Що таке NFT?

NFT (невзаємозамінні токени, від англ. Non-Fungible Tokens) — це цифрові активи, які є унікальними та неповторними. Вони засновані на технології блокчейну і забезпечують право власності на об’єкти криптографічних токенів. Складніше за своєю суттю ніж криптовалюти, NFT створюють цифровий світ, де кожен об’єкт є унікальним.
Основи NFT
Що означає “невзаємозамінність”?
У фінансах замінні активи можна вільно обмінювати між собою. Наприклад, 1 биткоїн однаковий з іншим биткоїном. Невзаємозамінні активи унікальні і не можуть бути однаковими з іншими. Кожний NFT має свій унікальний код.
Як працюють NFT?
NFT функціонують на блокчейнах, таких як Ethereum, Polygon або Solana. Вони використовують смарт-контракти, які забезпечують автоматизоване виконання умов угод.
- Кожен NFT є унікальним. Запис про нього записується у блокчейні і забезпечується криптографією.
- Підтвердження власності. Тільки той, хто має приватний ключ від NFT, є його справжнім власником.
- Можливість перепродажу. NFT можна передавати чи продавати, що дозволяє створювати вторинний ринок.
Приклади використання NFT
Мистецтво
NFT стали популярними серед художників. Завдяки блокчейну автори можуть продавати свої роботи без посередників, отримуючи роялті за кожну наступну перепродажу. Наприклад, колекція Beeple була продана за понад $69 мільйонів на аукціоні.
Ігрова індустрія
У відеоіграх NFT використовуються для створення внутрішньоігрових активів, які гравці можуть купувати, продавати чи обмінювати. Це додає додаткову цінність грі, оскільки активи стають справжньою власністю гравців.
Колекціонування
NFT відкривають нові можливості для цифрового колекціонування. Відомі бренди, такі як NBA, створюють колекції цифрових карток, які можна зберігати або обмінювати.
Музика
Музиканти використовують NFT для продажу альбомів, квитків на концерти чи навіть ексклюзивного контенту, доступного лише власникам токенів.
Нерухомість
NFT знаходять застосування у віртуальній нерухомості. Платформи, такі як Decentraland або The Sandbox, дозволяють купувати, продавати й будувати на віртуальних землях.
Переваги NFT
- Прозорість. Усі транзакції записуються у блокчейні, що забезпечує прозорість і відсутність шахрайства.
- Додатковий дохід. Художники, музиканти й творці контенту можуть отримувати роялті за кожну перепродажу їхніх NFT.
- Цифрова унікальність. Кожен NFT — це унікальний цифровий актив із підтвердженням права власності.
Виклики NFT
- Волатильність. Ціна на NFT може різко змінюватися, що робить інвестиції ризикованими.
- Екологічний вплив. Деякі блокчейни споживають багато енергії, що викликає екологічні занепокоєння.
- Юридичні питання. Регуляторна база для NFT поки що недостатньо розвинена.
Як створити NFT
- Вибір блокчейну. Найпопулярнішими платформами є Ethereum, Binance Smart Chain, Solana.
- Налаштування гаманця. Створіть криптогаманець, наприклад MetaMask.
- Мінтинг. Використовуйте платформи, такі як OpenSea чи Rarible, щоб створити NFT, завантаживши цифровий файл (зображення, аудіо тощо).
- Продаж. Виставте NFT на продаж на маркетплейсі.
Майбутнє NFT
NFT мають потенціал змінити багато галузей, роблячи власність більш прозорою та ефективною. У майбутньому очікується розширення сфер використання NFT, зокрема в освіті, юриспруденції та охороні здоров’я. Цифрові дипломи, сертифікати й ліцензії можуть бути переведені в NFT для спрощення перевірки та підвищення довіри.
Нові галузі застосування
- Освіта. Дипломи й сертифікати можна оцифрувати у вигляді NFT, що дозволить роботодавцям швидко перевіряти автентичність документів.
- Охорона здоров’я. Медичні записи можуть зберігатися в NFT-форматі, що забезпечить безпеку даних і зручність доступу для пацієнтів і лікарів.
- Юридичні послуги. Контракти, підписані у вигляді NFT, можуть автоматично виконуватися завдяки смарт-контрактам.
Використання в реальному світі
Популярність NFT також зростає в індустрії подорожей та розваг. NFT-квитки можуть стати стандартом у майбутньому для концертів, подій і транспортних послуг, дозволяючи боротися з підробками і перепродажами за спекулятивними цінами.
NFT — це більше, ніж просто цифрові зображення чи ігрові предмети. Це інструмент, який може змінити багато аспектів нашого життя, роблячи їх більш прозорими, безпечними та ефективними. Хоча перед цією технологією стоять виклики, її потенціал важко переоцінити.
Proof-of-Event: NFT-квитки в майбутнє Web3
Уявіть світ, де квиток на концерт чи конференцію не лише дає вам доступ до події, але й стає вашим цифровим сувеніром, підтвердженням участі та навіть ключем до додаткових переваг. Це реальність, яку створюють NFT-квитки, засновані на технології Proof-of-Event (доказ події) у Web3.
Що таке Proof-of-Event?
Proof-of-Event — це концепція, що використовує технологію блокчейну для підтвердження участі в події. Вона дозволяє організаторам подій видавати незмінні цифрові записи (NFT-квитки), які зберігають інформацію про власника, подію та інші пов’язані дані. Завдяки блокчейну ці записи є безпечними, прозорими та доступними для перевірки.
Як працюють NFT-квитки?
NFT (невзаємозамінні токени) — це унікальні цифрові активи, які зберігаються у блокчейні. NFT-квиток містить усю необхідну інформацію про подію, таку як:
- Назва події;
- Дата й час;
- Місце проведення;
- Ім’я власника квитка;
- Додаткові переваги (наприклад, доступ до закулісся).
Процес роботи NFT-квитків:
- Створення: Організатор події створює NFT-квитки за допомогою смарт-контрактів на платформі блокчейну (наприклад, Ethereum або Polygon).
- Продаж: Квитки продаються на маркетплейсах NFT (наприклад, OpenSea) або через спеціалізовані платформи.
- Зберігання: Квиток зберігається у криптогаманці покупця, що підтверджує право власності.
- Перевірка: На вході до події система сканує NFT-квиток у гаманці, щоб перевірити його дійсність.
Переваги NFT-квитків
1. Запобігання підробкам
Квитки на основі блокчейну не можна підробити чи дублювати. Завдяки прозорості технології кожен квиток можна перевірити за його унікальним записом у блокчейні.
2. Нові можливості монетизації
NFT-квитки можуть включати функції, які приносять додатковий дохід організаторам, наприклад, роялті від перепродажу квитків.
3. Додаткові привілеї для власників
Крім доступу до події, NFT-квиток може надавати:
- Ексклюзивний контент;
- Знижки на майбутні події;
- Доступ до приватних спільнот.
4. Колекційна цінність
NFT-квитки стають цифровими сувенірами, які можна зберігати чи перепродати як колекційні предмети.
Використання NFT-квитків у різних галузях
Музичні події
NFT-квитки використовуються для концертів, фестивалів та інших заходів. Наприклад, виконавець може надати власникам квитків доступ до закулісних відео або автограф-сесій.
Спортивні події
На спортивних подіях NFT-квитки можуть включати доступ до ексклюзивних зон чи право на купівлю сувенірів із знижкою.
Конференції та навчання
Учасники конференцій отримують NFT-квитки, які підтверджують їх участь і надають доступ до записів виступів чи навчальних матеріалів.
Ігрова індустрія
NFT-квитки можуть бути використані для доступу до ігрових подій, турнірів або внутрішньоігрових активів.
Виклики та ризики
1. Технічна складність
Для багатьох користувачів взаємодія з блокчейном може бути складною через необхідність розуміння криптовалют і гаманців.
2. Волатильність ринку
Ціна NFT-квитків може коливатися через нестабільність криптовалютного ринку.
3. Екологічний вплив
Деякі блокчейни споживають велику кількість енергії, що викликає занепокоєння щодо екології. Проте блокчейни з низьким споживанням енергії, такі як Polygon, допомагають вирішити цю проблему.
