли показував новий атрибут « curry», що з’явився в AST.
Це стало можливим завдяки тому, що я додав в Babel AST Explorer нову можливість, яка дозволяє завантажити в це засіб дослідження AST власний парсер.
Якщо перейти по шляху packages/babel-parser/lib, то можна знайти скомпільовану версію парсеру і карту коду. В панелі Babel AST Explorerможна побачити кнопку для завантаження власного парсеру. завантажившиpackages/babel-parser/lib/index.js можна візуалізувати AST, сгенерированное за допомогою власного парсеру.

Наш плагін для Babel
Тепер, коли завершена робота над парсером – давайте напишемо плагін для Babel.
Але, можливо, зараз у вас є деякі сумніви щодо того, як саме ми збираємося користуватися власним парсером Babel, особливо з огляду на те, який саме стек технологій ми застосовуємо для збірки проекту.
Правда, побоюватися тут нема чого. Плагін Babel може надавати можливості парсеру. Відповідну документацію можна знайти на сайті Babel.
babel-plugin-transformation-curry-function.js
import customParser from './custom-parser';
export default function ourBabelPlugin() {
return {
parserOverride(code, opts) {
return customParser.parse(code, opts);
},
};
}Так як ми створили форк парсеру Babel, це означає, що всі існуючі можливості парсеру, а також вбудовані плагіни, продовжать працювати абсолютно нормально.
Після того, як ми позбулися цих сумнівів, давайте поглянемо на те, як зробити функцію такою, щоб вона підтримувала б каррінг.
Якщо ви не винесли очікування і вже спробували додати наш плагін в свою систему збирання проекту, ви могли помітити, що функції, які підтримують каррінг, компілюються в звичайні функції.
Відбувається це через те, що після парсинга і трансформації коду Babel використовує @babel/generatorдля генерування коду з трансформованого AST. Так як @babel/generatorнічого не знає про новий атрибут curry, він його просто ігнорує.
Якщо коли-небудь функції, що підтримують каррінг, увійдуть в стандарт JavaScript, то вам, можливо, захочеться зробити PR на додавання сюди нового коду.
Для того щоб зробити так, щоб функція підтримувала б каррінг, її можна обернути в функцію вищого порядку currying:
function currying(fn) {
const numParamsRequired = fn.length;
function curryFactory(params) {
return function (...args) {
const newParams = params.concat(args);
if (newParams.length >= numParamsRequired) {
return fn(...newParams);
}
return curryFactory(newParams);
}
}
return curryFactory([]);
}Якщо вас цікавлять особливості реалізації механізму каррінг функцій в JS – погляньте на цей матеріал.
В результаті ми, перетворюючи функцію, яка підтримує каррінг, можемо вчинити так:
// з цього
function @@ foo(a, b, c) {
return a + b + c;
}
// отримуєм це
const foo = currying(function foo(a, b, c) {
return a + b + c;
})Поки не звертатимемо на механізм підняття функцій в JavaScript, який дозволяє викликати функцію fooдо її визначення.
Ось як виглядає код трансформації:
babel-plugin-transformation-curry-function.js
export default function ourBabelPlugin() {
return {
// ...
<i> visitor: {
FunctionDeclaration(path) {
if (path.get('curry').node) {
// const foo = curry(function () { ... });
path.node.curry = false;
path.replaceWith(
t.variableDeclaration('const', [
t.variableDeclarator(
t.identifier(path.get('id.name').node),
t.callExpression(t.identifier('currying'), [
t.toExpression(path.node),
])
),
])
);
}
},
},</i>
};
}Вам набагато легше буде в ньому розібратися в тому випадку, якщо ви читали цей матеріал про трансформації в Babel.
Тепер перед нами виникає питання про те, як надати цьому механізму доступ до функції currying. Тут можна скористатися одним з двох підходів.
№1: можна припустити, що функція currying оголошена в глобальному контексті
Якщо це так, то справа вже зроблена.
Якщо ж при виконанні скомпільованої коду виявляється, що функція curryingне визначена, то ми зіткнемося з повідомленням про помилку, дивлячому як « currying is not defined». Воно дуже схоже на повідомлення « regeneratorRuntime is not defined ».
Тому, якщо хтось буде користуватися вашим плагіном babel-plugin-transformation-curry-function, то вам, можливо, доведеться повідомити йому про те, що йому, для забезпечення нормальної роботи цього плагіна, потрібно встановити поліфілл currying.
№2: можна скористатися babel / helpers
Можна додати нову допоміжну функцію в @babel/helpers. Ця розробка навряд чи буде об’єднана з офіційним репозиторієм @babel/helpers. В результаті вам доведеться знайти спосіб показати @babel/coreмісце розташування вашого коду @babel/helpers:
package.json
{
"resolutions": {
"@babel/helpers": "7.6.0--your-custom-forked-version",
}Я сам це не пробував, але думаю, що цей механізм буде працювати.
Додати нову допоміжну функцію в @babel/helpersдуже просто.
Спочатку треба перейти в файл packages / babel-helpers / src / helpers.js і додати туди новий запис:
helpers.currying = helper("7.6.0")`
export default function currying(fn) {
const numParamsRequired = fn.length;
function curryFactory(params) {
return function (...args) {
const newParams = params.concat(args);
if (newParams.length >= numParamsRequired) {
return fn(...newParams);
}
return curryFactory(newParams);
}
}
return curryFactory([]);
}
`;При описі допоміжної функції вказується необхідна версія @babel/core. Деякі складнощі тут може викликати експорт за замовчуванням ( export default) функції currying.
Для використання допоміжної функції досить просто викликати this.addHelper():
// ...
path.replaceWith(
t.variableDeclaration('const', [
t.variableDeclarator(
t.identifier(path.get('id.name').node),
t.callExpression(this.addHelper("currying"), [
t.toExpression(path.node),
])
),
])
);Команда this.addHelper, при необхідності, запровадить допоміжну функцію в верхню частину файлу, і поверне Identifier, який вказує на впроваджену функцію.
Підсумки
Тут ми поговорили про те, як модифікувати можливості парсеру Babel, ми написали власний плагін трансформації коду, коротко поговорили про @babel/generatorі про створення допоміжних функцій за допомогою @babel/helpers. Відомості, що стосуються трансформації коду, тут дано лише схематично. Детальніше про них можна почитати тут .
У процесі роботи ми торкнулися деяких особливостей роботи парсеров. Якщо вам ця тема цікава – то ось , ось і ось – ресурси, які вам знадобляться.
Виконана нами послідовність дій дуже схожа на частину того процесу, який виконується під час вступу до TC39 пропозиції нової можливості JavaScript. ось сторінка сховища TC39, на якій можна знайти відомості про поточні пропозиції. тут можна знайти більш докладні відомості про порядок роботи з подібними пропозиціями. При пропонуванні нової можливості JavaScript, той, хто її пропонує, зазвичай пише поліфілли або, роблячи форк Babel, готує демонстрацію, яка доводить працездатність пропозиції. Як ви могли переконатися, створення Форк парсеру або написання поліфілла – це не найскладніша частина процесу пропозиції нових можливостей JS. Складно визначити предметну область нововведення, спланувати і продумати варіанти його використання і прикордонні випадки; складно зібрати думки і пропозиції членів спільноти JavaScript-програмістів. Тому я хотів би висловити вдячність усім тим, хто знаходить в собі сили пропонувати TC39 нові можливості JavaScript, розвиваючи таким чином ця мова.
Ось сторінка на GitHub, яка дозволить вам побачити загальну картину того, чим ми тут займалися.
Переклад статті “Creating custom JavaScript syntax with Babel“