4. Правові питання
У багатьох країнах регуляції для NFT ще не до кінця визначені, що створює юридичну невизначеність.
Як розпочати використовувати NFT-квитки
- Оберіть платформу. Використовуйте платформи, які спеціалізуються на створенні та продажі NFT-квитків (наприклад, YellowHeart, GUTS Tickets).
- Налаштуйте криптогаманець. Заведіть гаманець, наприклад MetaMask, для зберігання квитків.
- Купуйте квиток. Придбайте NFT-квиток через маркетплейс або офіційний сайт події.
- Використовуйте квиток. Під час події покажіть ваш квиток через додаток гаманця.
Майбутнє NFT-квитків
NFT-квитки відкривають нові можливості для організаторів та учасників подій. У майбутньому можна очікувати:
- Інтеграції зі смарт-містами: NFT-квитки можуть бути використані для громадського транспорту чи доступу до культурних заходів.
- Гейміфікації: Учасники можуть отримувати винагороди за відвідування подій.
- Соціального впливу: Квитки можуть слугувати доказом участі в благодійних акціях чи екологічних ініціативах.
Висновок
Proof-of-Event і NFT-квитки — це майбутнє подій у Web3. Вони обіцяють зробити взаємодію між організаторами та учасниками більш прозорою, захопливою та взаємовигідною. Хоча ця технологія ще перебуває на ранніх етапах розвитку, вона вже змінює підхід до організації подій і формує нову еру цифрової взаємодії.
Що таке DeFi і як це працює?

DeFi (децентралізовані фінанси) — це революційна концепція у світі фінансів, яка використовує блокчейн-технології для створення фінансових послуг без посередників, таких як банки або брокери. DeFi дозволяє кожному мати доступ до фінансових інструментів через Інтернет, незалежно від місця проживання чи соціального статусу.
Основні принципи DeFi
Децентралізовані фінанси працюють на основі таких ключових принципів:
- Відкритість. Усі транзакції та операції в DeFi є прозорими, оскільки записуються у блокчейні.
- Децентралізація. Відсутність центрального управління; мережі працюють на смарт-контрактах.
- Доступність. Кожен із підключенням до Інтернету може використовувати DeFi-сервіси.
- Програмованість. Смарт-контракти дозволяють створювати автоматизовані фінансові продукти.
Як працює DeFi
DeFi будується на основі блокчейнів, таких як Ethereum, Binance Smart Chain або Solana. Ці блокчейни дозволяють створювати смарт-контракти — програми, які автоматично виконують умови угод без потреби в людському втручанні.
Ключові компоненти DeFi
- Смарт-контракти: Це самовиконувані програми, які автоматизують операції. Наприклад, контракт може автоматично перерахувати гроші після виконання певних умов.
- Протоколи DeFi: Це стандартизовані набори правил, які визначають, як функціонуватимуть фінансові сервіси. Наприклад, протоколи для кредитування, обміну активів або створення стабільних монет (stablecoins).
- Децентралізовані додатки (dApps): Користувачі взаємодіють із DeFi через dApps, такі як Uniswap (додаток для обміну криптовалют) чи Aave (платформа для кредитування).
- Токени: У DeFi використовуються різні види токенів:
- Utility-токени для доступу до сервісів,
- Stablecoins (наприклад, USDT, DAI) для зниження волатильності,
- Governance-токени для голосування в протоколах.
Приклад роботи DeFi
Уявіть, що ви хочете отримати кредит. У традиційній системі вам потрібно звернутися до банку, пройти кредитну перевірку, подати документи та сплатити комісії. У DeFi ви можете використати свій криптоактив як заставу (наприклад, Ethereum) і автоматично отримати стабільну монету (наприклад, DAI) як кредит через смарт-контракт. Процес повністю децентралізований і виконується миттєво.
Популярні сервіси DeFi
- Uniswap: Децентралізована біржа (DEX), яка дозволяє обмінювати токени без посередників.
- Aave: Платформа для кредитування та позик без банків.
- MakerDAO: Система для створення стабільної монети DAI.
- Curve Finance: Платформа для обміну стабільних монет із мінімальною комісією.
- Compound: Протокол для заробітку відсотків на криптовалюті.
Переваги DeFi
- Відсутність посередників. Ви керуєте своїми коштами напряму.
- Глобальна доступність. Неважливо, де ви знаходитесь — доступ є всюди.
- Швидкість. Транзакції виконуються значно швидше, ніж у традиційній системі.
- Низькі комісії. Відсутність банків та інших посередників зменшує витрати.
Ризики DeFi
- Технічні проблеми: Помилки у смарт-контрактах можуть призвести до втрати коштів.
- Волатильність: Криптовалюти часто мають нестабільну ціну.
- Відсутність регуляції: У разі проблем користувач не може звернутися до регуляторних органів.
- Зломи: Децентралізовані платформи є ціллю для хакерів.
Як почати користуватися DeFi
- Заведіть криптогаманець. Найпопулярнішими є MetaMask, Trust Wallet.
- Купіть криптовалюту. Придбайте токени, які підтримуються платформою (наприклад, ETH).
- Підключіться до dApp. Використовуйте гаманець для доступу до DeFi-додатків.
- Починайте взаємодію. Наприклад, обмінюйте токени, додавайте ліквідність або беріть кредити.
Майбутнє DeFi
DeFi змінює уявлення про фінанси, роблячи їх доступними для кожного. У майбутньому можна очікувати:
- Більшої інтеграції з традиційними фінансами,
- Розвитку регуляторних рамок,
- Нових інновацій, таких як страхування, ігри чи NFT, засновані на DeFi.
Висновок
DeFi — це крок до фінансової незалежності, де кожен користувач отримує повний контроль над своїми коштами. Хоча ця технологія ще розвивається і має певні ризики, вона вже показує потенціал для трансформації фінансової системи у глобальному масштабі.
Редюсери та екстраредюсери в Redux: Як вони працюють і в чому різниця
Redux — це популярна бібліотека для управління станом у JavaScript-додатках, особливо в React. У центрі роботи Redux стоїть концепція редюсерів. Сьогодні ми розглянемо, що таке редюсери та екстраредюсери, як вони працюють і чим відрізняються, а також подивимося приклади використання.
Що таке редюсер?
Редюсер (reducer) — це функція, яка визначає, як змінюється стан додатка у відповідь на дії (actions). Редюсери є чистими функціями: вони приймають поточний стан та дію і повертають новий стан.
Приклад редюсера:
const initialState = { count: 0 };
function counterReducer(state = initialState, action) {
switch (action.type) {
case 'INCREMENT':
return { ...state, count: state.count + 1 };
case 'DECREMENT':
return { ...state, count: state.count - 1 };
default:
return state;
}
}
Ключові принципи редюсера:
- Чистота функції. Редюсер не має побічних ефектів.
- Незмінність стану. Стан не змінюється напряму, а створюється новий об’єкт із внесеними змінами.
- Детермінізм. Вхідні дані завжди дають однаковий результат.
Що таке екстраредюсер?
Екстраредюсер (extra reducer) — це концепція, яка використовується в Redux Toolkit, сучасному наборі інструментів для роботи з Redux. Екстраредюсери дозволяють обробляти дії, які визначені поза межами конкретного слайсу (slice).
Основна ідея екстраредюсерів
Звичайні редюсери пов’язані з діями, що створюються у межах одного слайсу. Екстраредюсери дозволяють обробляти:
- дії з інших слайсів,
- глобальні дії,
- асинхронні дії, створені за допомогою
createAsyncThunk.
Приклад екстраредюсерів:
import { createSlice, createAsyncThunk } from '@reduxjs/toolkit';
// Асинхронна дія
export const fetchUser = createAsyncThunk('user/fetchUser', async (userId) => {
const response = await fetch(`/api/users/${userId}`);
return response.json();
});
const userSlice = createSlice({
name: 'user',
initialState: { user: null, status: 'idle' },
reducers: {},
extraReducers: (builder) => {
builder
.addCase(fetchUser.pending, (state) => {
state.status = 'loading';
})
.addCase(fetchUser.fulfilled, (state, action) => {
state.status = 'succeeded';
state.user = action.payload;
})
.addCase(fetchUser.rejected, (state) => {
state.status = 'failed';
});
},
});
export default userSlice.reducer;
У цьому прикладі екстраредюсери обробляють асинхронні дії, створені через createAsyncThunk.
В чому різниця між редюсерами та екстраредюсерами?
| Характеристика |
Редюсер |
Екстраредюсер |
| Зв’язок із діями |
Обробляє дії, визначені в тому ж слайсі |
Обробляє дії з інших слайсів чи глобальні |
| Декларативність |
Визначається через об’єкт у reducers |
Визначається через метод builder |
| Основне використання |
Простий стан і синхронні дії |
Асинхронні дії чи складна логіка |
Коли використовувати екстраредюсери?
- Асинхронні операції. Якщо ваш додаток виконує асинхронні запити (наприклад, до API), екстраредюсери ідеально підходять для обробки різних станів (loading, succeeded, failed).
- Спільні дії. Коли кілька слайсів мають реагувати на одну й ту саму дію.
- Глобальні дії. Обробка подій, які не пов’язані з конкретним слайсом.
Як створити редюсер з екстраредюсерами
Крок 1: Створіть асинхронну дію (за потреби):
export const fetchPosts = createAsyncThunk('posts/fetchPosts', async () => {
const response = await fetch('/api/posts');
return response.json();
});
Крок 2: Створіть слайс із екстраредюсерами:
const postsSlice = createSlice({
name: 'posts',
initialState: { items: [], status: 'idle' },
reducers: {},
extraReducers: (builder) => {
builder
.addCase(fetchPosts.pending, (state) => {
state.status = 'loading';
})
.addCase(fetchPosts.fulfilled, (state, action) => {
state.status = 'succeeded';
state.items = action.payload;
})
.addCase(fetchPosts.rejected, (state) => {
state.status = 'failed';
});
},
});
export default postsSlice.reducer;
Висновок
Редюсери та екстраредюсери — це ключові інструменти для управління станом у Redux. Редюсери обробляють синхронні та локальні дії, тоді як екстраредюсери дозволяють розширювати логіку, обробляючи асинхронні або глобальні дії. Використовуючи ці підходи, можна створювати масштабовані та добре організовані додатки.
Як працювати з Chart.js: Посібник для початківців
Chart.js — це популярна бібліотека для створення інтерактивних графіків і діаграм на веб-сторінках. Вона проста у використанні, підтримує різні типи графіків та дозволяє налаштовувати їх під ваші потреби.
Встановлення Chart.js
Для початку потрібно встановити бібліотеку Chart.js. Це можна зробити кількома способами:
- Підключення через CDN Найшвидший спосіб почати роботу з Chart.js — це використати Content Delivery Network (CDN). Додайте наступний рядок у секцію
<head> вашого HTML-документу:
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
- Встановлення через npm Якщо ви працюєте з Node.js, встановіть Chart.js за допомогою npm:
npm install chart.js
- Завантаження файлів Ви також можете завантажити бібліотеку з офіційного сайту Chart.js і підключити її локально.
Створення графіка
Щоб створити графік, вам потрібен HTML-елемент <canvas> і JavaScript-код для ініціалізації Chart.js. Ось базовий приклад:
HTML
<canvas id="myChart" width="400" height="200"></canvas>
JavaScript
const ctx = document.getElementById('myChart').getContext('2d');
const myChart = new Chart(ctx, {
type: 'bar', // Тип графіка
data: {
labels: ['Red', 'Blue', 'Yellow', 'Green', 'Purple', 'Orange'], // Підписи для осі X
datasets: [{
label: 'Кількість голосів',
data: [12, 19, 3, 5, 2, 3], // Дані для графіка
backgroundColor: [
'rgba(255, 99, 132, 0.2)',
'rgba(54, 162, 235, 0.2)',
'rgba(255, 206, 86, 0.2)',
'rgba(75, 192, 192, 0.2)',
'rgba(153, 102, 255, 0.2)',
'rgba(255, 159, 64, 0.2)'
],
borderColor: [
'rgba(255, 99, 132, 1)',
'rgba(54, 162, 235, 1)',
'rgba(255, 206, 86, 1)',
'rgba(75, 192, 192, 1)',
'rgba(153, 102, 255, 1)',
'rgba(255, 159, 64, 1)'
],
borderWidth: 1
}]
},
options: {
scales: {
y: {
beginAtZero: true
}
}
}
});
Результат буде виглядати як стовпчиковий графік з різнокольоровими стовпчиками.
Налаштування графіка
Chart.js дозволяє гнучко налаштовувати графіки. Ось декілька ключових параметрів:
- Типи графіків Chart.js підтримує такі типи графіків:
- Стовпчиковий (
bar)
- Лінійний (
line)
- Кругова діаграма (
pie)
- Радіальна діаграма (
radar)
- Схема розсіювання (
scatter)
Щоб змінити тип графіка, просто змініть значення type.
- Теми та стилі Ви можете змінювати кольори, шрифти та розміри елементів графіка через об’єкт
options. Наприклад:
options: {
plugins: {
legend: {
display: true,
position: 'top'
}
}
}
- Анімація Chart.js підтримує анімацію для графіків. Ви можете налаштувати тривалість і ефекти через параметри
animation.
Додавання інтерактивності
Chart.js дозволяє робити графіки інтерактивними. Наприклад, ви можете додати події, які реагують на натискання на графік:
const myChart = new Chart(ctx, {
type: 'bar',
data: {...},
options: {
onClick: (event, elements) => {
if (elements.length > 0) {
const index = elements[0].index;
alert(`Ви натиснули на ${myChart.data.labels[index]}`);
}
}
}
});
Висновок
Chart.js — це потужний інструмент для створення красивих та функціональних графіків. Завдяки простому інтерфейсу та широким можливостям налаштування, ця бібліотека підійде як новачкам, так і досвідченим розробникам.
Щоб дізнатися більше, відвідайте документацію Chart.js.
Парольний захист статичної HTML-сторінки на JS
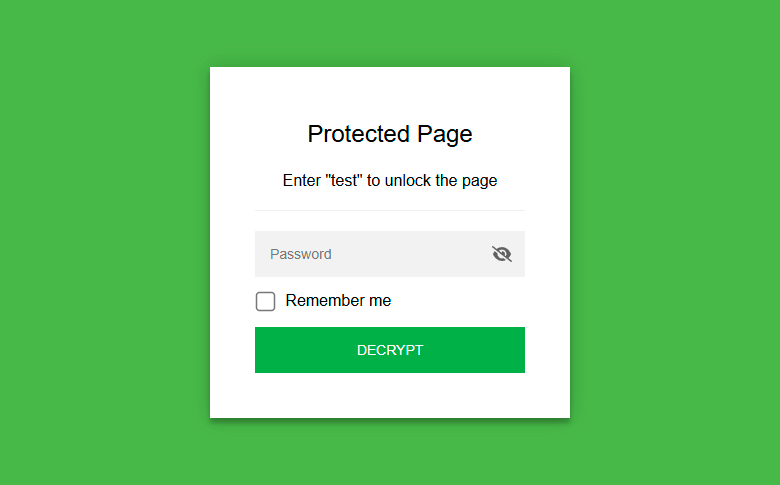
Зазвичай парольний захист здійснюється через веб-сервер, який.htaccess перевіряє пароль і видає контент. та Portable Secret. Для шифрування HTML перед публікацією StatiCrypt використовує AES-256 та WebCrypto, а розшифровка відбувається за допомогою введення пароля в браузері на стороні клієнта, як показано в демо (пароль test ).htpasswd
Сторінка буде розшифрована у браузері відвідувача, коли той запровадить відомий йому пароль. В принципі, цю систему можна використовувати для шифрування особистих нотаток, якщо ви хочете викласти їх на загальнодоступний сервер, щоб завжди мати доступ до них, але при цьому надійно захистити від сторонніх очей.
Розшифровка відбувається на звичайному JavaScript, тобто з боку клієнта не потрібно завантажувати та встановити додаткові інструменти, крім стандартного браузера. Ні хостинг-провайдер, ні інтернет-провайдер не отримують доступу до цієї інформації в процесі розшифровки її розширювання в браузері.
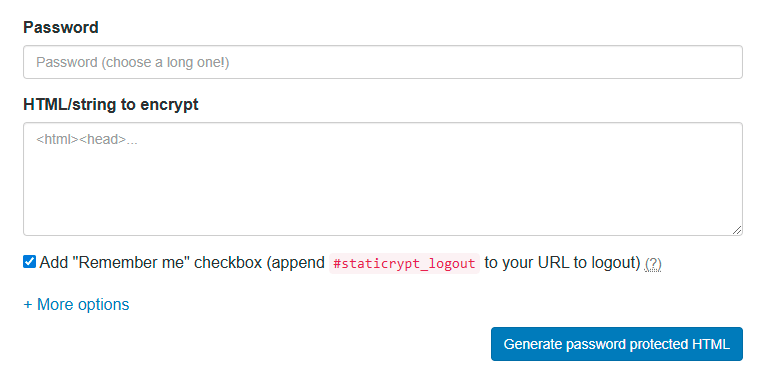
Перевірити шифрування можна на веб-версії StatiCrypt . Зверху поля для вихідного HTML та пароля:
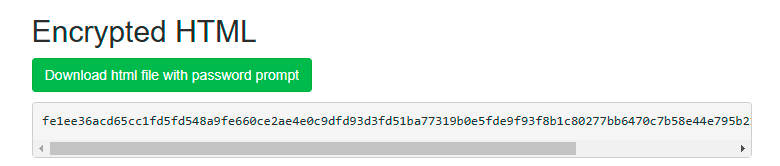
Знизу – результат із зашифрованим HTML:
Консольна утиліта StatiCrypt доступна для скачування на Github , а також у вигляді пакета NPM . У консольній програмі налаштування інтерфейсу для поля введення пароля здійснюється зміною шаблону lib/password_template.htmlв комплекті утиліти із зазначенням потім шляху до шаблону через прапор -t path/to/my/file.html. Важливо лише не змінювати фрагмент шифрування у цьому шаблоні, у тому числі формат змінних /*[|variable|]*/0із обов’язковим нулем на кінці.
Існує готовий шаблон для створення та хостингу односторінкового зашифрованого сайту на GitHub Pages.
За замовчуванням поле введення пароля містить прапорець “Запам’ятати мене” (Remember me). У цьому випадку пароль зберігається в localStorage (в хешованому вигляді з сіллю). Знову ж таки за замовчуванням немає терміну зберігання пароля. Для вимкнення цієї опції при генерації сторінки з консолі можна використовувати прапор --remember false. Термін зберігання днями вказує опція --remember NUMBER_OF_DAYS.
Сторінка шифрується за допомогою AES-256 у режимі CBC, який у контексті StatiCrypt позбавлений характерних для нього вразливостей. Пароль хешується за допомогою функції PBKDF2: 599 тис. операцій хешування SHA-256 і 1000 операцій SHA-1 ( для легаси ), що становить рекомендоване значення 600 тис. операцій.
По суті, генерується нова веб-сторінка (зашифрована), яка містить вміст старої.
Для найкращої безпеки рекомендується використовувати паролі довжиною понад 16 символів (літери, цифри, спецсимволи) та менеджер паролів. Наприклад, опенсорсний Bitwarden. Хоча AES-256 вважається надійним сучасним шифром, але для кращого захисту від брутфорсу краще використовувати паролі якомога більшої довжини.
Утиліта також вміє генерувати посилання, яке вже містить пароль, що хешує, для доступу до сторінки без введення пароля безпосередньо у веб-формі браузера. Таке посилання можна передавати довіреним особам або використовувати самому, а контент при цьому зберігається на сервері у зашифрованому вигляді, недоступному для перегляду ні хостером, ні третіми особами.
Схожий проект, але для шифрування файлів – Portable Secret . Його можна використовувати для шифрування конфіденційних файлів, які зберігаються в небезпечному місці: на USB-флешці, хмарному хостингу, на веб-сайті тощо. буд. А також для шифрування файлів перед відправкою по відкритому каналу: поштою або месенджером. В принципі це сучасна зручна альтернатива PGP. Є веб-демо для шифрування у браузері (в офлайні).
Джерело
Що таке підписи Шнорра і як вони використовуються в біткоїні?
Що таке Шнорра?
Підписи Шнорра ― схема цифрових підписів, запропонована 1991 року німецьким криптографом Клаусом Петером Шнорром.
У 2020 році вона включена в BIP-340 як альтернативу Elliptic Curves Digital Signature Algorithm (ECDSA). Пропозиція імплементована у мережі біткоїну у листопаді 2021 року.
Що таке цифровий підпис?
Цифровий підпис – це математична схема для перевірки двох ключових характеристик цифрового повідомлення: автентичності (надіслано конкретним користувачем) і цілісності (не змінювалося в процесі передачі).
За допомогою цифрових підписів протокол біткоїну підтверджує прив’язку закритого ключа до конкретної публічної адреси. Сатоші Накамото підкреслив їхню важливість у white paper першої криптовалюти:
«Визначимо електронну монету як послідовність цифрових підписів. Черговий власник надсилає монету наступному, підписуючи хеш попередньої транзакції та публічний ключ майбутнього власника та приєднуючи цю інформацію до монети. Одержувач може перевірити кожен підпис, щоб підтвердити коректність всього ланцюжка власників».
Які цифрові підписи використовуються в біткоїні?
Спочатку перша криптовалюта використовувала тільки ECDSA – алгоритм з відкритим вихідним кодом, який широко застосовувався в 2008 році. Вибір Сатоші Накамото пов’язаний з тим, що на час публікації white paper біткоїну підписи Шнорра не пройшли стандартизацію.
У 2014 році на форумі Bitcointalk заговорили про необхідність впровадження підписів Шнорра в протокол біткоїну, а через шість років Пітер Велле, Йонас Нік та Тім Раффінг стандартизували їх у BIP-340 .
Імплементація підписів Шнорра відбулася 14 листопада 2021 року в рамках оновлення Taproot на висоті блоку # 709632. З тих пір вони використовуються поряд з ECDSA.
Які переваги підписів Шнорра перед ECDSA?
Автори BIP-340 виділяють три основні переваги підписів Шнорра:
- Безпека , що доводиться . Підписи Шнорра неможливо підробити під час атаки за вибраним повідомленням (SUF-CMA) з використанням моделі випадкових оракулів із досить складноюECDLP. Безпека ECDSA ґрунтується на сильніших припущеннях.
- Негнучкість . Підписи Шнорра є доказово негнучкими.
- Лінійність . За допомогою підписів Шнорра кілька сторін, що взаємодіють, можуть створити дійсний підпис для суми своїх відкритих ключів.
Остання перевага дозволяє реалізуватипростішу мультисиг -схему на кшталт Musig2 шляхомагрегації підписів.
«При використанні підпису Шнорра мультисиг-транзакція виглядає як транзакція з одним підписом, що підвищує конфіденційність відправників та ускладнює життя ончейн-аналітикам. Останні не можуть відразу прив’язувати транзакції до однієї людини чи групи людей», – коментують представники біткоін-міксера Mixer.Money .
Вони зазначають, що підписів Шнорра недостатньо для забезпечення анонімності:
«Слабка приватність залишається проблемою біткоїну. Спільнота сприйняла Taproot як оновлення для підвищення конфіденційності, однак єдиною зміною стала неможливість виявлення мультипідпису засобами блокчейн-аналітики. Схема Шнорра не приховає відправника та одержувача монет. Для цього, як і раніше, потрібно використовувати біткоін-міксери або CoinJoin-рішення».
2024 року розробники останніх зіткнулися з безпрецедентним тиском з боку регуляторів. На думку Mixer.Money, воно може призвести до зниження кількості користувачів та негативно позначитися на технології.
Представники сервісу рекомендують звернути увагу на рішення, здатні приховувати факт мікшування монет. Наприклад, у режимі «Повна анонімність» Mixer.Money відправляє користувачеві «чисті» монети з великих бірж, щоб виключити ймовірність отримання своїх активів, або біткоїнів сумнівного походження.
Джерело
Що таке керрі-трейд і як він застосовується на крипторинку?

Що таке керрі-трейд?
Керрі-трейд ( англ. carry trade ) — стратегія, при якій інвестори займаються коштами у валюті з низькою відсотковою ставкою та вкладають їх в активи, номіновані у валюті з більш високою відсотковою ставкою, щоб заробити на цій різниці.
Термін не має загальнопринятого перекладу на російську мову; один із можливих варіантів — «процентний арбітраж».
Як робити керрі-трейд на традиційному ринку?
Один із найвідоміших прикладів керрі-трейд — класична стратегія «єна — долар». Довгі роки інвестори займалися японською національною валютою і вкладали кошти в доларові активи, які пропонували набагато більш високу доходність. Така угода була вигідною, оскільки різниця в процентних ставках залишалася благоприятною, а курс іені внезапно не підскочив по відношенню до долара, що і відбулося в липні 2024 року.
Потенційний прибуток може бути очікуваним, однак такі операції сильно залежать від глобальних ринкових умов і настрою інвесторів. Якщо ситуація ухудшается, прибуткові операції можуть швидко перетворитися в проблемні. Щоб втрати від переоцінки нацвалюють не перевищили відсотковий дохід, потрібно хеджувати ризики.
Ще приклади:
- низькі процентні ставки характерні також для франка (CHF). Інвестори можуть забрати швейцарську валюту та інвестувати її в активи в новозеландських доларах (NZD), де ставки зазвичай вище, що дозволить заробити на їх різницю;
- у євро (EUR) також досить низькі відсоткові ставки, в той час як у Турції вони значно вищі через інфляцію. Інвестори можуть брати валюту ЄС і вкладати її в ліру (TRY), щоб отримати більш високий дохід. Але ця угода спряжена з високим ризиком із-за волатильності TRY.
Приведемо приклад керрі-трейда з одночасним відкриттям довгою та короткою позицією за іене та австралійському долару (AUD).
Шаги:
- інвестор займає іену за низькою відсотковою ставкою — наприклад, 0,1% річних;
- далі конвертує кошти в AUD і вкладає у високодохідні австралійські зобов’язання — скажімо, під 4% річних;
- таким чином, інвестор займає довгу позицію по валютній парі AUD/JPY, щоб заробити на можливому укріпленні австралійського долара за відношенням до ієни;
- щоб хеджувати валютний ризик, одночасно відкривається коротка позиція за ф’ючерами на AUD/JPY на аналогічну суму. Це допомагає зафіксувати поточний обмінний курс і захистити прибуток від валютних коливань.
Результат:
- інвестор заробляє на різницю між доходністю зобов’язань (4%) і вартістю власності в ієнах (0,1%);
- коротка позиція захищає від можливого падіння курсу AUD/JPY.
Як робити керрі-трейд на криптовалютному ринку?
DeFi відкриває користувачам з будь-якої точки світу широкі можливості для максимізації доходу від завантажених криптоактивів. В цьому багатогранному сегменті немає варіантів для реалізації стратегії керрі-трейд.
Приведемо гіпотетичний приклад із наступними вихідними даними:
- криптоактив 1: ABC — прив’язаний до долара США стейблкоїн, ставка по займу — 2% річних;
- криптоактив 2: XYZ — летючий криптоактив із порівняно невеликим обсягом викидів, ставка на DeFi-платформі — 8% річних;
- поточний курс XYZ/ABC: 30 000 (1 XYZ = 30 000 ABC).
Шаги:
- інвестор бере 100 000 ABC під 2% річних на централізованій біржі або через кредитний DeFi-сервіс;
- далі конвертує 100 000 ABC в XYZ за поточним курсом. Отримана сума: 100 000 / 30 000 = 3,33 XYZ;
- інвестор вкладає 3,33 XYZ в DeFi-протокол, який пропонує 8% річних депозитів у відповідному криптоактиві;
- Щоб змінити ризики курсу XYZ, учасник ринку відкриває коротку позицію у фьючерсах або опціонах у парі XYZ/ABC на суму 3,33 XYZ за поточним курсом (30 000 ABC за 1 BTC).
Через рік:
- отриманий від вкладень в XYZ дохід: 3,33 XYZ * 8% = 0,266 XYZ;
- витрати на обслуговування зайнятості в ABC: 100 000 ABC * 2% = 2000 ABC;
- конвертація XYZ навпаки в ABC: якщо курс зберігся на рівні 30 000, інвестор отримує: 3 596 XYZ * 30 000 ABC/XYZ = 107 880 ABC;
- расчеты по фьючерсам (если котировки остались на отметке 30 000): короткая позиція не приносить убитков, так як курс не змінений.
Ітого:
- дохід, виражений в «стабільній монеті»: 0,266 * 30 000 = 7980 ABC;
- чистий прибуток в стейблкоїні: 7980 — 2000 = 5980 ABC.
Таким чином, інвестор за рік отримав майже 6% прибутку на різницю доходності між займом в стейблкоїнах та інвестиціями в волатильному активі XYZ, одночасно мінімізуючи валютні ризики за рахунок хеджування фьючерсами.
Що таке кеш-енд-керрі арбітраж?
Незважаючи на сходство в назвах, існує значуща різниця між керрі-трейд і cash-and-carry арбітражем. Останній являє собою торгову стратегію, при якій трейдери використовують різницю між поточною вартістю активу і ціною фьючерса. Цей підхід полягає в одночасному придбанні інструменту на спотовому ринку та продажі (шорте) продуктивного контракту на цей же актив.
Розглянемо алгоритм докладніше:
- Покупка на спотовому ринку (готівка). Трейдер купує актив на спотовому ринку за поточною ціною — наприклад, біткойн за USDT.
- Шорт фьючерса (нести). Учасник ринку одночасно продає продуктивний контракт на цей же актив, тож укладає зделку на реалізацію BTC у майбутньому за заздалегідь оголошеною ціною.
- Закриття позиції . У момент істечення терміну фьючерса (експірації) трейдер закриває обе позиції. Він продає актив, куплений на спотовому ринку, і використовує його для виконання зобов’язань за контрактом.
Покладіть, що на момент покупки:
- спотова ціна біткойна становить 50 000 USDT;
- істекаючий через місяць ф’ючерс на BTC торгується по 50 200 USDT;
- трейдер купує 1 BTC за 50 000 USDT і одночасно шортить контракт на 1 BTC за ціною 50 200 USDT.
Незалежно від того, як змінилася ціна биткойна, трейдер отримує:
- продаж 1 BTC за ф’ючерсним контрактом за 50 200 USDT;
- повернення початкових інвестицій у розмірі 50 000 USDT;
- итоговая прибыль составляет разницу междуценой фьючерсного контрактаі спотової вартості цифрового золота на даний момент заключення операції, що, наприклад, — 200 USDT.
Така стратегія працює, якщо фьючерс торгується з премією до споту (цена контракту вище базової). Ця ситуація може виникнути із-за переважаючих очікувань раллі-активу, фундаментальних аспектів породження тимчасової вартості грошей, а також із-за ринкових дисбалансів.
Стратегія кеш-енд-керрі арбітражу дозволяє зафіксувати цю різницю як прибуток з мінімальними ризиками. Вона популярна серед хедж-фондів та інституційних інвесторів, так як дозволяє відносно безпечно отримувати доходність у будь-яких ринкових умовах.
Які переваги у керрі-трейд?
Керрі-трейд — одна із самих популярних і ефективних довгострокових стратегій на фінансових ринках, особливо серед професіоналів. Але для максимізації вигоди та зменшення можливих потерь важливо грамотно керувати ризиками — зокрема, за рахунок диверсифікації портфеля.
Створення корзин з декількох активів з різною доходністю дозволяє знизити ймовірність збитків. У разі невдачі з одним фінансовим інструментом інші активи можуть компенсувати втрати, забезпечуючи стабільність портфеля.
Такий підхід активно використовується інвестиційними банками та хедж-фондами. Частним інвесторам ця стратегія також доступна при відповідній адаптації розміру позиції до обсягу капіталу.
Керрі-трейд припускає довгострокове утримання позицій, що робить стратегію привабливою для учасників ринку з низькою толерантністю до ризику і готових до вкладень на довгосрок. Основні переваги включають отримання стабільного процентного доходу від утримуваної валютної пари та потенційний прибуток при благоприятному русі курсу.
Для реалізації керрі-трейд зачастую вибирають активи з найбільшим спрямуванням процентних ставок. Однак при цьому важливо враховувати економічні зміни, які можуть збільшити доходність, а також волатильність ринку. Використання відносно безпечних інструментів знижує ризики, але може також зменшити потенційну віддачу від інвестицій.
Які підводні камені у керрі-трейд?
Яка і люба інвестиційна стратегія керрі-трейд пов’язана з певними ризиками; основной из них — валютный.
Якщо земельний актив внезапно зміцнюється по відношенню до інструменту, в який ви інвестували, прибуток може «іспаритися» або навіть обернутися побитками при поверненні до вихідної валюти.
Хтось із керрі-трейд може показати легкий спосіб заробітку, але стратегія може припускати заморажування капіталу на тривалий час. Це дозволяє трейдеру використовувати потенційно більш прибуткові ринкові можливості.
У випадку з cash-and-carry розниця між ф’ючерсами і спотовими цінами часто буває незначною в порівнянні з розмірами позицій, необхідних для ефективної реалізації стратегії. Це призводить до ще більшого заморожування капіталу, щоб використання стратегії стало целесообразным.
Трейдери можуть знизити обсяг необхідного капіталу для використання cash-and-carry, застосовуючи кредитне плечо на ф’ючерсну частину операції. Но нужно учитывать риски, пов’язані з левериджем. Наприклад, якщо із-за коливань ринку позиція ліквідується, трейдер втрачає гроші на зделці, яка значною мірою призначена для усунення спрямованого ризику.
Використання безстрокових свопов супряжено з великими ризиками в порівнянні з фьючерсами. Так, при встановленій даті розрахунків ціна контракту практично завжди прагне до спотової вартості. Со временем спред у безстрокових свопів також повинен сужатися, що дозволяє закрити позиції з прибутком. Однак якщо ринок перейде із стануконтанговбэквордацию, може пройти значний час, перш ніж з’явиться можливість закриття позиції з прибутком. Це призводить до того, що трейдер або пускає інші привабливі опції, або закриває сделку з убитком.
Джерело
Що таке криптовалютні премаркети та як вони працюють?

Що таке премаркети?
У секторі традиційних фінансів премаркети — торговельні сесії, які проводяться до відкриття основного ринку.
Подібні платформи в контексті криптовалют надають можливість трейдингу токенами, які ще не випущені або не розподілені по гаманцях учасників аірдропу. Такі майданчики дають інвесторам можливість робити ставки на майбутню вартість монет, дозволяючи торгувати ними в період між оголошенням про розподіл, фактичним «нарахуванням» токенів та їх офіційним лістингом на біржі.
На відміну від традиційного ринку, криптовалютний працює цілодобово. Премаркети не обмежуються токенами; ними також можна торгувати протокольними балами через різні активності, які у майбутньому можуть стати критерієм отримання аирдропа.
Слід пам’ятати, що торгівля на попередніх ринках є високоспекулятивною, тому завжди проводьте DYOR перед інвестуванням у будь-який проект.
Чому премаркети набирають популярності?
Основна мета сучасних премаркет-платформ – забезпечити надійне та безпечне середовище для проведення угод. До появи подібних майданчиків інвестори вдавалися до неофіційних угод для торгівлі токенами до запуску.
Подібні P2P-системи попереднього трейдингу будувалися виключно на довірі, що пов’язано зі значнимиризиками контрагентаКрім того, трейдери обмежені своїми соціальними зв’язками, що ускладнює пошук зовнішніх партнерів.
Нові премаркет-платформи поєднують покупців і продавців по всьому світу, розширюючи можливості та дозволяючи трейдерам ефективніше оцінювати вартість активів. Зі збільшенням числа учасників покращується ліквідність, що дозволяє купувати та продавати стільки токенів чи балів лояльності, скільки потрібно.
Такі платформи також надають цінну інформацію інвесторам, які планують взаємодіяти з новими активами після їх запуску.
Як працюють премаркети?
На традиційних ринках премаркет-торгівля здійснюється через електронні комунікаційні мережі (ECN), які з’єднують покупців та продавців. Специфіка цих угод відрізняються від тих, що діють у звичайний торговий годинник — насамперед у контексті ліквідності та волатильності. Котирування на премаркеті можуть впливати на ціну відкриття активу, задаючи напрямок торгівлі на день.
Припустимо, компанія публікує квартальні доходи і вони виявляються вищими за очікування. Інвестори можуть передбачити позитивну реакцію ринку та почати купувати акції на премаркеті. Це збільшує попит на фінансові інструменти і надає палива зростання цін ще до відкриття звичайної торгової сесії.
Премаркети працюють за аналогією зі звичайними P2P-платформами, але з ключовою відмінністю: вони утримують кошти обох сторін до виконання умов угоди CEX цю роль виконують зберігачі.
На премаркетах трейдери можуть створювати чи виконувати вже існуючі ордери (накази) — на купівлю чи продаж. Для створення наказу трейдер вказує ціну та кількість активу, яку він хоче придбати чи реалізувати за певною вартістю.
При створенні ордера продаж може знадобитися внесення застави, який утримується до завершення угоди. У разі невиконання ордера продавець ризикує втратити всю заставу або її частину. Премаркет-платформа зазвичай встановлює термін виконання угоди, протягом якого продавець зобов’язаний надати обіцяний актив. В іншому випадку застосовуються штрафні санкції.
Покупці зобов’язані сплатити повну вартість токена під час виконання існуючого ордера чи створення нового. При цьому кошти утримуються доти, доки продавець не надасть актив.
Децентралізовані премаркети використовують смарт-контракти для управління збереженням застав продавців, платежів покупців та вивільненням активів обом сторонам при завершенні угоди. На централізованих майданчиках ці функції виконує сама платформа, виступаючи як третя сторона.
Які основні типи премаркетів?
Премаркети можна класифікувати на два основні типи – платформи пре-TGEта ринки балів .
У першому випадку трейдери можуть торгувати токенами проекту до їхнього розподілу чи лістингу на біржах. Пре-TGE – найпопулярніші премаркети в криптопросторі, де значна частина монет розподіляється за допомогою аірдропів.
Продавцями на таких платформах зазвичай є реципієнти роздач або одержувачі алокацій на передпродажі; покупці – інвестори, які намагаються отримати прибуток від високоризикових активів.
Будь-який може стати продавцем, якщо він здатний надати заявлену кількість токенів до закінчення часу розрахунків. Пре-TGE демонструють значне зростання кількості користувачів та інших метрик, оскільки ця ідея продовжує залучати криптоінвесторів.
Системи торгівлі балами також набирають популярність. Проекти нараховують поінти користувачам за їхню активність на платформах.
Ринки балів мають схожу архітектуру з платформами пре-TGE, також припускаючи тимчасове зберігання активів до завершення торгової угоди або закінчення розрахункового періоду.
Крім того, премаркети бувають:
Що таке Whales Market?
Це один із найпопулярніших премаркетів. Децентралізована платформа надає можливість торгівлі пре-TGE-токенами та балами.
Спочатку підтримуючи тільки Solana, розробники Whales Market поступово інтегрували інші популярні мережі: Ethereum, BNB Chain, Base, StarkNet, Manta Network, Linea, Arbitrum та Merlin Chain.
Згідно з Dune Analytics, загальна кількість користувачів платформи перевищує 30 000; обсяг торгів – понад $137 млн, а сума депонованих коштів – ~$75 млн.
Whales Market використовує смарт-контракти для проведення попередніх та позабіржових угод. Розробники заявляють, що її основним завданням є забезпечення максимально безпечного середовища для проведення P2P-операцій з токенами до запуску, балами та звичайнимиOTC-свопами. За їх словами, смарт-контракт усуває необхідність у третій стороні та/або централізованому кастодіані, а всі процеси автоматизовані та permissionless.
З моменту запуску Whales Market успішно провела попередні торги для низки відомих проектів на зразок StarkNet, Wormhole та Aevo.
У розділі Pre-market трейдери можуть створювати та виконувати ордери на токени до їхнього офіційного запуску.
На стороні покупця працює механізм зберігання коштів та передачі відповідних активів після їх постачання продавцем.
Кошти обох сторін блокуються до виконання умов угоди. Якщо продавець не постачає актив, покупець може претендувати на певну частину застави продавця.
Такий механізм забезпечує безпеку та прозорість угод, мінімізуючи ризики для учасників. Використання смарт-контрактів дозволяє автоматизувати процес, за винятком необхідності довіри між сторонами.
На Whales Market доступна торгівля балами проектів на кшталт Swell, Grass, deBridge та Linea. Користувачі можуть робити ставки на поінти цих та інших проектів до їх конвертації у повноцінні токени.
Механізм роботи Points Market схожий на Pre-Market, проте має ключову відмінність: продавець може отримати оплату за поїнти тільки після їх перетворення на повноцінні криптоактиви. Якщо проект не здійснює конвертацію, угода автоматично скасовується, а кошти повертаються покупцю.
Умовні контракти Points Market розглядають перетворення поінтів на токени як імовірнісна подія до офіційного оголошення проекту. Кошти обох сторін блокуються та утримуються до виконання заданих умов.
Які переваги та недоліки у премаркет-платформ?
Плюси премаркетів:
- подібні платформи сприяють попередньому визначенню цін, дозволяючи оцінити вплив різних факторів на ринки, що зароджуються. Трейдери можуть аналізувати коливання котирувань та передбачати потенційні тренди перед TGE;
- дозволяють інвесторам отримувати доступ до токенів перспективних проектів на ранніх стадіях, що може принести значний потенційний прибуток;
- використання смарт-контрактів усуває необхідність у довірі до третіх сторін та знижує ризик шахрайства. Автоматизація процесів забезпечує безпеку та прозорість угод;
- відсутність центрального органу управління (у разі децентралізованих платформ) дає користувачам можливість безпосередньо взаємодіяти один з одним, що знижує ризик цензури та маніпуляцій;
- платформи дозволяють швидко та ефективно проводити операції, усуваючи затримки, характерні для традиційних фінансових ринків;
- глобальний доступ: будь-який користувач з доступом до Інтернету може брати участь у торгах.
Недоліки премаркетів:
- інвестування у ранні проекти завжди пов’язане з високим ступенем невизначеності та значними ризиками, аж до повної втрати вкладених коштів;
- торгові інструменти премаркетів набагато менш ліквідні, порівняно зі звичними криптоактивами. Це ускладнює їхній швидкий продаж або обмін на інші монети. Крім того, волатильні цінові рухи не завжди точно відображають об’єктивну ситуацію і тому здатні вводити учасників в оману;
- відсутність регуляторного контролю загрожує безліччю шахрайських схем, що вимагає від користувачів особливої пильності та обережності;
- можливі вразливості та помилки в коді смарт-контрактів можуть призвести до втрати активів.
Джерело
Що таке гомоморфне шифрування (FHE)?

Які існують методи шифрування даних у Web2 та Web3?
Люди стикаються із захистом даних у побутових та службових ситуаціях. Процес шифрування відбувається автоматизовано і настількишвидко, що багато його не помічають. Інтерфейс всього на кілька секунд видає значок замка в рядку веб-браузера або умови безпеки інтернет-банкінгу.
Більшість видів шифрування покликане забезпечити прості потреби людей – збереження особистих даних на різних пристроях. Найбільш популярні рішення:
- AES (Advanced Encryption Standard). Використовує один ключ для шифрування та дешифрування. Застосовується для захисту даних у смартфонах, комп’ютерах, хмарних сервісах, банківських системах, VPN та Wi-Fi (WPA2/WPA3);
- RSA (Rivest, Shamir, Adleman). Асиметричний алгоритм шифрування з використанням пари ключів – відкритого (публічного) для пакування даних та закритого (приватного) для розпакування. Метод застосовується в електронних підписах, електронних службах, інтернет-браузерах, протоколі HTTPS для встановлення захищеного з’єднання через SSL/TLS;
- TLS (Transport Layer Security). Рішення захищає з’єднання між клієнтом і сервером подібно до попередніх, але використовує комбінацію симетричних та асиметричних методів: RSA – для обміну ключами, AES – для шифрування даних;
- End-to-End Encryption (E2EE). Цей метод наскрізного шифрування використовують у месенджерах WhatsApp, Signal, Telegram. Протокол захищає дані від прослуховування на серверах, через які вони проходять, а також застосовується у деяких поштових сервісах та відеоконференціях;
- SHA (Secure Hash Algorithm). Сімейство криптографічних хеш-функцій для створення цифрових підписів і забезпечення цілісності даних.
- ECC (Elliptic Curve Cryptography). Застосовується для шифрування даних у мобільних пристроях, захищених інтернет-з’єднаннях, криптовалютах. Протокол використовує математику еліптичних кривих створення маленьких, але надійних ключів шифрування. Імплементація ECDSA обрана Сатоші Накамото при створенні біткоїну у 2008 році. У 2021 році в оновленні Taproot додані прогресивніші підписи Шнорра. Вони підвищили рівень безпеки та дозволили реалізувати спрощену схему мультипідписів. Але не впоралися з бажаною анонімністю – відправники та одержувачі монет залишилися під наглядом аналітиків.
Що таке Fully Homomorphic Encryption (FHE) – повністю гомоморфне шифрування?
Переваги технології блокчейн у децентралізації та прозорості , але один з найбільших недоліків – низький рівень анонімності .
В останні роки набирає популярності технологія ZKP, що виключає необхідність передачі даних третій стороні. Стартапи zkSync, Polygon zkEVM, Scroll, StarkWare не тільки вирішують завдання масштабованості блокчейнів, але і допомагають приховати особистість користувача.
Ще одним способом підвищити анонімність та збереження даних є гомоморфне шифрування. Вперше воно було запропоновано в 1978 авторами алгоритму RSA і дозволяє виконувати математичні операції над даними, не розшифровуючи їх.
Існує кілька видів гомоморфного шифрування, які різняться за ступенем підтримуваних операцій та обчислювальних можливостей:
- частково гомоморфне шифрування (PHE). Дозволяє виконувати лише одну математичну операцію над зашифрованими даними – додавання чи множення. В алгоритмах RSA та Ель-Гамаля – лише множення, у криптосистемі Паскаля Пейє – додавання;
- частково (трохи) гомоморфне шифрування (SWHE). Підтримує обмежену кількість додавань та множень, перш ніж зашифрований текст стає надто «шумним» і загрожує спотвореному результату. SWHE був основою першої реалізацій FHE;
- повністю гомоморфне шифрування (FHE). Найбільш потужна форма, яка підтримує виконання довільного числа додавань та множень над зашифрованими даними.
Наприклад, Аліса хоче передати Бобу інформацію з рецептом новорічної страви разом із купленими продуктами. Для цього вона приваблює третю сторону та наймає кур’єра Джона. Вона шифрує сімейний рецепт, залишаючи лише список продуктів. Аліса використовує приватний ключ, а алгоритм множить та підсумовує дані, додаючи «шум». Джон виконує закупівлю та доставляє продукти разом із рецептом Бобу. Він, знаючи ключ, розшифровує дані FHE-алгоритмом – зворотними математичними операціями.
Повністю гомоморфне шифрування дозволяє приховати те, що передається чи обробляється. У цьому його головна відмінність від ZKP, де фокус зміщений на анонімність того, хто володіє даними та виконує операцію – особи користувача.
У 2020 році співзасновник Ethereum Віталік Бутерін опублікував роботу про застосування FHE у блокчейні.
«Цілком гомоморфне шифрування довгий час вважалося одним зі святих Граалей криптографії. Його потенціал вражає: це тип шифрування, який дозволяє третій стороні виконувати обчислення над зашифрованими даними та отримувати зашифрований результат, який можна передати назад тому, хто має ключ для розшифрування вихідних даних, при цьому третя сторона не може розшифрувати ні дані, ні результат». , – Описав технологію Бутерін.
Як розвивалося повністю гомоморфне шифрування?
В 1982 Шафі Гольдвассер і Сільвіо Мікалі запропонували систему шифрування, гомоморфну щодо множення і здатну зашифрувати всього один біт. Удосконалену систему зі схожими принципами представив у 1999 році Паскаль Пейє.
Схеми шифрування RSA та Ель-Гамаля були ранніми представниками PHE та обмежувалися виконанням одного типу операції, недостатнього для вирішення складних завдань. У 2005 році криптосистема Боне-Го-Нісіма (BGN)стала першою, що дозволяє виконувати необмежену кількість операцій складання та однієї операції множення.
У 2009 році аспірант Стендфордського університету та стажер IBM Крейг Джентрі запропонував систему FHE. Вона може використовуватися для забезпечення конфіденційності даних за будь-яких видів їх обробки в недовірених середовищах — хмарних або розподілених обчисленнях.
FHE-схема Джентрі заснована на теорії ґрат і вводить поняття «шуму», яке поступово збільшується з кожною операцією. Криптограф вирішив завдання процесомбутстрапінгу(початкового завантаження) — часткове розшифрування та повторне шифрування. Ця новаторська конструкція мала надмірно високу обчислювальну вартість та гальмувала досвідчені моделі.
У 2011 році криптографи запропонували спрощену FHE-схему на основі проблеми навчання з помилками (LWE) та кільцевою версією – Ring-LWE. Підхід Бракерськи-Фан-Веркотерена (B/FV) зміг ефективно контролювати зростання «перешкод». За допомогою техніки перемикання модуля збільшується кількість операцій, які можна виконати без перезавантаження. Ці досягнення підвищили ефективність у конкретних сценаріях застосування.
Як FHE застосовують у Web3?
FHE має потенціал для хмарних обчислень, фінансів, медіа, медицини та інших областей, де важлива конфіденційність даних. У зв’язку з ZKP-рішеннями або окремо шифрування здатне підвищити анонімність інформації користувача в DeFi, DePIN, ІІ з фокусом на блокчейн.
Застосування FHE в Web3:
- багатосторонні обчислення (MPC). Протоколи поділяють обчислення кілька частин, кожна з яких виконується різними вузлами. З використанням FHE-механік, кожна з них може залишатися зашифрованою, забезпечуючи додаткову конфіденційність вихідників;
- захист даних. Зберігання інформації у зашифрованому вигляді у зв’язці зі смарт-контрактами відкриває доступ лише законним користувачам;
- хмарні обчислення. FHE дозволяє передавати зашифровані дані в хмарні послуги для обробки без необхідності розкривати їх провайдеру. Наприклад, надати зашифровану фінансову інформацію бухгалтеру, отримавши закритий звіт;
- захист від максимально видобутої вартості (MEV). MEV-боти шукають транзакції з високою вартістю та надсилають свої до того, як вони будуть оброблені, отримуючи таким чином прибуток. Неможливість аналізу транзакцій за допомогою FHE дозволяє позбавитися атак випередження;
- конфіденційність учасників Web3-галузі. Дозволяє зашифрувати інформацію DeFi-користувачів, валідаторів рестейкінгу, інфраструктурних постачальників DePIN-мереж;
- машинне навчання на зашифровані дані. За допомогою FHE можна довіряти зашифровані дані ІІ. Це стане в нагоді в медицині, де відомості про пацієнтів повинні бути захищені, але можуть використовуватися для тренування машин з метою діагностики захворювань;
- голосування. За допомогою FHE дані можуть бути зашифровані, що зберігає конфіденційність і унеможливлює вплив на результат політичних виборів або голосування в ДАО.
Які компанії запроваджують технологію FHE?
Після релізу схеми Джентрі у 2009 році за експерименти взялися технічні гіганти. Для компаній типу IBM і Google важливо було першими реалізувати захист даних клієнтів хмарних сервісів.
За перше десятиліття багато провідних гравців індустрії надали власні рішення. Вони ґрунтувалися на керуванні ключами доступу та хмарних обчисленнях із FHE-захистом. IBM представила бібліотеку розробки HElib, а потім IBM Guardium Data Encryption – набір сервісів для захисту даних із передовими технологіями, включаючи варіації FHE.
Наприкінці 2022 року Google відкрила доступ до вихідного коду двох інструментів на базі FHE. Технології підвищення конфіденційності (PET) включають сервіс ІІ-блюрингу відео Magritte та FHE Transpiler для розробників. Перша заощаджує час відеоредакторів, допомагаючи розмивати небажаний контент, друга є актуальною у роботі над зашифрованими даними — у фінансовій, державній, медичній сферах.
Як стартапи розвивають FHE у Web3?
Після публікації есе Віталіка Бутеріна про користь FHE розробники почали впроваджувати технологію в мережу Ethereum .
Французька компанія представила повністю гомоморфне EVM -сумісне рішення – fhEVM. Воно дозволяє проводити обчислення над зашифрованими даними, надаючи функції конфіденційності смарт-контрактів та dapps.
Команда Zama вірить, що зможе вплинути на створення нового єдиного стандарту інтернет-з’єднання HTTPZ – постійно зашифрованих даних не тільки в момент їх передачі, а й під час обчислень над ними. У березні 2024 року криптокомпанія закрила раунд фінансування Серії А на суму $73 млн. Його очолили Multicoin Capital, Protocol Labs та Filecoin.
Fhenix спеціалізується на розвитку FHE в блокчейні Ethereum із запозиченою fhEVM від Zama. Компанія у партнерстві з EigenLayer та Celestia створює стек співпроцесорів для зниження обчислювальних витрат FHE-алгоритму.
Іншим напрямком команди Fhenix є створення першого FHE-рішення другого рівня ( L2) . Оптимістичний роллап для Ethereum побудований на базі Arbitrum Stack.
Inco Network — модульна, fhEVM-сумісна мережа, покликана стати стеком конфіденційності для розробників Web3.
28 жовтня 2024 року співемітент стейблокіну USDC компанія Circle у партнерстві з Inco Network представила рішення Confidential ERC-20 Framework, призначене для маскування транзакцій. Воно дозволяє обернути існуючі токени в мережах EVM-сумісних в конфіденційну форму з підтримкою FHE.
Запуск третьої фази тестнета Paillier заплановано на IV квартал 2024 року, старт основної мережі очікується у першій половині 2025 року.
Згідно з аналітичним сервісом CryptoRank, у лютому 2024 року компанія залучила ~$4,5 млн інвестицій у посівному раунді. Його очолили 1kx, Circle та P2 Ventures (Polygon Ventures).
Mind Network є рівень рестейкінгу з використанням FHE в ІІ-мережах і на основі Proof-of-Stake ( PoS ). Він здатний зберігати анонімність валідаторів під час голосування та нарахування прибутку. Mind Network планує також використовувати FHE для конфіденційних міжмережевих транзакцій на основі CCIP від Chainlink .
Які недоліки у FHE?
FHE є багатообіцяючою та потенційно затребуваною технологією з безліччю способів застосування, але і своїми слабкими сторонами:
- Витрати використання. Процес шифрування та дешифрування даних FHE-алгоритмом більш витратний у обчислювальному відношенні, ніж інші способи;
- складність реалізації. На ранній стадії розвитку алгоритми шифрування FHE ще не стандартизовані, розробникам поки що складно реалізувати цей метод для створення dapps;
- обсяг даних. FHE генерують великі масиви інформації, заповнюючи простір у блоках блокчейнів, що може гальмувати роботу та підвищувати комісії у мережах.
Джерело